Meet YaRN: A Compute-Efficient Method to Extend the Context Window of Transformer-based Language Models Requiring 10x Less Tokens and 2.5x Less Training Steps than Previous Methods
Large language models like chat GPT can consider a broader context in the text, enabling them to understand and generate more coherent and contextually relevant responses. This is especially useful in tasks like text completion, where understanding the entire context of a document is crucial.
These models can capture complex relationships and dependencies within a document, even if they span many tokens. Context window extension in the context of large language models like GPT-3 or GPT-4 refers to the span of text or tokens that the model considers when generating or understanding language. This is valuable for tasks like document summarization, where the summary needs to be based on a comprehensive understanding of the document.
Rotary position embedding(RoPE) enhances the models’ ability to handle sequential data and capture positional information within the sequences. However, these models must generalize past the sequence length they were trained on. Researchers at Nous Research, Eleuther AI, and the University of Geneva present YaRN ( Yet another RoPE extension method ) which can compute efficient ways to extend the context window of such models.
RoPE uses complex number rotations, a rotary position embedding that allows the model to effectively encode positional information without relying solely on fixed positional embeddings. This will help the model capture long-range dependencies more accurately. The parameters controlling the rotations are learned during the model’s training process. The model can adaptively adjust the rotations to capture the positional relationships between tokens best.
The method they followed was compressive transformers, which use external memory mechanisms to extend the context window. They store and retrieve information from an external memory bank, allowing them to access context beyond their standard window size. Extensions of the transformer architecture have been developed to include memory components, allowing the model to retain and utilize information from past tokens or examples.
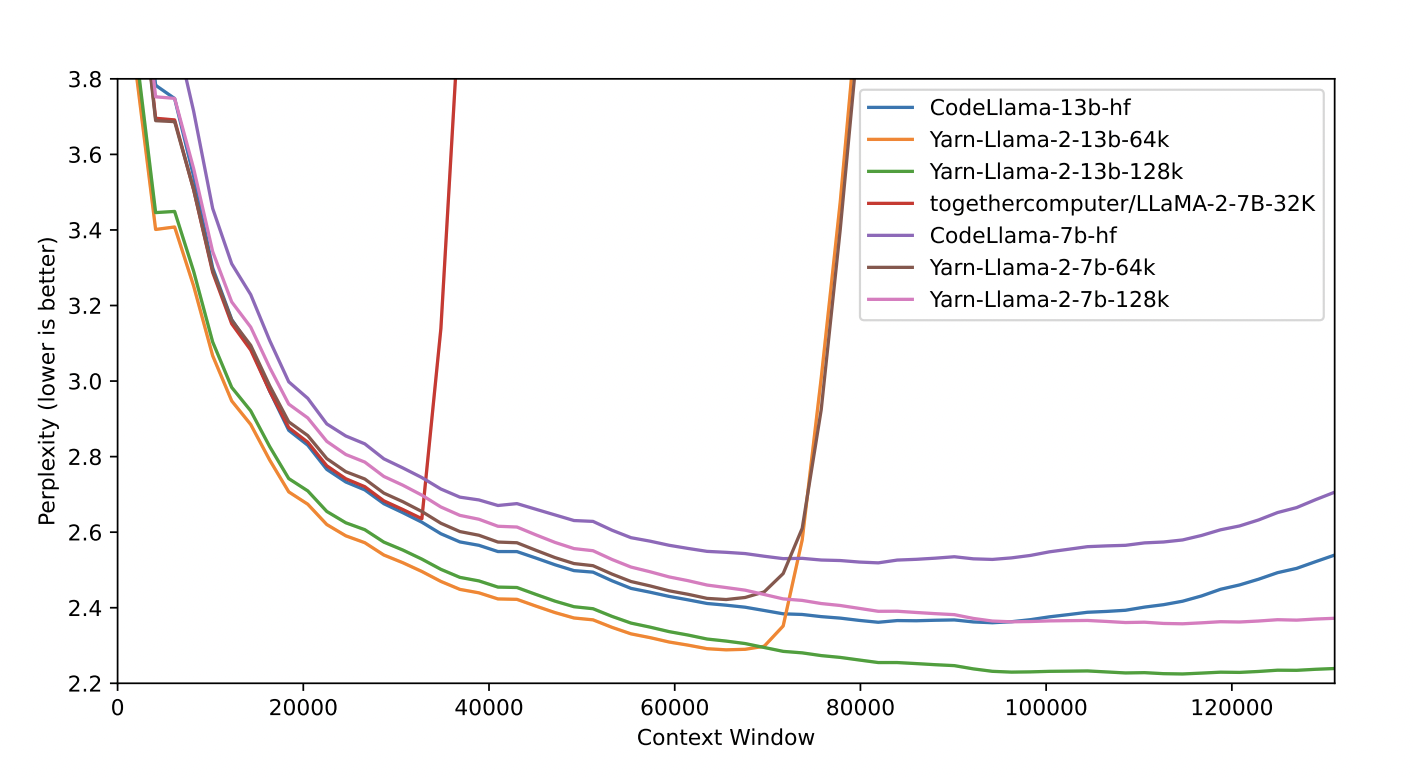
Their experiments show that YaRN successfully achieves context window extension of LLMs with only 400 training steps, which is 0.1% of the model’s original pre-training corpus, a 10x reduction from 25, and a 2.5x reduction in training steps from 7. This makes it highly compute efficient for training with no additional inference costs.
Overall, YaRN improves upon all existing RoPE interpolation methods and replaces PI with no downsides and minimal implementation efforts. The fine-tuned models preserve their original abilities on multiple benchmarks while being able to attend to a very large context size. Future research work can involve memory augmentation, which can be combined with traditional NLP models. A transformer-based model can incorporate external memory banks to store contextually relevant information for downstream tasks like question-answering or machine translation.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.