Meta AI and CMU Researchers Present ‘BANMo’: A New Neural Network-Based Method To Build Animatable 3D Models From Videos
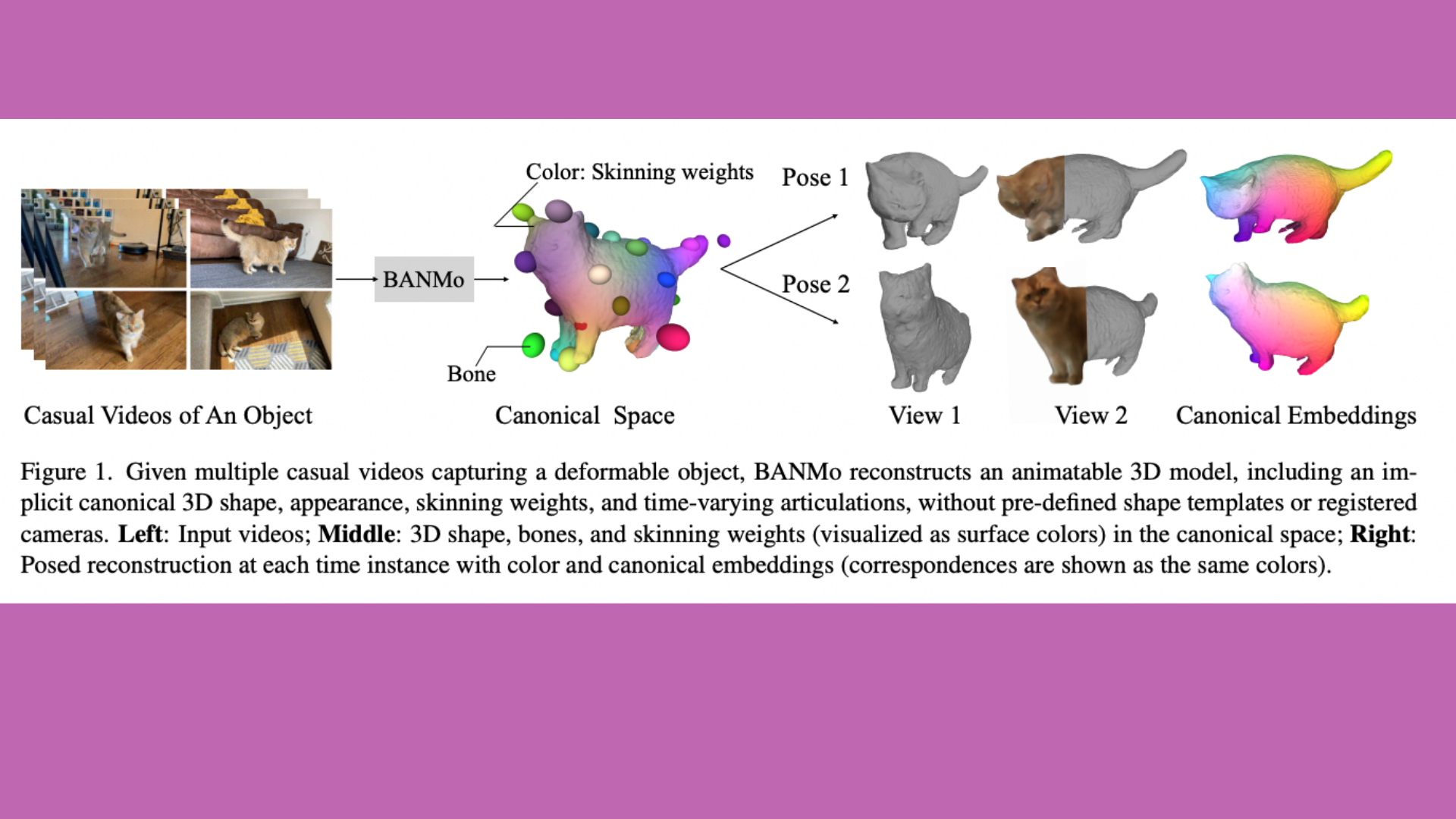
Previous work on articulated 3D shape reconstruction has frequently relied on specialized sensors (e.g., synchronized multi-camera systems) or pre-built 3D deformable models (e.g., SMAL or SMPL). Such approaches cannot scale to a wide range of items in the wild. BANMo is a technique that does not need a specialized sensor or a pre-defined template form. In a differentiable rendering framework, BANMo generates high-fidelity, articulated 3D models (including state and animatable skinning weights) from a large number of monocular casual films. While the usage of several films increases coverage of camera perspectives and object articulations, it introduces significant issues in establishing correlation across scenes with diverse backdrops, lighting conditions, etc.

To help this, developers’ critical insight is to combine three schools of thought:
(1) traditional deformable shape models that use articulated bones and blend skinning,
(2) volumetric neural radiance fields (NeRFs) that can be optimized using gradients, and
(3) canonical embeddings provide correspondences between pixels and an articulated model.
Based on these findings, different neural blend skinning methods were explored that enable differentiable and invertible articulated deformations. When combined with canonical embeddings, such models establish dense correspondences across movies that may be self-supervised with cycle consistency. BANMo can also create realistic photographs from unusual angles and stances.
BANMo reconstructs an animatable 3D model from several casual movies recording a deformable item, including an implicit canonical 3D shape, appearance, skin weights, and time-varying articulations, without pre-defined shape templates or registered cameras. By fine-tuning a generic DensePose before individual occurrences, BANMo writes thousands of unsynchronized video frames to the same canonical space. We achieve fine-grained registration and reconstruction by utilizing implicit neural representation for form, appearance, canonical characteristics, and skinning weights.

BANMo has high empirical performance on actual and synthetic datasets for reconstructing clothed human and quadruped animals and the capacity to recover huge articulations, rebuild fine-geometry, and produce realistic pictures from new views and postures.
Limitations:
1) BANMo relies on a pre-trained DensePose-CSE to enable preliminary root body pose registration. It is currently inapplicable to categories other than humans and quadruped animals. More research is required to expand the technique to arbitrary object types.
2) BANMo, like previous studies in differentiable rendering, necessitates a significant amount of computation, which grows linearly with the number of input photos. The focus is on speeding up the optimization in the future.
Paper: https://arxiv.org/pdf/2112.12761.pdf
Project: https://banmo-www.github.io/
Reference: https://80.lv/articles/neural-network-making-animatable-3d-models-from-videos/
Suggested
Credit: Source link
Comments are closed.