Meta AI and the University of Texas at Austin Researchers Open-Source Three New ML Models for Audio-Visual Understanding of Human Speech and Sounds in Video that are Designed for AR and VR
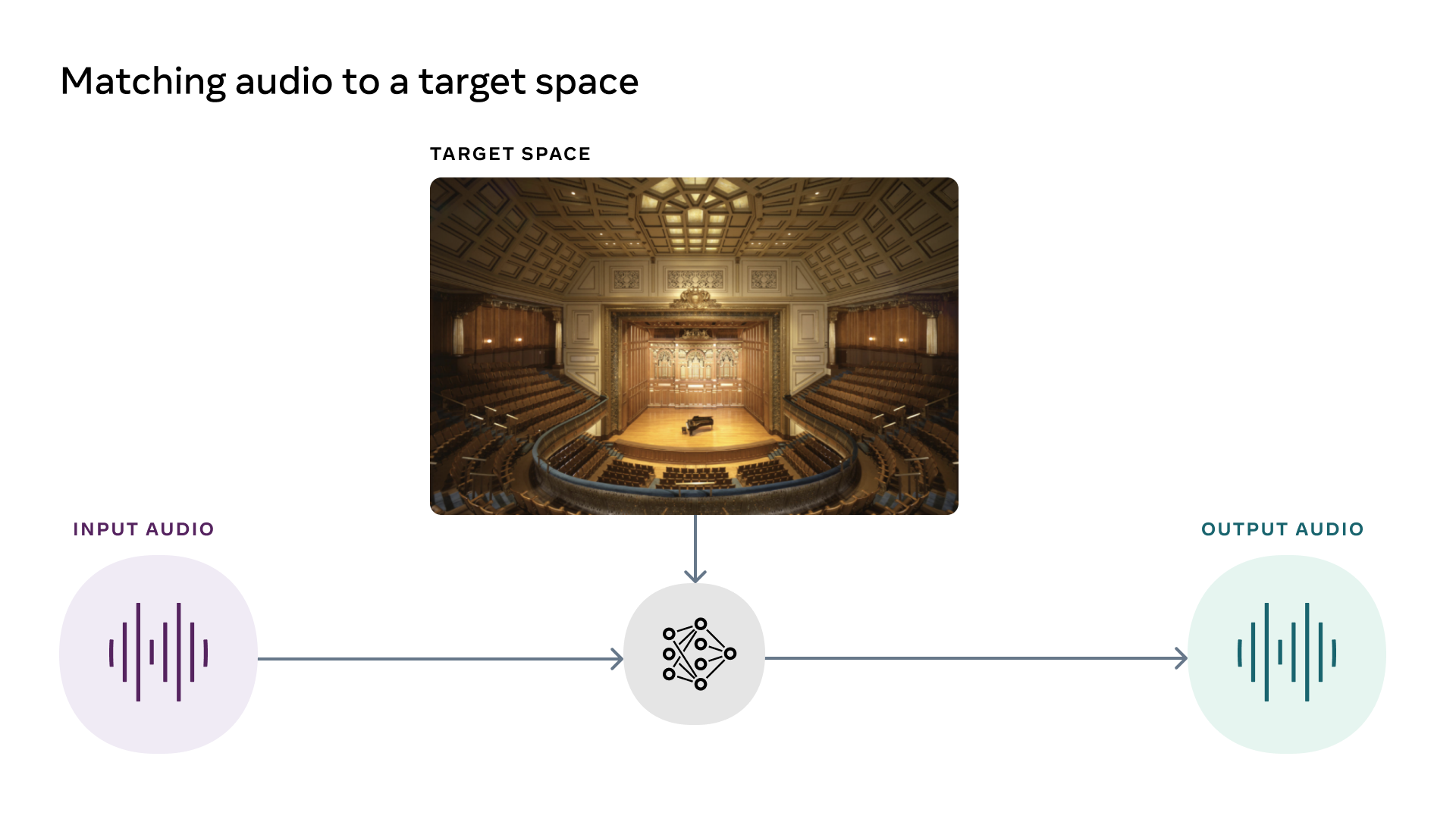
Acoustics significantly influence how we perceive moments. As society transitions to mixed and virtual realities, ongoing research is being done to produce high-quality sound that accurately reflects a person’s surroundings. AI models must be able to comprehend a person’s physical surroundings based on how those surroundings look and sound. This accounts for the reality that how we perceive audio depends on the geometry of physical space, the materials and surfaces nearby, and the distance from the source of the sounds. Researchers from the University of Texas at Austin and the Reality Labs at Meta have worked to open-source three new models for audio-visual interpretation of human voice and video noises. These models will get us closer to such a reality more quickly. Three distinct audio-visual tasks are the main emphasis of the models. The core Visual Acoustic Matching model named AViTAR modifies an audio clip such that it sounds as if it were recorded in the environment by taking it as input along with an image of the target environment. In order to enable the transformer to execute intermodality reasoning and provide a realistic audio output that matches the visual input, a cross-modal transformer model has been utilized where the input consists of both images and audio. Despite the absence of acoustically mismatched audio and unlabeled data in in-the-wild web videos, the self-supervised training objective learns acoustic matching from them. This transformer-based model was trained using two datasets.
In some circumstances, it becomes necessary to eliminate reverberation to improve hearing and comprehension. By eliminating reverberation using recorded sounds and the visual signals of a place, the second methodology, Visually-Informed Dereverberation (VIDA), does the reverse of the first model. Using both simulated and actual pictures, the method was examined for speech augmentation, speech recognition, and speaker identification. It is safe to say that VIDA achieves cutting-edge performance and is a significant advancement above conventional audio-only techniques. The team sees this as a significant step toward creating realism in mixed and virtual reality. The third approach, VisualVoice, distinguishes speech from other background sounds and voices using visual and acoustic clues. This model was created to aid jobs requiring machine understanding, such as improving subtitles or socializing at a party in virtual reality. The model is made to look and hear the same way humans do to comprehend speech in complex environments.
The audio-visual perception research at Meta AI focuses on these three models. AI models now in use perform admirably when comprehending photos and movies. However, multimodal AI models are required to extend such a performance to AR and VR. These models must be able to simultaneously process audio, video, and text information in order to produce a far richer understanding of the world. The researchers want to provide their clients with a multimodal and immersive experience shortly by allowing them to relive a memory in the virtual world while enjoying the graphics and sound quality precisely as it is. The acoustic characteristics of space will be captured using video and other dynamics in future work on multimodal AI. The team is incredibly eager to share its findings with the open-source community.
Visual Acoustic Matching Research Paper | Project Page
Visually-Informed Dereverberation Research Paper | Project Page
VisualVoice Research Paper | Project Page
Reference Article: https://ai.facebook.com/blog/ai-driven-acoustic-synthesis-for-augmented-and-virtual-reality-experiences/
Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.