Meta AI Introduces IMAGEBIND: The First Open-Sourced AI Project Capable of Binding Data from Six Modalities at Once, Without the Need for Explicit Supervision
Humans can grasp complex ideas after being exposed to just a few instances. Most of the time, we can identify an animal based on a written description and guess the sound of an unknown car’s engine based on a visual. This is partly because a single image can “bind” together an otherwise disparate sensory experience. Based on paired data, standard multimodal learning has limitations in artificial intelligence as the number of modalities increases.
Aligning text, audio, etc., with images has been the focus of several recent methodologies. These strategies only make use of two senses at most, if that. The final embeddings, however, can only represent the training modalities and their corresponding pairs. For this reason, it is not possible to directly transfer video-audio embeddings to image-text activities or vice versa. The lack of huge amounts of multimodal data where all modalities are present together is a significant barrier to learning a real joint embedding.
New Meta research introduces IMAGEBIND, a system that uses several forms of image-pair data to learn a single shared representation space. It is not necessary to use datasets in which all modalities occur simultaneously. Instead, this work takes advantage of images’ binding property and demonstrates how aligning each modality’s embedding to image embeddings results in an emergent alignment across all modalities.
The large amount of images and accompanying text on the web has led to substantial research into training image-text models. ImageBind makes use of the fact that images frequently co-occur with other modalities and can serve as a bridge to connect them, such as linking text to image with online data or linking motion to video with video data acquired from wearable cameras with IMU sensors.
Targets for feature learning across modalities can be the visual representations learned from massive amounts of web data. This means ImageBind can also align any other modality that frequently appears alongside images. Alignment is simpler for modalities like heat and depth that correlate highly to pictures.
ImageBind demonstrates that just using paired images can integrate all six modalities. The model can provide a more holistic interpretation of the information by letting the various modalities “talk” to one another and discover connections without direct observation. For instance, ImageBind can link sound and text even if it can’t see them together. By doing so, other models can “understand” new modalities without requiring extensive time- and energy-intensive training. ImageBind’s robust scaling behavior makes it possible to employ the model in place of or in addition to many AI models that previously could not use additional modalities.
Strong emergent zero-shot classification and retrieval performance on tasks for each new modality are demonstrated by combining large-scale image-text paired data with naturally paired self-supervised data across four new modalities: audio, depth, thermal, and Inertial Measurement Unit (IMU) readings. The team shows that strengthening the underlying image representation enhances these emergent features.
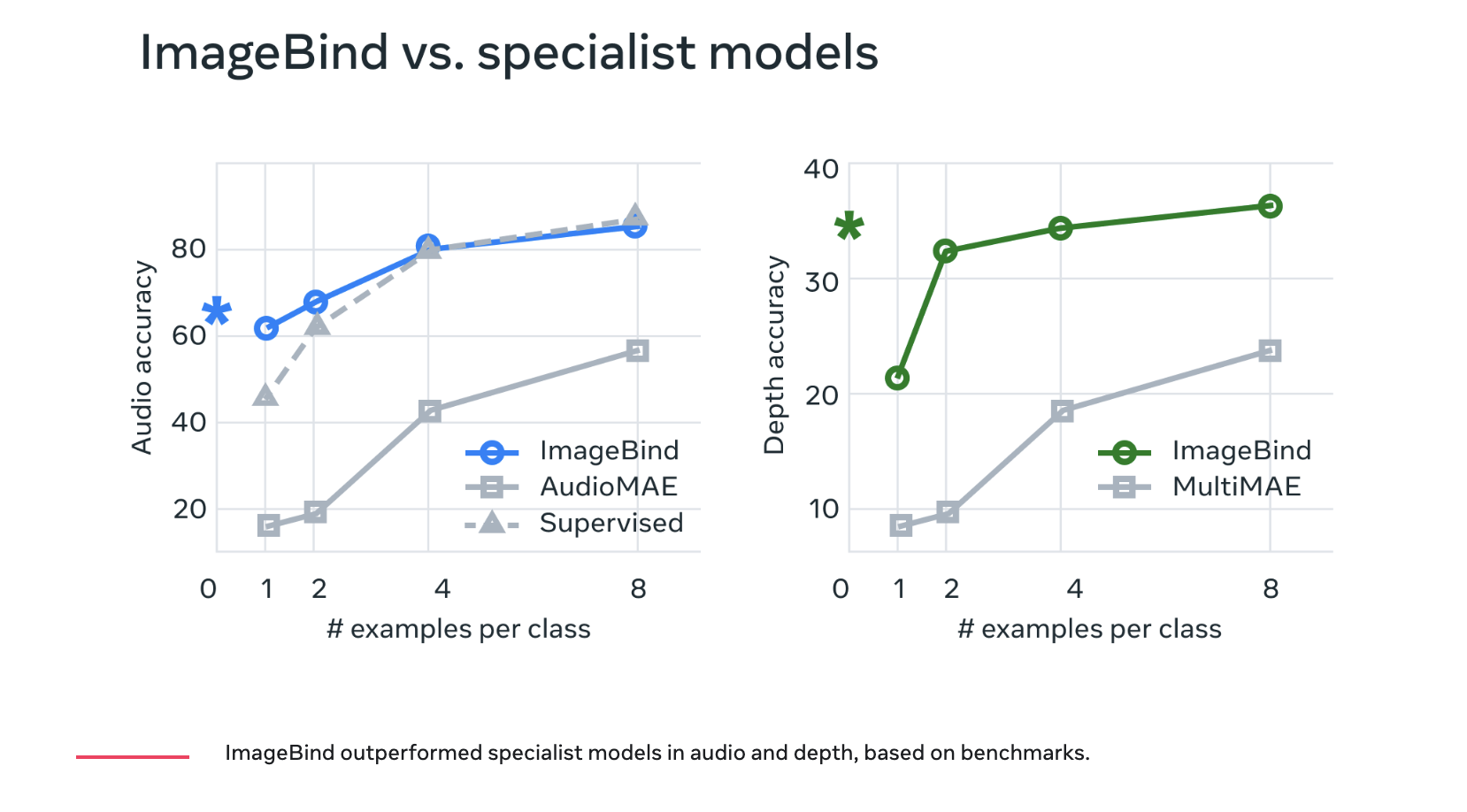
The findings suggest that IMAGEBIND’s emergent zero-shot classification on audio classification and retrieval benchmarks like ESC, Clotho, and AudioCaps is on par with or beats expert models trained with direct audio-text supervision. On few-shot evaluation benchmarks, IMAGEBIND representations also perform better than expert-supervised models. Finally, they demonstrate the versatility of IMAGEBIND’s joint embeddings across various compositional tasks, including cross-modal retrieval, an arithmetic combination of embeddings, audio source detection in images, and image generation from the audio input.
Since these embeddings are not trained for a particular application, they fall behind the efficiency of domain-specific models. The team believes it would be helpful to learn more about how to tailor general-purpose embeddings to specific objectives, such as structured prediction tasks like detection.
Check out the Paper, Demo, and Code. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.