Meta AI Introduces Seamless: A Publicly Available AI System that Unlocks Expressive Cross-Lingual Communication in Real-Time
New features and improvements in automatic voice translation have made it possible to accomplish much more, cover more languages, and work with more input formats. However, crucial capabilities that make machine-mediated communication feel natural compared to human-to-human conversation are currently missing from large-scale automated voice translation systems.
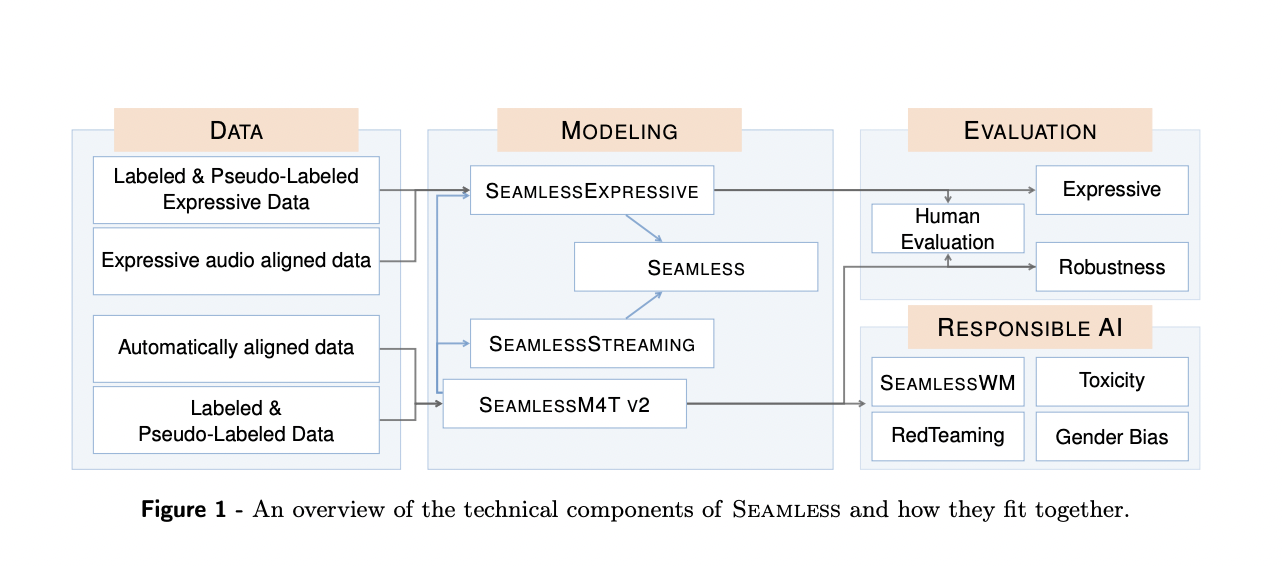
A new Meta AI study presents a set of models that can stream expressive and multilingual translations from beginning to end. The researchers started by presenting SeamlessM4T v2, an upgraded version of the SeamlessM4T model that is multimodal and supports nearly every language. This improved model, which uses a more recent version of the UnitY2 framework, was trained with linguistic data that had fewer resources. With the expansion of SeamlessAlign, a whopping 76 languages’ worth of data—114,800 hours—is automatically aligned. The two most recent models, SeamlessExpressive and SeamlessStreaming, are based on SeamlessM4T v2. With SeamlessExpressive, users can translate while keeping all vocal inflections and styles.
Meta’s study preserves the style of one’s voice while addressing certain underexplored features of prosody, such as speech pace and pauses, which have been neglected in prior expressive speech research attempts. Regarding SeamlessStreaming, the proposed model doesn’t wait for the source utterances to finish before producing low-latency target translations; instead, it uses the Efficient Monotonic Multihead Attention (EMMA) technique. With SeamlessStreaming, the first of its type, many source and target languages can simultaneously have their speech-to-text translations done.
The team evaluated these models’ prosody, latency, and robustness based on a mix of new and updated versions of preexisting automatic measures. To conduct human evaluations, they modified preexisting protocols to measure the most important qualities for meaning retention, authenticity, and expressiveness. They conducted a comprehensive evaluation of gender bias, the first known red-teaming effort for multimodal machine translation, the first known system for detecting and mitigating added toxicity, and an inaudible localized watermarking mechanism to mitigate the impact of deepfakes to guarantee that their models can be used responsibly and safely.
Seamless is the first publicly available system enabling expressive cross-lingual real-time communication. It combines SeamlessExpressive and SeamlessStreaming, which brings together major components. Overall, Seamless provides a crucial glimpse into the underlying technologies required to transform the Universal Speech Translator from a science fiction idea into a reality.
The researchers highlight that the model accuracy may differ by gender, race, or accent, even though we thoroughly tested our artifacts on various fairness axes and included safeguards when feasible. Further research should keep aiming to improve language coverage and close the performance disparities between low-resource and high-resource languages to realize the Universal Speech Translator.
Check out the Paper and Reference Article. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.