Meta AI introduces SPIRIT-LM: A Foundation Multimodal Language Model that Freely Mixes Text and Speech
Prompting Large Language Models (LLMs) has emerged as a standard practice in Natural Language Processing (NLP) following the introduction of GPT-3. The scaling of language models to billions of parameters using extensive datasets contributes significantly to achieving broad language understanding and generation capabilities. Moreover, large-scale language models exhibit the ability to tackle novel tasks by leveraging a few examples via in-context, few-shot learning.
Speech Language Models (SpeechLMs), which are language models trained directly on speech, have been introduced by researchers, marking the beginning of an active area of research. Recent studies have contributed to advancing this field.
SPIRIT-LM is introduced as a foundational multimodal language model that seamlessly integrates text and speech. The model builds upon a pre-trained text language model and expands its capabilities to incorporate speech by continual training on a combination of text and speech data. Text and speech sequences are merged into a unified token set and trained using a word-level interleaving approach with a curated speech-text parallel corpus.
SPIRIT-LM is available in two variants: a BASE version employing speech semantic units and an EXPRESSIVE version that incorporates pitch and style units to model expressivity alongside semantic units. Both versions encode text using the subword BPE tokens. The resultant model demonstrates a fusion of semantic comprehension from text models and expressive qualities from speech models.
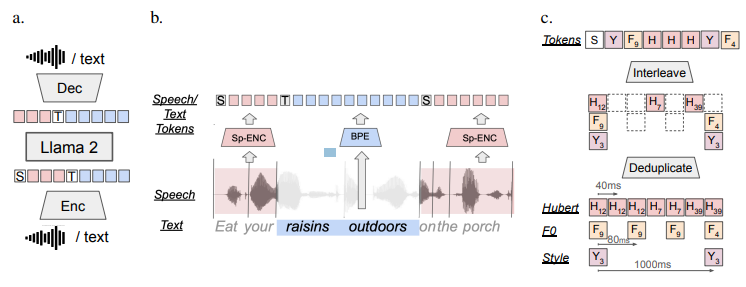
a. The architecture of SPIRIT-LM involves a language model trained through next-token prediction. Tokens are generated either from speech or text via an encoder and then reconstructed back to their original modality using a decoder. Training of SPIRIT-LM models encompasses a combination of text-only sequences, speech-only sequences, and interleaved speech-text sequences.
b. The scheme for interleaving speech and text involves encoding speech into tokens (depicted in pink) using clusterized speech units such as Hubert, Pitch, or Style tokens and text (depicted in blue) using BPE. Special tokens ([TEXT] for text and [SPEECH] for speech) are used to mark the respective modality. During training, a switch between modalities occurs randomly at word boundaries within aligned speech-text corpora. Speech tokens are deduplicated and then interleaved with text tokens at the boundary where the modality changes.
c. Expressive speech tokens are introduced for SPIRIT-LM-EXPRESSIVE. Pitch tokens and style tokens are interleaved after deduplication.
Their contributions are as follows:
- They introduce SPIRIT-LM, a unified language model capable of generating both speech and text. SPIRIT-LM is developed by continuously pretraining LLAMA 2 with interleaved speech and text data.
- Similar to text-based Language Models (LLMs), they observe that SPIRIT-LM can adeptly learn new tasks in a few-shot learning setting across text, speech, and crossmodal tasks (i.e., speech-to-text and text-to-speech).
- To assess the expressive capabilities of generative models, they introduce the SPEECHTEXT SENTIMENT PRESERVATION benchmark (STSP). This benchmark evaluates how effectively generative models maintain the sentiment of prompts within and across modalities for both spoken and written expressions.
- Finally, they propose an expressive variant of SPIRIT-LM, named SPIRIT-LM-EXPRESSIVE. Through the use of STSP, they demonstrate that SPIRIT-LM is the first language model capable of preserving the sentiment of both text and speech prompts within and across modalities.
As advancements in Large Language Models (LLMs) and Speech Language Models (SpeechLMs) continue, along with innovative approaches to prompt creation and model design, there’s great potential to improve natural language understanding systems. These advancements could profoundly impact many areas, such as conversational agents, virtual assistants, language translation, and accessibility tools. Ultimately, they could lead to more lifelike interactions between humans and machines.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.