Meta AI Open-Sources ViTDet Under a New Approach for Building Computer Vision Systems That Can Recognize a Wide Range of Common and Uncommon Objects
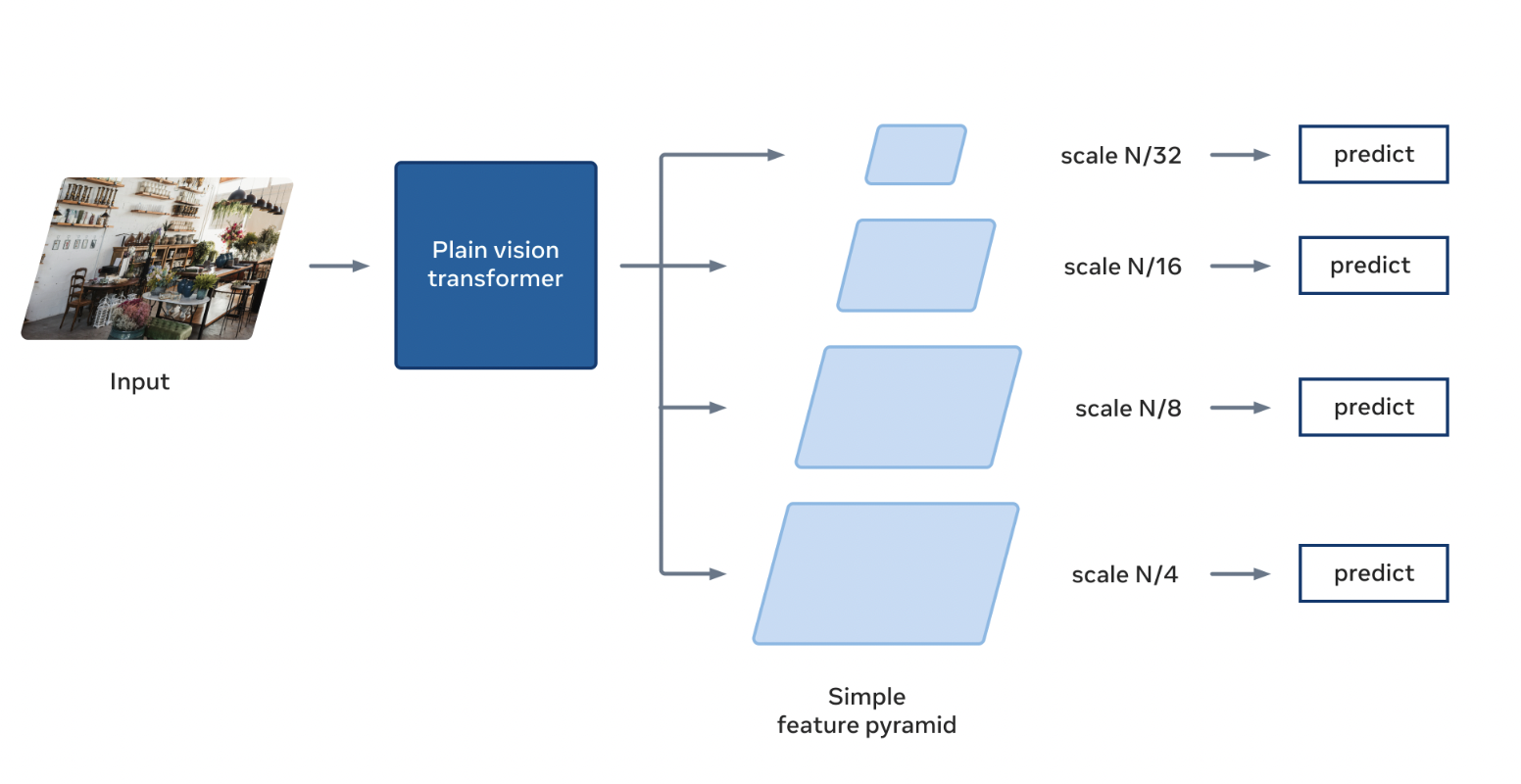
Even Meta AI has explored every avenue in light of recent developments in object detection research and has proposed a new study on using Vision Transformers (ViTs) for object detection. On benchmarks on the Large Vocabulary Instance Segmentation (LVIS) dataset, which was published by Meta AI researchers earlier in 2019, their method, ViTDet, surpasses prior approaches. The model must learn to identify a considerably greater variety of objects than can be done by traditional computer vision systems in this assignment. In the LVIS dataset, which includes a wide variety of objects in addition to more commonplace ones like tables and chairs, such as bird feeders, wreaths, and doughnuts, ViTDet beats earlier ViT-based models in reliably identifying objects. The team has also shared the ViTDet code and training recipes as new standards in their open-source Detectron2 object detection library, allowing the research community to replicate and improve upon these advancements.
ViTs have become a strong foundation for visual recognition in the past year. However, there are several difficulties with using ViTs for object detection. These difficulties concern using ViT for object detection in high-resolution photos and the detection of multiscale objects with a simple backbone. The original ViT is a simple, non-hierarchical architecture that keeps a single-scale feature map throughout processing, in contrast to typical convolutional neural networks. Unlike other studies like Swin and MViTv2, ViTDet solely employs straightforward, non-hierarchical ViT backbones. The single-scale feature map produced by the ViT is used to construct a straightforward feature pyramid. It employs nonoverlapping, primary window attention to effectively extract features from high-resolution images. This method allows the object detector to take advantage of easily accessible pretrained masked autoencoder (MAE) models since it decouples the pretraining of ViT from the fine-tuning requirements of detection.
The principal evaluation focuses on two pretraining approaches: supervised pretraining serving as the primary approach and self-supervised MAE pretraining serving as the second approach. The ViTDet detectors are trained initially by the researchers, who then train the Mask R-CNN framework using basic (B), large (L), and gigantic (H) size ViT backbones. The average precision of masks (Mask AP) and the average precision of masks in the rare categories (Mask AP-rare) are used to quantify accuracy on LVIS. It is challenging to perform well in uncommon categories because each rare category only has ten training samples. As we grow ViTDet’s ViT backbone size, the researchers could see that MAE pretraining produces better LVIS results when compared to supervised pretraining. They also noted that the core of the LVIS low-shot detection issue is the existence of strong Mask AP increases for rare category detection.
Object identification has grown in importance in computer vision because it has numerous applications, including autonomous driving, e-commerce, and augmented reality. To increase the value of object detection, CV systems must be able to identify unusual items and things that only sometimes exist in training data. With ViTDet, the team thinks it has reached a turning point where it can observe how better pretraining and more extensive backbones benefit LVIS, the benchmarking dataset for low-shot object detection challenges. By sharing their recently developed, robust baselines with ViTDet, they intend to aid the research community in pushing the boundaries of technology and creating better CV systems.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'Exploring Plain Vision Transformer Backbones for Object Detection'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, github link and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.