Meta AI Presents EfficientSAM: SAM’s Little Brother with 20x Fewer Parameters and 20x Faster Runtime
In vision, the Segment Anything Model (SAM) has achieved remarkable success, attaining cutting-edge results in numerous image segmentation tasks, including zero-shot object proposal generation, zero-shot instance segmentation, and edge detection, among other practical uses.
The SA-1B visual dataset, which contains over a billion masks from eleven million photos, is the foundation of SAM’s Vision Transformer (ViT) model. This enables the segmentation of any item in a given image. Because of its Segment Anything capability, SAM is not only a foundation model in vision, but its uses are also extended outside vision.
Despite these benefits, the prohibitive cost of the SAM architecture—particularly the image encoder, such as ViT-H—makes the SAM model an impediment to practical adoption in terms of efficiency.
In response to this difficulty, several recent publications have offered solutions that lessen the financial burden of using SAM for prompt-based instance segmentation.
A small ViT image encoder could, for instance, benefit from the expertise of the default ViT-H picture encoder, according to earlier research. A real-time CNN-based design can cut computing costs for Segment Anything’s activity. A well-trained lightweight ViT image encoder, such as ViT-Tiny/-Small, is suggested here to simplify SAM without sacrificing performance.
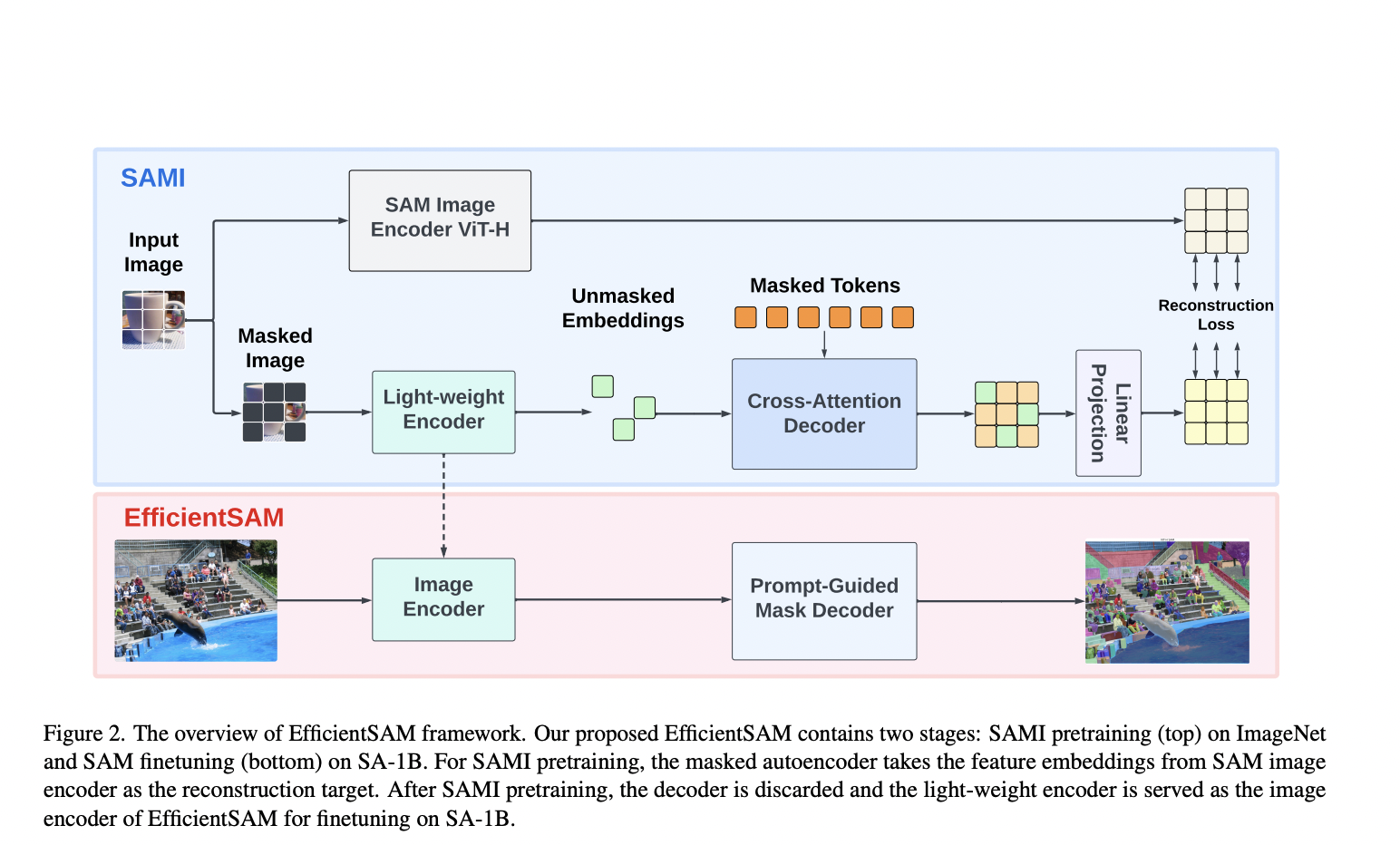
A new Meta AI research creates the pre-trained lightweight ViT backbones for every task using our technology, SAM-leveraged masked image pertaining (SAMI). To do this, the researchers establish high-quality pretrained ViT encoders by utilizing the renowned MAE pretraining method with the SAM model.
To be more precise, the proposed SAMI trains a masked image model using lightweight encoders to reconstruct features from ViT-H of SAM rather than image patches, and it uses the SAM encoder, ViT-H, to provide feature embedding. This produces generic ViT backbones that can be utilized for subsequent operations like picture categorization, object identification, and segmentation. Then, the pretrained lightweight encoders were fine-tuned for the segment and any task using SAM decoders.
The teams also provide EfficientSAMs, lightweight SAM models with cutting-edge quality-efficiency trade-offs for real-world implementation.
The team pretrained the models on ImageNet with a reconstructive loss utilizing 224 × 224 image resolution and then fine-tuned them on target tasks using supervised data to assess their strategy in a transfer learning context for masked image pretraining. SAMI can learn generalizable, lightweight encoders. Models trained on ImageNet-1K using SAMI pretraining do better regarding generalization, such as ViT-Tiny/-Small/-Base. When fine-tuned on ImageNet-1K with 100 epochs, it achieves 82.7% top-1 accuracy for a ViT-Small model, which is better than other state-of-the-art image pretraining baselines. Object detection, instance segmentation, and semantic segmentation are areas where the team further refine their pretrained models.
Compared to existing pretraining baselines, their strategy outperforms them on these tasks. What’s more, even for small models, they see substantial improvements. Additionally, the Segment Anything challenge is used to assess our models. The model outperforms FastSAM and current lightweight SAM algorithms on zero-shot instance segmentation by 4.1AP/5.2 AP on COCO/LVIS.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.