Meta AI Proposes a Novel System for Text-to-4D (3D+time) Generation by Combining the Benefits of Video and 3D Generative Models
The last quarter of 2022 was the era of text-to-image models. We have seen numerous successful examples that could generate realistic images from text prompts or could edit and alter the image by using the given directions. It is now possible to generate photorealistic images by asking the AI model to do so. The advancement still continues and is accelerating. Text-to-image models are improving with new techniques to produce even better images and/or reduce computational complexity.
We have also seen other text-to-X use cases. Phenaki was one of the first models to generate videos using text prompts. Then, we have seen many methods trying to achieve text-to-video generation. On the other hand, some studies focused on generating 3D shapes. Although we have some successful studies, the domain mainly focused on text-to-image models.
Both video and 3D shapes have three dimensions. For video, they are width x height x time, and for 3D shape, they are width x height x depth. What if we could combine these two and come up with a 4D generation model? That means we would have an animated 3D shape for us with width x height x depth x time dimensions. This sort of model can be used to generate 3D assets for video games, virtual reality, and augmented reality. Well, this is what Make-a-Video3D (MAV3D) is trying to achieve.
So now we will have a video where we can stop at any time and move the object around. As you can imagine, it is not easy to find such videos, let alone construct a large-scale dataset with them to train a model. You can get existing videos and try to reconstruct the shape of the object in the scene, but that is a really challenging task, and most of the time outcome is not that reliable. Thus, the first major problem is solving this dataset issue.
But how are the existing 3D videos are recorded? How can we integrate another dimension if we want to record it manually? The answer is using multiple cameras. When you record the scene simultaneously from different angles, using tens of cameras, you can then stitch them together to reconstruct the scene in 3D. This multi-camera setup is too expensive to construct, therefore, they are also pretty rare to find. Therefore, generating the dataset for training is the way to go here.
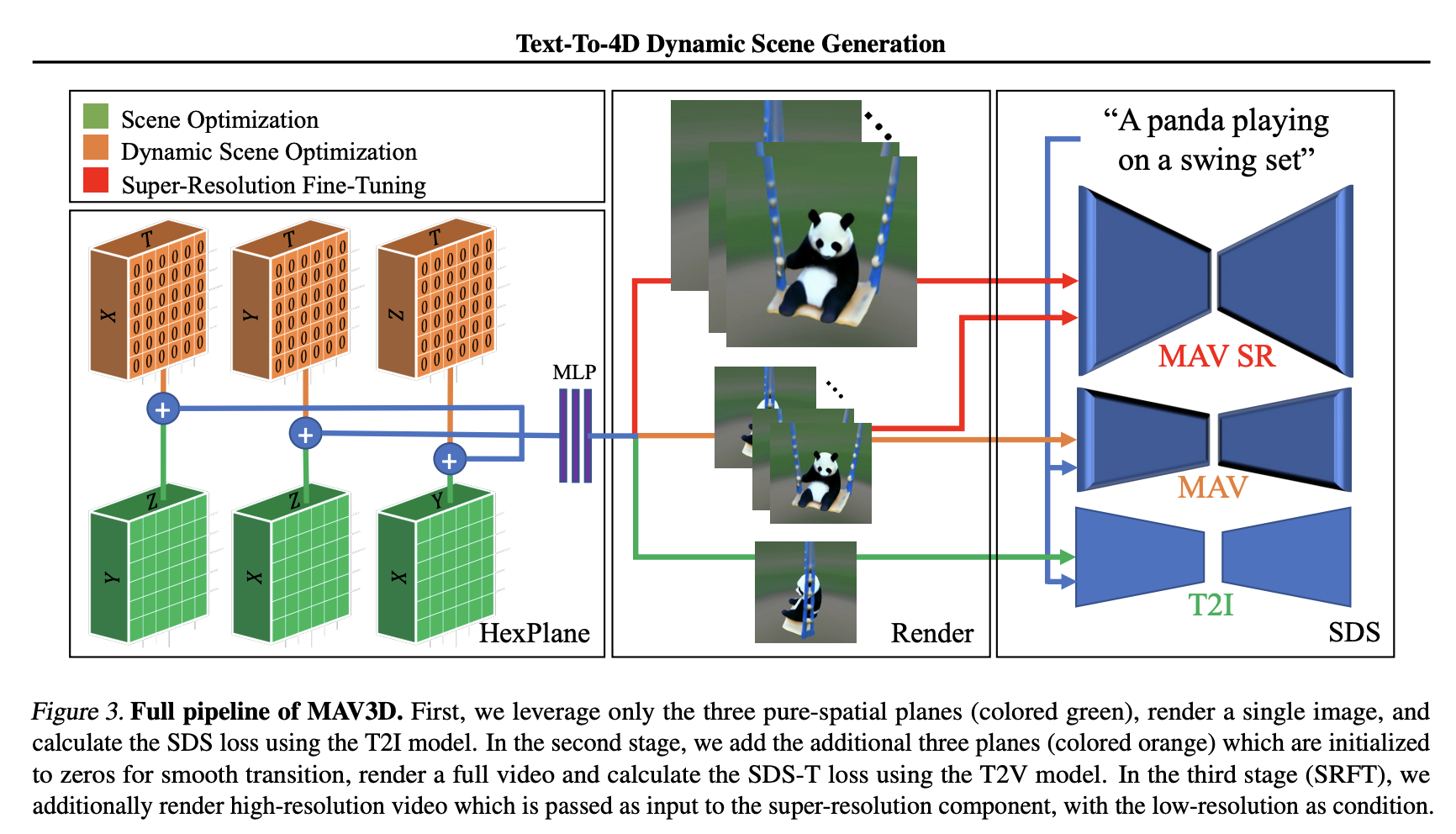
MAV3D brilliantly approaches this dataset generation problem. They try to mimic the multi-camera setup to construct 3D videos using existing video generators. The idea is that existing video generators implicitly model different viewpoints for generated scenes, which can be treated as a statistical multi-camera setup. MAV3D uses a dynamic Neural Radiance Field (NeRF) and decodes the input text prompt into a video while sampling random viewpoints around the object to optimize the reconstruction. Think of it like passing the “a corgi playing with a ball” prompt to a 2D video generator multiple times but changing the prompt to include different viewpoints like “a corgi playing with a ball, recorded from behind” and then “a corgi playing with a ball, recorded from sideways.”
Although the idea is well-constructed, the execution is not that simple, as several issues need to be solved before. The first issue is finding an efficient and trainable way to represent dynamic 3D scenes. To do that, MAV3D uses a set of six multiresolution feature planes to represent a 4D scene.
The second issue is supervising the text-to-4D video model. This is solved by using a multi-stage training pipeline for dynamic scene rendering. A text-to-image model is used to convert the 3D scene to a text prompt. Then a temporal aware Score Distillation Sampling (SDS) loss is used to supervise the model.
Finally, the output resolution cannot be too high as generating a 4D scene is computationally too expensive. Therefore, MAV3D uses a temporal-aware super-resolution fine-tuning in the end.
MAV3D is a novel approach that employs several diffusion models and dynamic NeRFs to generate 3D videos from text prompts. While it is one of the first attempts, it can still generate successful videos.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.