Meta AI Releases BELEBELE: The First Parallel Reading Comprehension Evaluation Benchmark for 122 Languages
A significant challenge in evaluating the text comprehension abilities of multilingual models is the lack of high-quality, simultaneous evaluation standards. There are high-coverage natural language processing datasets like FLORES-200, although they are mostly used for machine translation. Although 100+ languages use understanding and generative text services, the lack of labeled data presents a significant barrier to building effective systems in most languages.
Significant scientific research is needed beyond LLMs to enable the efficient and successful development of NLP systems for low-resource languages. While many modeling approaches claim to be language-independent, their applicability to a wide range of phenomena types is often only tested in a small subset of languages.
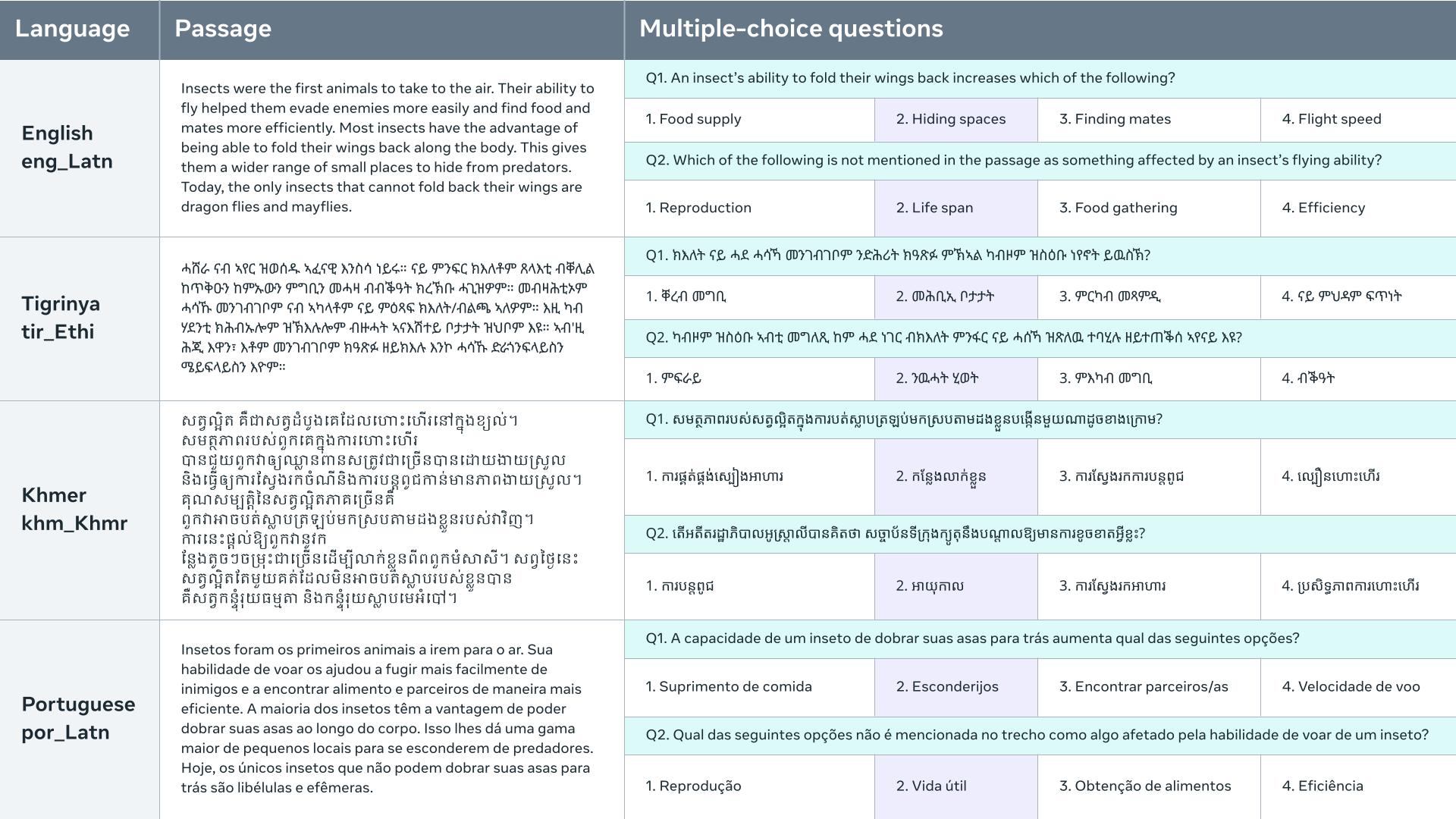
A new study by Meta AI, Abridge AI, and Reka AI releases BELEBELE, a key benchmark for evaluating natural language understanding systems across 122 different language varieties. Each 488 paragraphs in the dataset has corresponding multiple-choice questions in the dataset’s 900 total questions. Questions distinguish between models with varying levels of language comprehension competence and have been created with care. The questions are designed to reward generalizable NLU models and purposely penalize biased models, even though they do not require higher knowledge or reasoning. Questions asked in English can be answered with nearly perfect precision by humans. The diverse model outputs indicate that this is a discriminative NLU challenge, similar to well-known LLM benchmarks like MMLU.
The BELEBELE system is the first of its kind and is parallel across all languages. This allows for the first direct comparison of model performance across languages. The data set includes 29 writing systems and 27 language families, representing various resource availability and linguistic diversity. One of the first natural language processing (NLP) benchmarks for the Romanized version of Hindi, Urdu, Bengali, Nepali, and Sinhala is based on these seven languages written in two different scripts.
The dataset’s parallel nature allows for the evaluation of cross-lingual textual representations in various cross-lingual scenarios, and it may be used to assess both monolingual and multilingual models. The task may be evaluated using full fine-tuning by piecing together a training set from comparable QA datasets. The researchers use numerous masked language models (MLMs) for fine-tuning translations between languages and between English and other languages. Five-shot in-context learning and zero-shot (in-language and translate-test) evaluations are used to compare different models for LLMs.
The findings show that while English-centric LLMs can go far and generalize to over 30 languages, models trained on medium- and low-resource languages benefit most from a large vocabulary size and balanced pre-training data.
The team hopes their study helps improve existing model architectures and training methods by shedding light on how they handle multilingual data.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.