Meta AI Releases HM3D-Sem Dataset, the Largest-Ever Dataset of Semantically-Annotated 3D Indoor Spaces
Scaling has gained importance as a result of recent technology breakthroughs. Large neural networks have been trained in 3D environments using deep reinforcement learning over billions of steps of experience, which has helped advance the development of embodied intelligent entities capable of completing goal-driven tasks. To ensure that networks run on such a massive scale without hassle, RL systems must scale to several computers and make good use of the available resources, such as GPUs, all while maintaining sample-efficient learning. One such promising method for achieving this scale is batched on-policy. These methods collect experience from several different environments using the policy and update it with the cumulative experience.
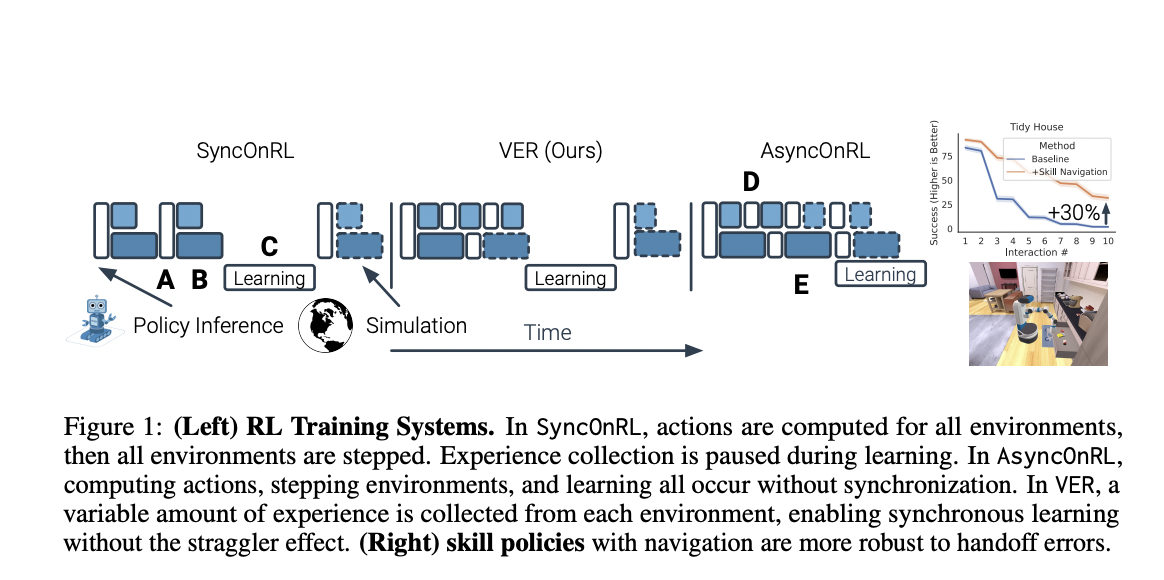
Generally, on-policy Reinforcement Learning RL is divided broadly into the synchronous (SyncOnRL) and asynchronous (AsyncOnRL) classes. First, the policy is applied to the full batch until T steps have been gathered from all N environments. This is the first of two synchronization points in SyncOnRL. The updated policy is based on this (T, N)-shaped batch of experience. However, throughput is decreased by synchronization because the system must wait a long time for the slowest environment to complete. The straggler effect is a term used frequently to describe this occurrence. By eliminating these synchronization locations, AsyncOnRL reduces the straggler effect and boosts throughput. In a recently published paper by Meta AI and Georgia Institute of Technology researchers, the team suggested Variable Experience Rollout (VER). This method combines the benefits of SyncOnRL and AsyncOnRL while blurring their distinctions. Similar to AsyncOnRL, VER does not use synchronization points; instead, it computes the following action steps and environments, and updates the policy as soon as practicable. VER updates the policy after gathering experience with the current one, just like SyncOnRL does.
Two significant insights served as the foundation for VER. The first was that AsyncOnRL reduces the straggler effect by implicitly gathering a different amount of experience from each environment (more from fast-to-simulate environments and less from slow environments). The second finding is that the rollout length is constant for both SyncOnRL and AsyncOnRL. Although a set rollout length may make implementation easier, according to the researchers, it is not necessary for RL. These two crucial findings prompted the development of variable experience rollout (VER) or the practice of gathering rollouts with a varying number of stages. According to the pace of its simulation, VER modifies the rollout duration for each environment. The result is an RL system that defeats the straggler effect and retains sample efficiency by learning from on-policy data. VER concentrates on effectively using a single GPU. The researchers paired VER with the decentralized distributed technique presented in [Wijmans et al., 2020] to enable effective scaling to many GPUs.
After conducting several experimental evaluations, the researchers concluded that VER results in considerable and consistent speedups across a wide range of embodied navigation and mobile manipulation tasks in photorealistic 3D simulation settings. In particular, VER is 60-100% quicker (a 1.6-2x speedup) than DD-PPO, the current state of the art for distributed SyncOnRL, with equivalent sample efficiency for PointGoal navigation and ObjectGoal navigation in Habitat 1.0. In comparison to DD-PPO, Habitat 2.0 VER is 150% faster (2.5x speedup) on 1 GPU and 170% faster (2.7x speedup) on 8 GPUs for mobile manipulation tasks (open fridge/cabinet, pick/place objects). With improved sample efficiency, VER is 70% faster (1.7x speedup) on 8 GPUs than SampleFactory, the most advanced AsyncOnRL currently available.

The team took advantage of these speedups in order to train chained abilities for GeometricGoal rearrangement tasks in the Home Assistant Benchmark (HAB). They discovered a startling appearance of navigation in abilities that do not require any navigation. The Pick talent specifically entails a robot picking a thing from a table. The robot was never required to navigate during training because it was always spawned close to the table. The robot, however, learns to explore and then pick an object in unfamiliar surroundings with 50% success, displaying surprisingly high out-of-distribution generalization, according to the researchers, assuming base movement is included in the action space. VER can be extremely helpful while researching rearranging. When provided access to navigation actions, it aids in identifying the appearance of navigation in policies that purportedly do not require navigation. Strong progress is made on Tidy House as a result (+30% success), but it also demonstrates that it might not always be best to eliminate “unneeded actions.”
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'VER: Scaling On-Policy RL Leads to the Emergence of Navigation in Embodied Rearrangement'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, github link and project. Please Don't Forget To Join Our ML Subreddit
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.