Meta AI Research Releases A Direct Speech-To-Speech Translation (S2ST) Approach That Enables Faster Inference And Supports Translation Between Unwritten Languages
This Article is written as a summay by Marktechpost Staff based on the research article 'Advancing direct speech-to-speech modeling with discrete units'. All Credit For This Research Goes To Apple Researchers on This Project. Checkout the paper 1, paper 2, paper 3 and github. Please Don't Forget To Join Our ML Subreddit
Standard text-based translation systems are not enough in the current world, where we have more than thousands of languages. This is because the traditional systems have drawbacks in creating speech-to-speech translation systems. It employs a cascading set of processes where the computing costs and inference latency increase with each stage. This method cannot be used to translate into every spoken language because more than 40% of the languages in the world lack text writing systems.
A new Meta AI research introduces a direct speech-to-speech translation (S2ST) approach that enables faster inference and supports translation between unwritten languages. This method works better than earlier methods since it does not rely on text generation as an intermediate step, in contrast to prior methods. The team claims that this is the first direct S2ST system trained using actual, publicly available audio data instead of synthetic audio for numerous language pairs.
Present-day speech-to-speech systems immediately convert source speech into target speech spectrograms, which are multidimensional continuous-value vector representations of the frequency spectrum. However, because translation models must learn numerous distinct facets of the relationship between two languages, it might be challenging to train them using voice spectrograms as the aim.
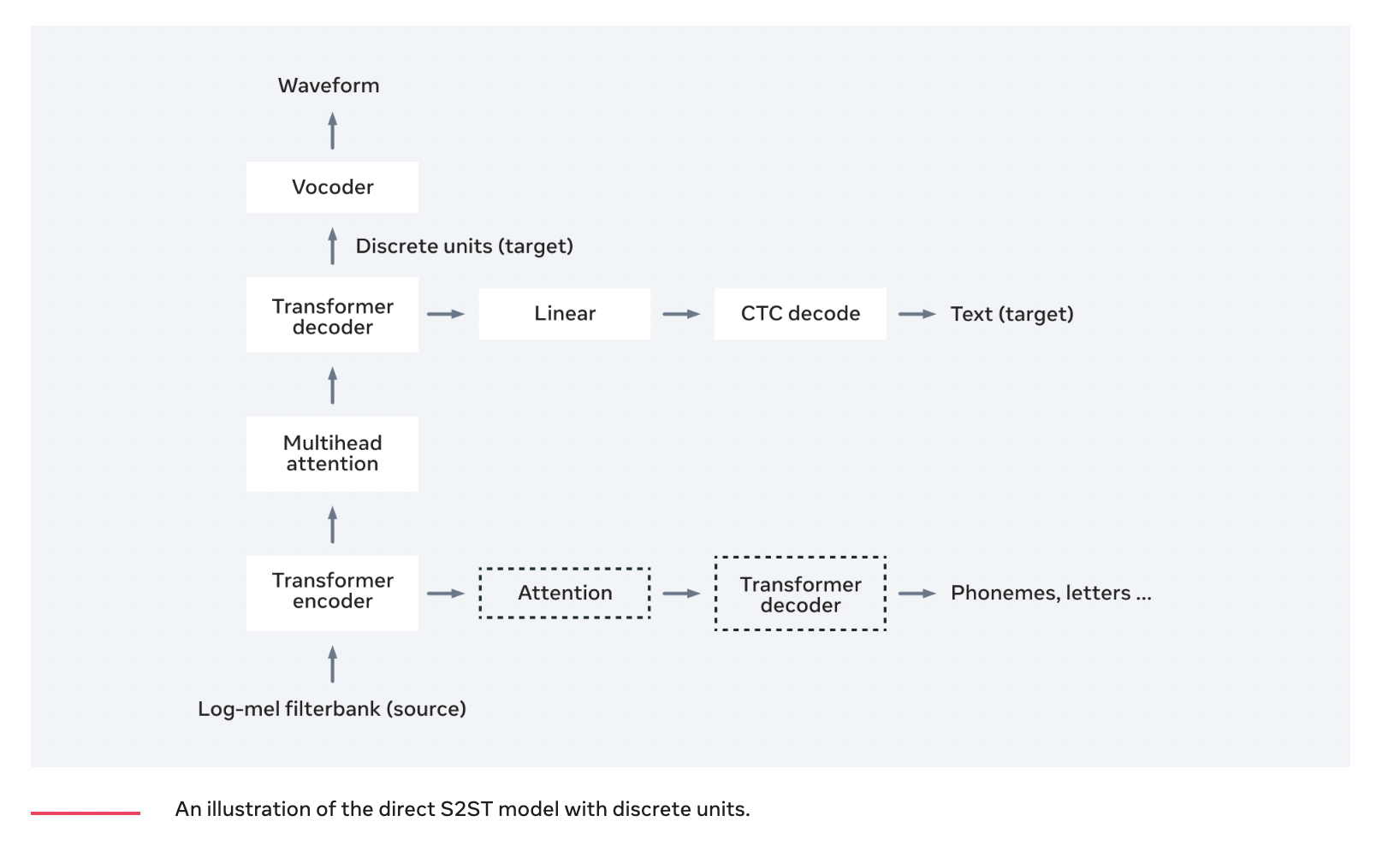
The researchers used discretized speech units instead of spectrograms, which they derived by clustering self-supervised speech representations. Unlike spectrograms, discrete units can take advantage of existing natural language processing modeling techniques and decouple linguistic content from prosodic speech information. They claim to have made three important improvements using discretized speech units:
- The S2ST system performs better than earlier direct S2ST systems
- It is the first direct S2ST system to be trained on real S2ST data for many language pairings
- It makes use of pretraining with unlabeled speech data.
The researchers employed self-supervised discrete units as targets (speech-to-unit translation, or S2UT) for training the direct S2ST system to facilitate direct speech-to-speech translation with discrete units (audio samples). They suggest a transformer-based sequence-to-sequence paradigm with an integrated voice encoder and discrete unit decoder.
Their study uses the Fisher Spanish-English speech translation corpus, which comprises 139K sentences (about 170 hours) transcribed in both Spanish and English from Spanish-speaking telephone conversations. Using a top-notch internal text-to-speech engine, they produce synthetic target speech with a single female voice as the training target. The synthetic target speech is used in all trials, including the baselines, and the TTS engine is not utilized in any other way. The system outperforms the earlier works by using discrete units from the source language as the auxiliary task goal during training in a textless environment. Compared to a straightforward S2ST model that predicts spectrogram features as a baseline, using discrete units results in an improvement of 6.7 BLEU.
Previous work on direct S2ST relies on TTS to generate synthetic target speech for model training due to the absence of parallel S2ST training data. This makes it impracticable to support languages without a standardized text writing system. The proposed S2UT system is trained on real data from VoxPopuli S2S data and automatically mined S2S data without any additional text supervision. The key is a speech normalization method that can be trained with as little as an hour’s worth of speech data. This technique improves S2UT performance compared to unnormalized targets by eliminating the variances in real target speech from various speakers without altering the linguistic content.
Additionally, without human annotations, the top textless direct voice translation model transcribes target speech with performance on par with cascaded text-based systems. An additional 2.0 BLEU gain is seen while using autonomously mined S2ST data during training. This is the first time a textless S2ST system has shown competitive results while effectively training with widely accessible real-world data in many languages.
The researchers further enhance the S2UT performance of the systems. In their paper, “Enhanced direct speech-to-speech translation via self-supervised pretraining and data augmentation,” the researchers focus on pretraining with unlabeled speech data. They demonstrate that pretraining ideas from cutting-edge speech-to-text translation (S2T) systems may be effectively transferred to direct S2ST when discrete units are used as the goal.
The approach takes us closer to translation systems for unwritten languages, which are still widely used and largely unsupported for dialects worldwide. They hope that their work paves the way for additional speech-to-speech translation research and boosts the accuracy of translations, giving users more seamless communication experiences.
Credit: Source link
Comments are closed.