Meta AI Researchers Introduce GenBench: A Revolutionary Framework for Advancing Generalization in Natural Language Processing
A model’s capacity to generalize or effectively apply its learned knowledge to new contexts is essential to the ongoing success of Natural Language Processing (NLP). Though it’s generally accepted as an important component, it’s still unclear what exactly qualifies as a good generalization in NLP and how to evaluate it. Generalization lets models respond and interpret differently depending on the situation. When it comes to sentiment analysis, chatbots, and translation services, NLP models must be able to generalize well in order to function well in a variety of settings.
Good generalization is significant for the NLP models to apply what they have learned to unique, real-world scenarios rather than just being adept at rote memorizing training data. To address that, a group of researchers from Meta has proposed a thorough taxonomy to describe and comprehend NLP generalization research. They have introduced a new framework called the GenBench initiative, which aims to address these challenges and systematize generalization research in NLP. It is a structured framework for classifying and arranging the numerous facets of generalization in NLP.
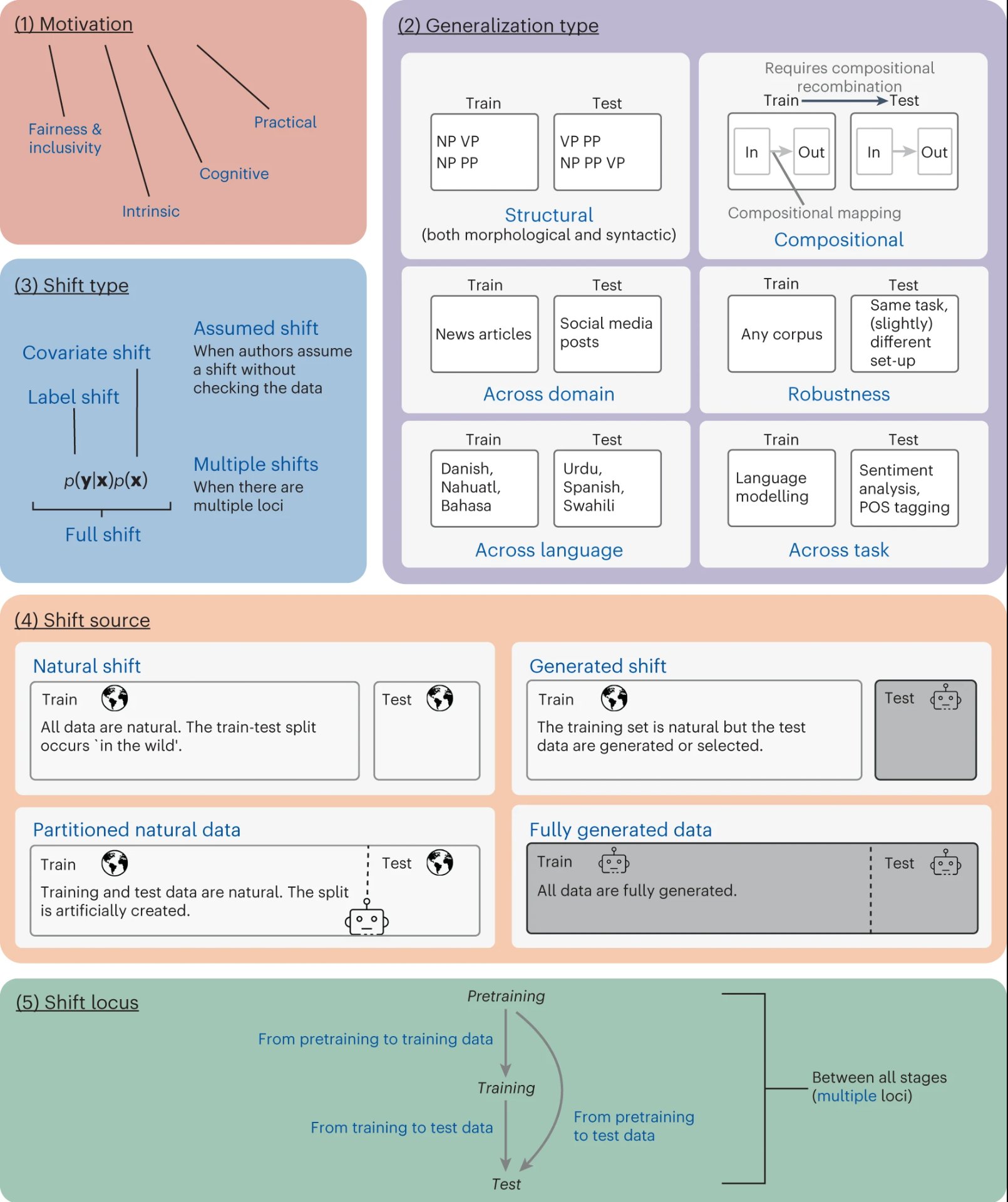
The taxonomy is composed of five axes, each of which functions as a dimension to categorize and distinguish distinct research and experimental works on NLP generalization, which are as follows.
- Main Motivation: Studies are categorized along this axis according to their main goals or driving forces. Distinct objectives, such as robustness, performance, or human-like behavior, may motivate different investigations.
- Type of Generalization: Study types are classified according to the particular kind of generalization that each study seeks to address. This could involve problems with topic changes, genre transitions, or domain adaptability.
- Type of Data Shift: Studies are categorized along this axis according to the type of data shift they are concentrating on. Data shifts can occur in a number of ways, including variations in topic, genre, or domain.
- Source of Data Shift: It is important to determine where data shifts are coming from. It could result from variations in the techniques used for data processing, labeling, or gathering.
- Locus of Data Shift in NLP Modelling Pipeline: This dimension establishes the location of the data shift within the NLP modeling process. It could occur in the model architecture, during preprocessing, or at the input level.
GenBench includes a generalization taxonomy, a meta-analysis of 543 research papers related to generalization in NLP, online tools for researchers, and GenBench evaluation cards. It has been introduced with the goal of making state-of-the-art generalization testing the new standard in NLP research, enabling better model evaluation and development. Not only are the conclusions drawn from the taxonomy classification useful for scholarly purposes, but they also offer insightful suggestions for further investigation. The taxonomy can help researchers fill in knowledge gaps and advance the grasp of generalization in natural language processing by pointing out areas of knowledge deficiency.
In conclusion, the taxonomy represents a substantial advancement in the field of NLP. Since NLP is still essential for many applications, a better grasp of generalization is necessary to improve the resilience and versatility of the models in practical settings. Having the taxonomy in place makes it easier to get good generalizations, which further fosters the growth of Natural Language Processing.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.