Meta AI Shatters Barriers with Voicebox: An Unprecedented Generative AI Model-Revolutionizing the Field of Speech Synthesis
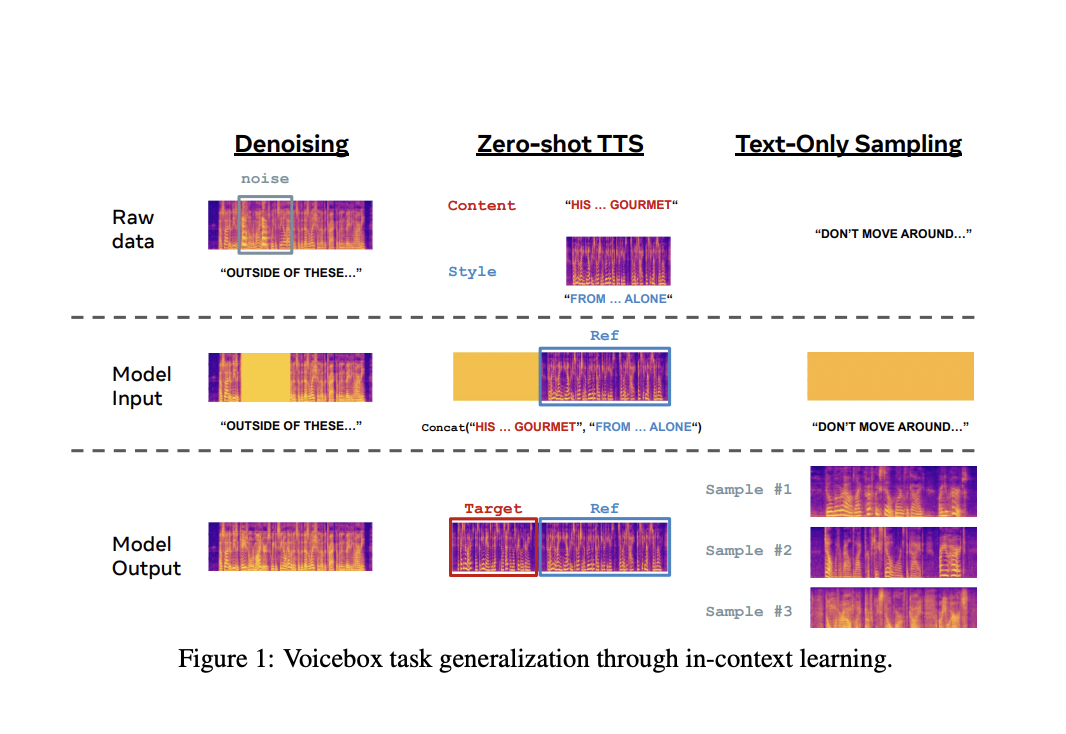
Meta-AI Researchers have recently achieved a significant breakthrough in generative AI for speech. They have developed Voicebox, an innovative AI model that showcases the state-of-the-art performance and the ability to generalize to speech-generation tasks without specific training.
Unlike previous speech-generation models, Voicebox utilizes a novel approach called Flow Matching, which surpasses diffusion models in terms of performance. Voicebox has proven to outperform existing models in both intelligibility and audio similarity while also being up to 20 times faster. Furthermore, it can synthesize speech in six languages and perform noise removal, content editing, style conversion, and diverse sample generation.
Traditionally, generative AI for speech required thorough training for each specific task using carefully curated data. However, Voicebox breaks this barrier by learning from raw audio and its accompanying transcription. This breakthrough allows the model to modify any part of a given sample rather than being limited to changing only the end of an audio clip.
The researchers trained Voicebox using over 50,000 hours of recorded speech and transcripts from public-domain audiobooks in English, French, Spanish, German, Polish, and Portuguese. The model was trained to predict speech segments based on surrounding speech and corresponding transcripts. By learning to infill speech from context, Voicebox can generate speech portions in the middle of an audio recording without recreating the entire input.
Voicebox’s versatility enables it to excel in various speech-generation tasks. It can perform in-context text-to-speech synthesis, cross-lingual style transfer, speech denoising and editing, and diverse speech sampling. For instance, with a two-second input audio sample, Voicebox can match the audio style and use it for text-to-speech generation. This capability has potential applications in helping individuals unable to speak or customizing voices for virtual assistants and nonplayer characters.
Another impressive feature of Voicebox is its ability to perform cross-lingual style transfer. Given a speech sample and a text passage in one of the supported languages, Voicebox can generate a reading of the text in the corresponding language. This breakthrough could facilitate natural and authentic communication among individuals who speak different languages.
Additionally, Voicebox’s in-context learning makes it proficient in seamlessly editing segments within audio recordings. It can resynthesize speech segments corrupted by short-duration noise or replace misspoken words without re-recording the entire speech. This capability simplifies the process of cleaning up and editing audio, potentially revolutionizing audio editing tools.
Moreover, Voicebox’s training on diverse real-world data enables it to generate speech that better represents how people naturally talk across different languages. This ability could be employed to generate synthetic data for training speech assistant models. Remarkably, speech recognition models trained on Voicebox-generated synthetic speech achieve near-parity with models trained on real speech, resulting in minimal accuracy degradation.
While the researchers acknowledge the importance of openness and sharing research with the AI community, they are withholding public access to the Voicebox model and code due to potential risks of misuse. In their research paper, they outline the development of a highly effective classifier to distinguish between authentic speech and audio generated with Voicebox, aiming to mitigate possible future risks.
Voicebox represents a significant advancement in generative AI for speech, offering a versatile and efficient model that exhibits task generalization capabilities. With the potential for numerous applications, Voicebox opens up new possibilities for speech synthesis, cross-lingual communication, audio editing, and training speech recognition models. As the research community builds upon this breakthrough, the field of generative AI for speech is poised for exciting advancements and discoveries.
Check Out The Paper and Meta Article. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.