Meta Open-Sources Holistic Trace Analysis (HTA): A Performance Analysis Tool That is Fully Scalable to Support State-of-the-Art Machine Learning ML Workloads
Machine learning and deep learning models perform remarkably on various tasks thanks to recent technological developments. However, this outstanding performance is not without a cost. Machine learning models often require a large amount of computational power and resources to attain state-of-the-art accuracy, which makes scaling these models challenging. Furthermore, because they are unaware of the performance limitations in their workloads, ML researchers and systems engineers frequently fail to computationally scale up their models. Often, the number of resources requested for a job is only sometimes what is actually needed. Understanding resource usage and bottlenecks for distributed training workloads are crucial for getting the most out of a model’s hardware stack.
The PyTorch team worked on this problem statement and recently released Holistic Trace Analysis (HTA), a performance analysis and visualization Python library. The library can be used to understand performance and identify bottlenecks in distributed training workloads. This is accomplished by reviewing traces gathered using the PyTorch Profiler, also known as Kineto. Kineto traces are frequently complicated to comprehend; this is where HTA aids in elevating the performance data found in these traces. The library was first employed internally at Meta to better understand performance-related problems for extensive distributed training tasks on GPUs. The team then set to work on improving several of HTA’s capabilities and scaling them to support cutting-edge ML workloads.
Several elements, such as how model operators interact with GPU devices and how such interactions can be measured, are taken into consideration to understand the GPU performance in distributed training jobs. Three main kernel categories—Computation (COMP), Communication (COMM), and Memory (MEM)—can be used to classify GPU processes throughout the execution of a model. All mathematical operations carried out during model execution are handled by compute kernels. In contrast, communication kernels are in charge of synchronizing and transferring data among several GPU devices in a distributed training job. Memory kernels control data transfer between host memory and the GPUs as well as memory allocations on GPU devices.
Evaluation of the performance of several GPU training jobs depends critically on how model execution generates and coordinates the GPU kernels. This is where the HTA library steps in since it offers insightful information on how the model execution interacts with the GPU hardware and points up areas for speed improvement. The library seeks to give users a more thorough understanding of the inner workings of distributed GPU training.
It can be difficult for common folks to understand how GPU training jobs perform. This inspired the PyTorch team to create HTA, which streamlines the trace analysis process and gives the user insightful information by looking at the model execution traces. HTA utilizes the following features to support the tasks above:
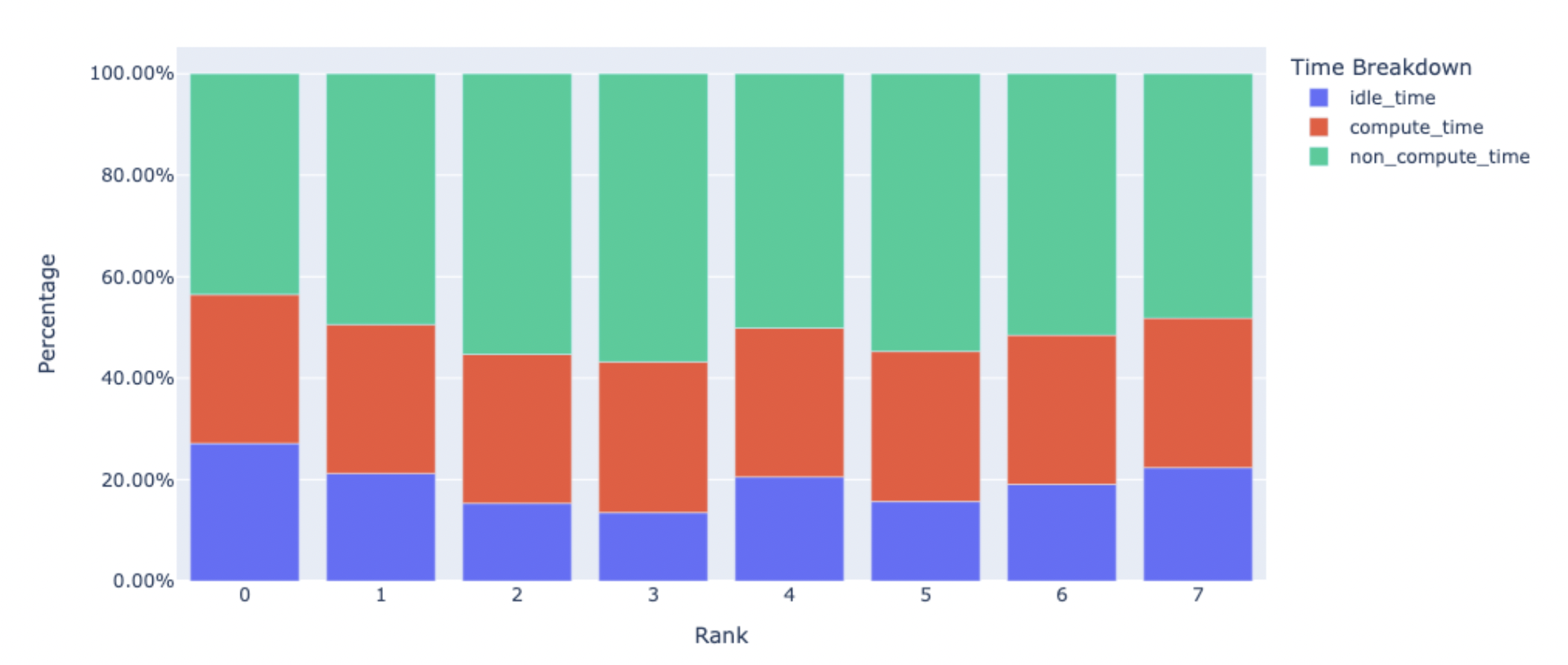
Temporal Breakdown: This feature provides a breakdown of the amount of time the GPUs spend throughout all ranks in terms of computation, communication, memory events, and even idle time spent.
Kernel Breakdown: This function separates the time invested in each of the three kernel types (COMM, COMP, and MEM) and arranges the time spent in increasing order of duration.
Kernel Duration Distribution: The distribution of the average time spent by a specific kernel across all ranks can be visualized by using bar graphs produced by HTA. The graphs also display the least and maximum time a certain kernel spends on a particular rank.
Communication Computation Overlap: When performing distributed training, many GPU devices must communicate and synchronize with one another, which requires a considerable chunk of time. To achieve high GPU efficiency, it is essential to prevent a GPU from being blocked as it waits for data from other GPUs. Calculating the computation-communication overlap is one method of assessing how much computation is impeded by data dependencies. This feature offered by the library helps compute the percentage of time that communication and computation overlap.
Augmented Counters (Queue length, Memory bandwidth): For debugging purposes, HTA creates augmented trace files that include statistics that show the memory bandwidth used as well as the number of unfinished operations on each CUDA stream (which is also known as queue length).
These key characteristics give users a glimpse into the functioning of the system and aid in their understanding of what is going on internally. The PyTorch team also intends to add more functionality in the near future that will explain why certain things are happening and potential strategies to overcome the bottlenecks. HTA has been made available as an open-source library to serve a larger audience. It can be used for various purposes, including deep learning-based recommendation systems, NLP models, and computer vision-related tasks. Detailed documentation for the library can be found here.
Check out the GitHub and Blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.