MetaICL: A New Few-Shot Learning Method Where A Language Model Is Meta-Trained To Learn To In-Context Learn

Large language models (LMs) are capable of in-context learning, which involves conditioning on a few training examples and predicting which tokens will best complete a test input. This type of learning shows promising results because the model learns a new task solely by inference, with no parameter modifications. However, the model’s performance significantly lags behind supervised fine-tuning. In addition, the results show high variance, which can make it difficult to engineer the templates required to convert existing tasks to this format.
Researchers from Facebook AI, the University of Washington, and the Allen Institute for AI have developed Meta-training for In-Context Learning (MetaICL), a new few-shot learning meta-training paradigm. In this approach, LM is meta-trained to learn in context, conditioning on training instances to recover the task and generate predictions.
In contrast to previous methods that use multi-task learning for better zero-shot performance at test time, MetaICM allows learning new tasks from k examples alone, without relying on task reformatting or task-specific templates.
MetaICL fine-tunes a pre-trained language model on a vast collection of tasks to learn in context, then tests it on completely new problems. It contains k + 1 training examples from a single job presented to the language model as a single sequence. The output of the last example is utilized to calculate the cross-entropy training loss. Each meta-training example corresponds to the test setup. Simply fine-tuning the model in this data set leads to superior in-context learning—the model learns to recover the task’s semantics from the given instances, as is required for in-context learning of a new task during testing.
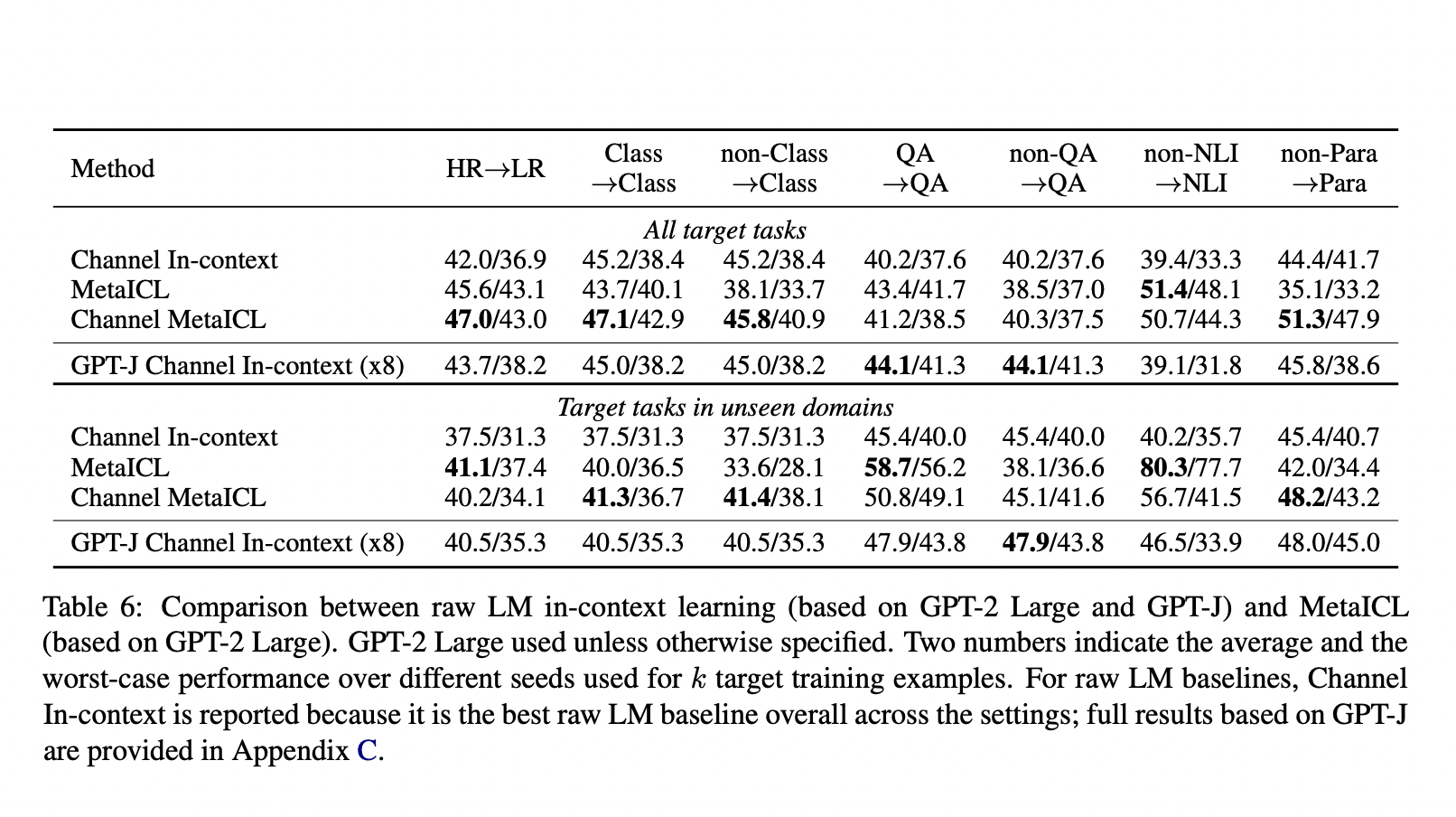
The team evaluated MetaICL’s performance on a number of tasks, including text categorization, question answering (QA), natural language inference (NLI), and paraphrase detection. They used Macro-F1 and Accuracy as assessment measures for classification and non-classification tasks, respectively, and compared MetaICL to baselines such as PMI 0-shot, PMI In-context, Channel Multi-task 0-shot, Oracle, and others. The results demonstrate that this approach surpasses all the existing frameworks.
When meta-training tasks and target tasks are distinct, gains over multi-task zero-shot transfer are more substantial. This shows that MetaICL allows the model to recover the task’s semantics in context during inference, even when the target has no resemblance to meta-training tasks.
One significant limitation of MetaICL and any in-context learning approach is that the length of each example is important. That is why longer examples are more difficult to employ.
The researchers believe their work is especially important when dealing with target tasks that differ from meta-training tasks in domain shifts. According to the team, future MetaICL research and development should focus on determining which meta-training activities are beneficial on target tasks and how to better combine MetaICL with human-written instructions.
Paper: https://arxiv.org/pdf/2110.15943.pdf
GitHub: https://github.com/facebookresearch/metaicl
Demo: http://qa.cs.washington.edu:2021/
Suggested

Credit: Source link
Comments are closed.