Metrics Can Deceive, but Eyes Can Not: This AI Method Proposes a Perceptual Quality Metric for Video Frame Interpolation
The advancement in display technology has made our viewing experience more intense and pleasant. Watching something in 4K 60FPS is extremely satisfying than 1080P 30FPS. The first one immerses you in the content like you are witnessing it. Though, not everyone can enjoy this content as they are not easy to deliver. A minute of 4K 60FPS video costs around 6 times more than 1080P 30 FPS in terms of data, which is not accessible to many users.
Though, it is possible to tackle this issue by increasing the resolution and/or framerate of the delivered video. Super-resolution methods tackle increasing the resolution of the video, while video interpolation methods focus on increasing the number of frames within the video.
Video frame interpolation is used to add new frames in a video sequence by estimating the motion between existing frames. This technique has been widely used in various applications, such as slow-motion video, frame rate conversion, and video compression. The resulting video usually looks more pleasant.
In recent years, research on video frame interpolation has made significant progress. They can generate intermediate frames quite accurately and provide a pleasant viewing experience.
However, measuring the quality of interpolation results has been a challenging task for years. Existing methods mostly use off-the-shelf metrics to measure the quality of interpolation results. As video frame interpolation results often exhibit unique artifacts, existing quality metrics sometimes are not consistent with human perception when measuring the interpolation results.
Some methods have conducted subjective tests to have more accurate measurements but doing so is time-consuming, with the exception of a few methods that employ user studies. So, how can we accurately measure the quality of our video interpolation method? Time to answer that question.
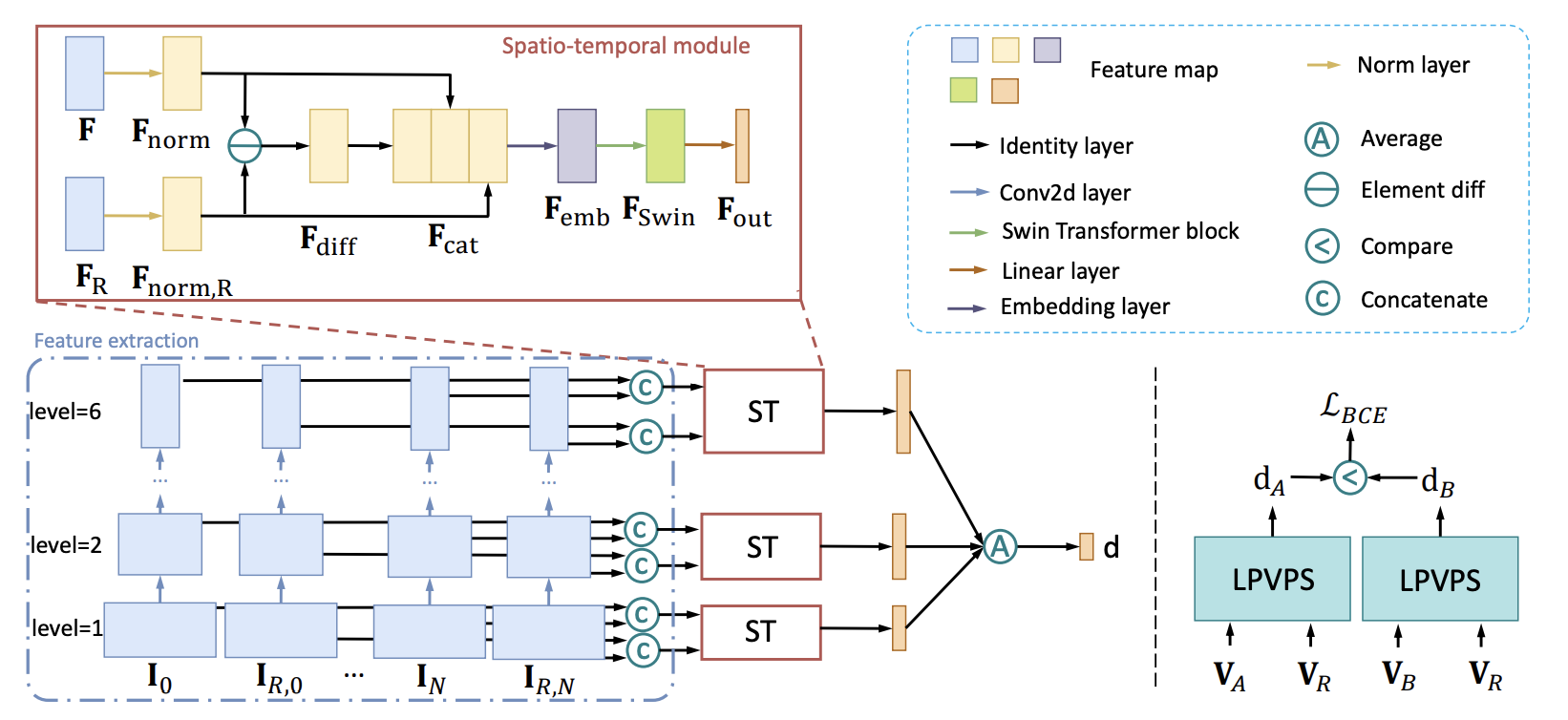
A group of researchers presented a dedicated perceptual quality metric for measuring video frame interpolation results. They designed a novel neural network architecture for video perceptual quality assessment based on the Swin Transformers.
The network takes as input a pair of frames, one from the original video sequence and one interpolated frame. It outputs a score that represents the perceptual similarity between the two frames. The first step to achieving this kind of network was preparing a dataset, and that’s where they started. They built a large video frame interpolation perceptual similarity dataset. This dataset contains pairs of frames from various videos, along with human judgments of their perceptual similarity. This dataset is used to train the network using a combination of L1 and SSIM objective metrics.
The L1 loss measures the absolute difference between the predicted score and the ground truth score, while SSIM loss measures the structural similarity between two images. By combining these two losses, the network is trained to predict scores that are both accurate and consistent with human perception. A major advantage of the proposed method is it does not rely on reference frames; thus, it can be run on client devices where we usually do not have that information available.
Check out the Paper. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.