Microsoft AI Introduces Turing Bletchley: A 2.5-Billion Parameter Universal Image Language Representation Model (T-UILR)

Language and vision are inextricably intertwined. When people hear the phrase, ‘beautiful sunrise on the beach,’ what people envision is something like the image below.

Even though this exact phrase can be described in many different ways in different languages, the visual representation will remain the same. This relationship is missed by models that focus solely on language. Sentences are nothing more than a grammatically correct series of words to these models. Traditional multi-modal models bind vision to a specific language (most typically English) and hence miss this universal feature of vision.
Microsoft introduces ‘Turing Bletchley, a 2.5-billion-parameter Universal Image Language Representation model (T-UILR) that can execute image-language tasks in 94 languages‘. T-Bletchley includes an image encoder and a universal language encoder that vectorizes input images and words to align semantically comparable pictures and writings. This model demonstrates incredibly impressive skills as well as a significant increase in visual language comprehension. The goal of T-Bletchley is to create a model that understands text and images as seamlessly as humans do.
T-Bletchley: Model Development
Dataset
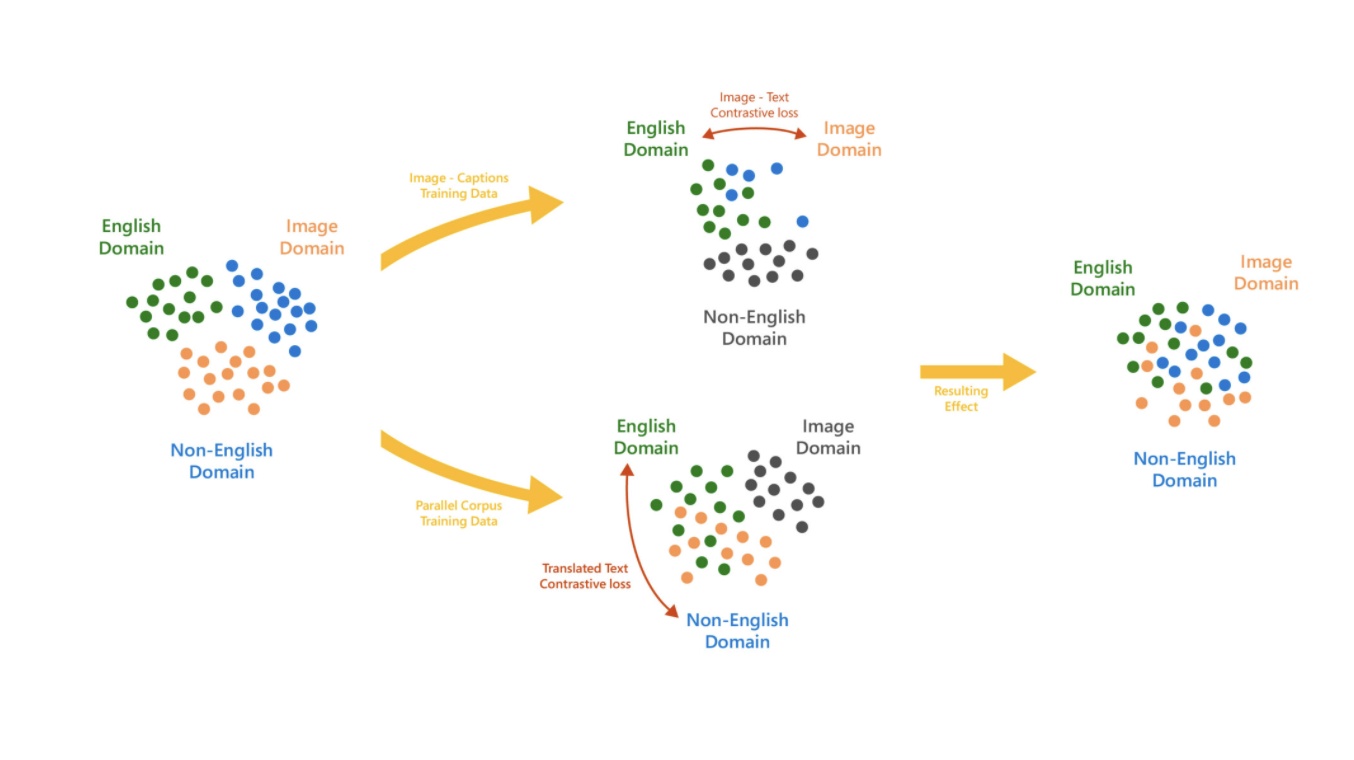
T-Bletchley was developed utilizing billions of image-caption pairs collected from the internet. The team trained the model on a parallel corpus of 500 million translation pairs to attain universality. It became possible to construct a language-agnostic vector representation of captions by adding the Translated Text Contrasted Task, which helped make the model considerably more general.
Model Architecture & Training
Images and captions were encoded separately, and the model was then trained by applying a contrastive loss on the generated image and text vectors. Similarly, each sentence from a translation pair was individually encoded, and a contrastive loss was applied to the resulting batch of vectors to construct a language-agnostic representation.
Even though the picture caption pairs were mainly in English, it was made possible to align subtitles in multiple languages with corresponding photos in this way.
T-Bletchley in Action
The following are some instances of the capabilities of T-Bletchley in an image retrieval system:
- Text-to-Image Universal Retrieval

- T-Bletchley can even extract photographs from non-English queries in English script

- T-Bletchley can decipher sentences in a variety of languages and scripts

- Understanding text within images

T-Bletchley can also recognize text within photos without the usage of OCR technology.
Reference: https://www.microsoft.com/en-us/research/blog/turing-bletchley-a-universal-image-language-representation-model-by-microsoft/
Demo: https://turing.microsoft.com/bletchley
Suggested
Credit: Source link
Comments are closed.