Microsoft AI Open-Sources DeepSpeed Chat: An End-To-End RLHF Pipeline To Train ChatGPT-like Models
There is no exaggeration in saying that ChatGPT-like concepts have had a revolutionary effect on the digital world. For this reason, the AI open-source community is working on some projects (such as ChatLLaMa, Alpaca, etc.) that aim to make ChatGPT-style models more widely available. These models are extremely flexible and can execute tasks such as summarization, coding, and translation at or above human levels of expertise.
Despite these impressive efforts, a publicly available end-to-end RLHF pipeline can still not train a robust ChatGPT-like model. Training efficiency is frequently less than 5% of these machines’ capabilities, even when access to such computing resources is available. Despite access to multi-GPU clusters, existing systems cannot support the simple, fast, and inexpensive training of state-of-the-art ChatGPT models with billions of parameters.
These restrictions originate from the fact that the sophisticated RLHF training pipeline used by InstructGPT is not well-supported by existing DL systems, which are optimized for more conventional pre-training and fine-tuning pipelines. To make ChatGPT-like models more widely available and RLHF training more easily accessible, the Microsoft team is releasing DeepSpeed-Chat, which offers an end-to-end RLHF pipeline to train ChatGPT-like models. It has the following features:
1. A Convenient Environment for Training and Inferring ChatGPT-Similar Models: InstructGPT training can be executed on a pre-trained Huggingface model with a single script utilizing the DeepSpeed-RLHF system. This allows user to generate their ChatGPT-like model. After the model is trained, an inference API can be used to test out conversational interactions.
2. The DeepSpeed-RLHF Pipeline: The DeepSpeed-RLHF pipeline largely replicates the training pipeline from the InstructGPT paper. The team ensured full and exact correspondence between the three steps a) Supervised Fine-tuning (SFT), b) Reward Model Fine-tuning, and c) Reinforcement Learning with Human Feedback (RLHF). In addition, they also provide tools for data abstraction and blending that make it possible to train using data from various sources.
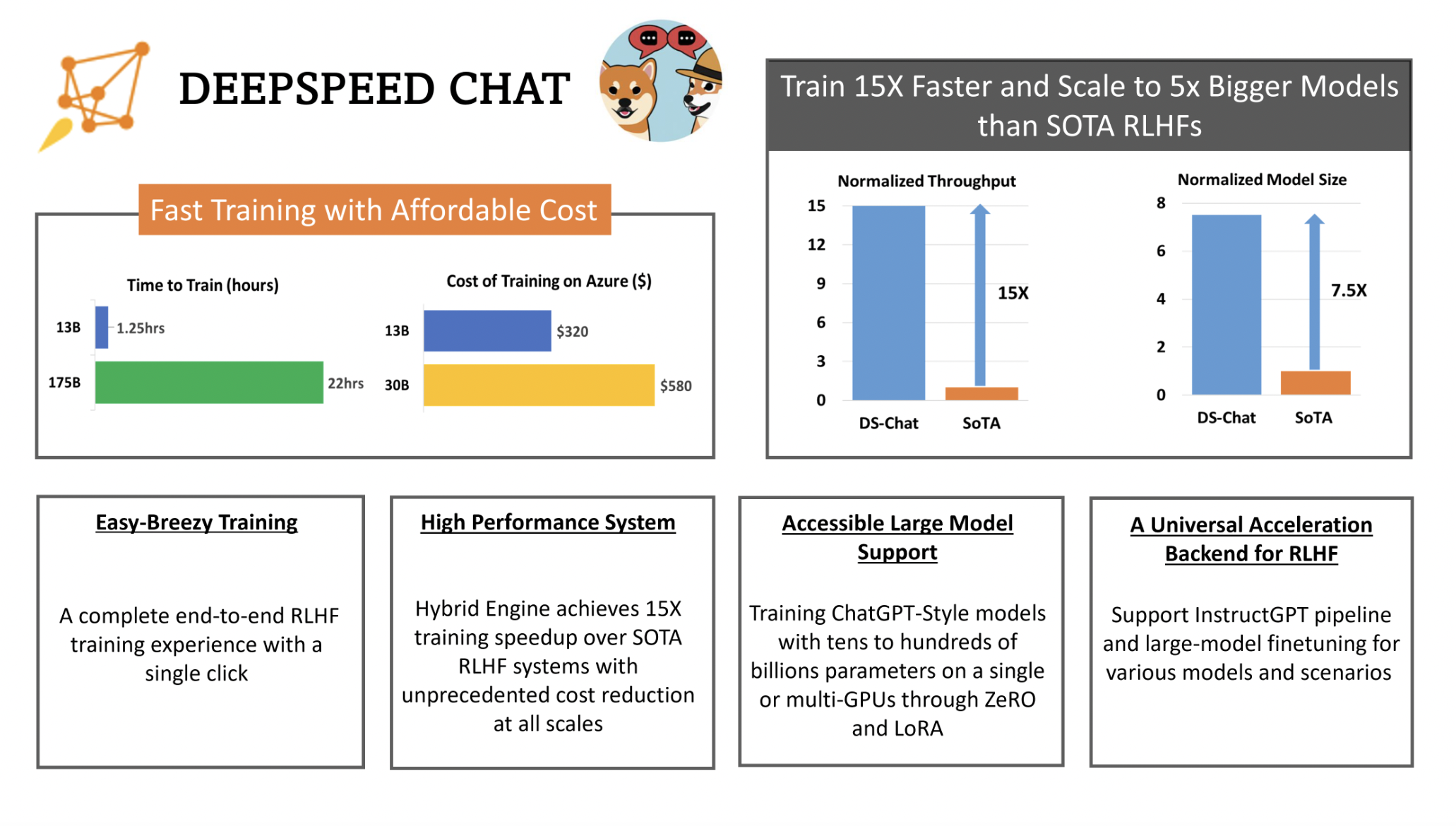
3. The DeepSpeed-RLHF System: Hybrid Engine (DeepSpeed-HE) for RLHF is a powerful and sophisticated system that combines the training and inference capabilities of DeepSpeed. The Hybrid Engine can easily switch between RLHF’s inference and training modes, taking advantage of DeepSpeed-Inference’s optimizations like tensor-parallelism and high-performance transformer kernels for generation, as well as RLHF’s many memory optimization strategies like ZeRO and LoRA. To further optimize memory management and data transfer across the various stages of RLHF, DeepSpeed-HE is additionally aware of the whole RLHF pipeline. The DeepSpeed-RLHF system achieves unprecedented efficiency at scale, allowing the AI community to quickly, cheaply, and conveniently access training on complex RLHF models.
4. Efficiency and Affordability: Because DeepSpeed-HE is over 15 times quicker than conventional systems, RLHF training may be completed quickly and cheaply.
5. Excellent Scalability: DeepSpeed-HE’s strong scalability on multi-node multi-GPU systems allows it to accommodate models with hundreds of billions of parameters.
6. Expanding Access to RLHF Education: DeepSpeed-HE enables data scientists without access to multi-GPU systems to build not just toy RLHF models but massive and powerful ones that can be deployed in real-world settings, all with just a single GPU for training.
The researchers have included a whole end-to-end training pipeline in DeepSpeed-Chat and modeled it after InstructGPT to make the training process as streamlined as possible.
The production process consists of three stages:
1. The pretrained language models are fine-tuned via supervised fine-tuning (SFT), in which human responses to various inquiries are carefully selected.
2. Next, the team performs “reward model fine-tuning,” which involves training a different (often smaller than the SFT) model (RW) using a dataset that includes human-provided rankings of numerous answers to the same inquiry.
3. Lastly, in RLHF training, the Proximal Policy Optimization (PPO) algorithm is used to further adjust the SFT model with the reward feedback from the RW model.
The AI community can now access DeepSpeed-Chat thanks to its open-sourced nature. On the DeepSpeed GitHub website, the researchers invite users to report issues, submit PRs, and participate in discussions.
Check out the Code. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 18k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.