Microsoft AI Research Introduces A New Reinforcement Learning Based Method, Called ‘Dead-end Discovery’ (DeD), To Identify the High-Risk States And Treatments In Healthcare Using Machine Learning

A policy is a roadmap for the relationships between perception and action in a given context. It defines an agent’s behavior at any given point in time.
Comparing reinforcement learning models for hyperparameter optimization is expensive and often impossible. As a result, on-policy interactions with the target environment are used to access the performance of these algorithms, which help in gaining insights into the type of policy that the agent is enforcing.
However, it’s known as an off-policy when the performance is unaffected by the agent’s actions. Off-policy Reinforcement Learning (RL) separates behavioral policies that generate experience from the target policy that seeks optimality. It also allows for learning several target policies with distinct aims using the same data stream or prior experience.
This policy determines the best policy regardless of the agent’s motivation. Therefore, it is especially important in safety-critical fields like robotics, education, and healthcare, where data-collecting should be regulated because it is costly or dangerous. Despite the considerable advancements made possible by off-policy RL paired with deep neural networks, the performance of these algorithms degrades dramatically in purely offline circumstances when there are no extra interactions with the environment.
Determining the best policy needs extensive trial and error of many options. Therefore, when the dataset is small and exploratory new data cannot be obtained for ethical or safety reasons; these issues are magnified. In such instances, poorly learned policies may overfit data-collection artifacts dramatically. Estimation errors caused by a lack of data may result in ill-timed or incorrect judgments, putting people in danger.
In the medical field, RL has been used to determine the best treatment plans based on the outcomes of previous treatments. Given a patient’s condition, these policies equate to advising what therapies to deliver. RL estimates of optimal policies are usually unreliable in healthcare, and most clinical environments prohibit the investigation of different treatment courses due to legal and ethical concerns.

Researchers from Microsoft, Adobe, MIT, and Vector Institute have developed Dead-end Discovery (DeD), a new Reinforcement Learning (RL) based technology that identifies therapies to avoid rather than which treatment to choose. This paradigm shift eliminates the difficulties that might occur when policies are constrained to stay near to potentially suboptimal recorded behavior. Studies show that the current techniques fail to produce a trustworthy policy when there isn’t enough exploratory behavior in the data. That is why the researchers use this information to limit the scope of the policy by retrospective analysis of observed consequences. This method has been proven to be more manageable when data is scarce.
DeD uses two complementary Markov Decision Processes (MDPs) with a specialized reward design to identify dead-ends, allowing the underlying value functions to have distinctive meaning. These value functions are independently assessed using Deep Q-Networks (DQN) to infer the probability of a negative outcome and the reachability of a positive outcome. Overall, DeD learns directory from offline data and establishes a formal link between the concept of value functions and the dead-end problem.
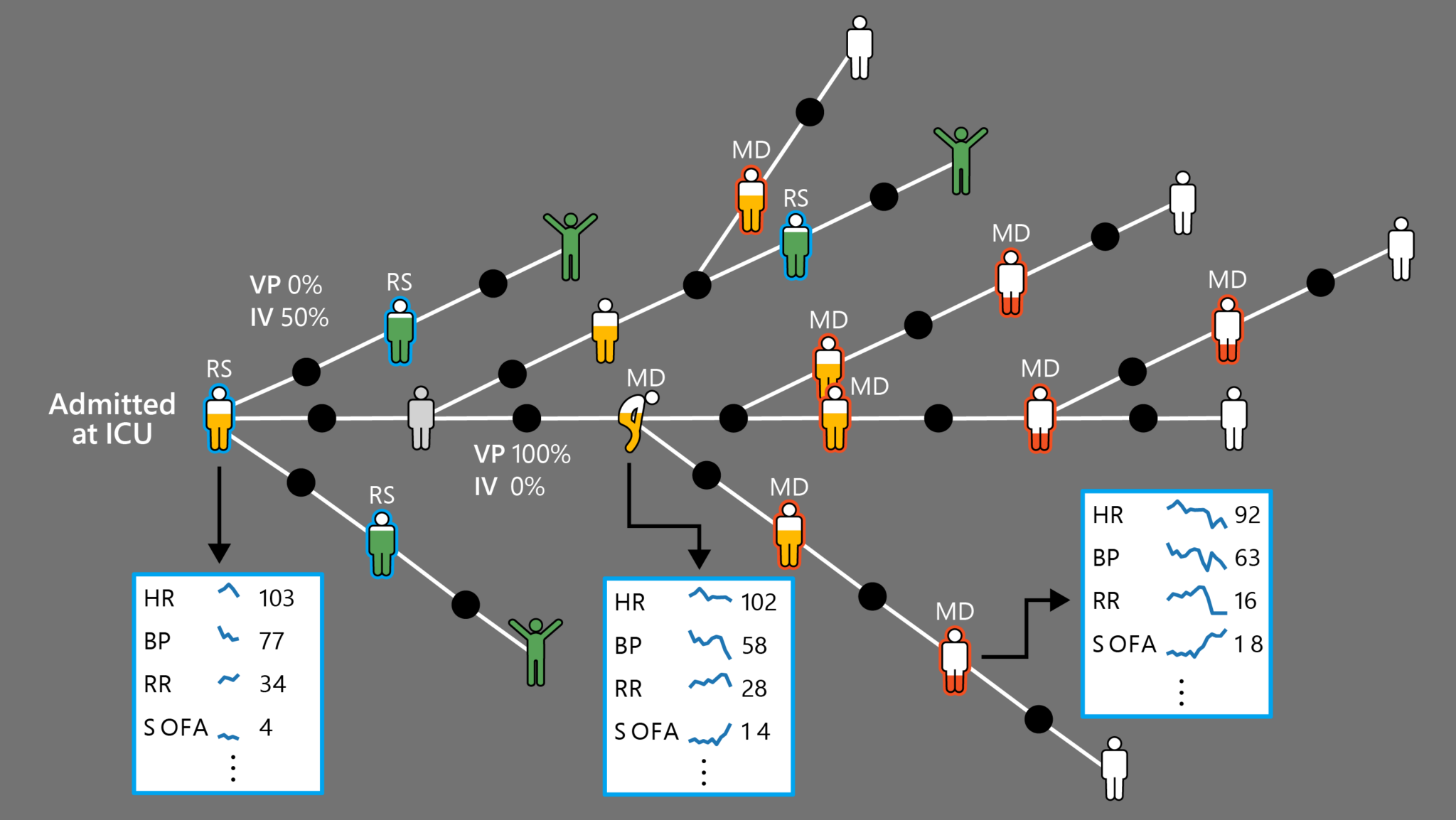
Treatment and start of sepsis are prominent issues in medical RL due to the condition’s high prevalence, physiological severity, high expense, and lack of understanding. The team tested DeD in a carefully created toy domain before evaluating real septic patient health records in an intensive care unit (ICU). Their findings show that 13% of treatments given to terminally ill patients lower their odds of life, with some treatments occurring as early as 24 hours before death. DeD’s estimated value functions can detect significant worsening inpatient health 4 to 8 hours before observed clinical interventions. Since several therapies within short time limits (10 to 180 minutes) after suspected commencement have been demonstrated to reduce sepsis mortality, early identification of inferior therapy alternatives is critical.
In addition to its use in healthcare, DeD can be employed in safety-critical RL applications in most data-constrained contexts where collecting further exploratory data would be prohibitively costly or immoral. DeD is built and trained in a generic manner that can be used for various data-constrained sequential decision-making problems.
Paper: https://proceedings.neurips.cc/paper/2021/file/26405399c51ad7b13b504e74eb7c696c-Paper.pdf
Github: https://github.com/microsoft/med-deadend
Reference: https://www.microsoft.com/en-us/research/blog/using-reinforcement-learning-to-identify-high-risk-states-and-treatments-in-healthcare/
Suggested

Credit: Source link
Comments are closed.