Microsoft AI Research Introduces DeepSpeed-MII, A New Open-Source Python Library From DeepSpeed That Speeds Up 20,000+ Widely Used Deep Learning Models
While open-source software has made AI accessible to more people, there are still two significant barriers to its widespread use: inference delay and cost.
System optimizations have come a long way and can substantially reduce latency and cost for DL model inference, but they are not immediately accessible. Many data scientists lack the expertise to correctly identify and implement the set of system optimizations relevant to a specific model, making low latency and low-cost inference primarily out of reach. The complex nature of the DL model inference landscape, including wide variations in model size, architecture, system performance characteristics, hardware requirements, etc., is the primary cause of this lack of availability.
A recent Microsoft research open-source DeepSpeed-MII, a new open-source python library developed by the company to facilitate the widespread adoption of low-latency, low-cost inference of high-performance models. MII provides access to thousands of popular DL models with highly efficient implementations.
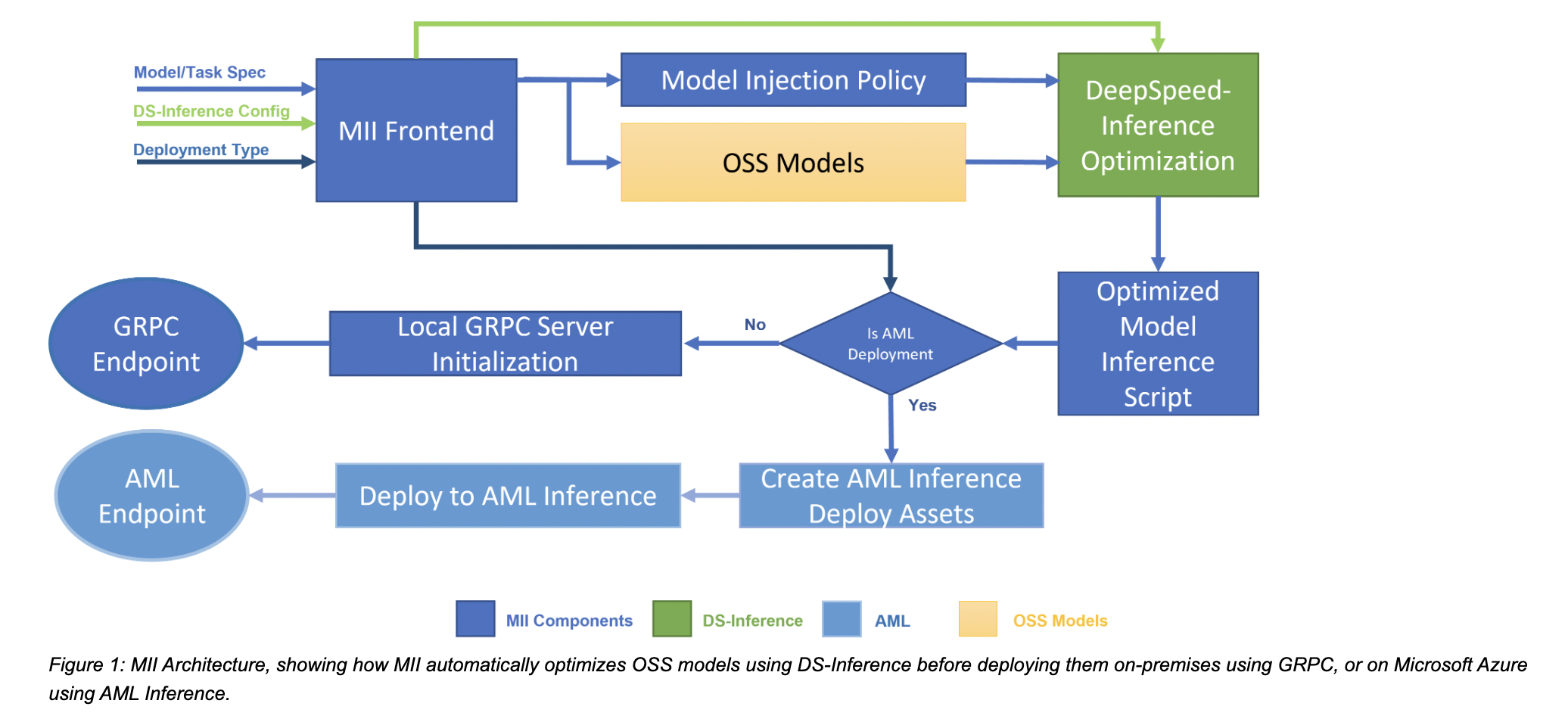
MII uses many DeepSpeed-Inference optimizations, like deep fusion for transformers, automated tensor-slicing for multi-GPU inference, on-the-fly quantization using ZeroQuant, and others that provide low latency/cost inference. It enables low-cost deployment of these models on-premises and on Azure via AML with only a few lines of code, all while providing state-of-the-art performance.
DeepSpeed-Inference is the engine that drives MII under the hood. MII automatically applies DeepSpeed-system Inference’s optimizations to minimize latency and maximize throughput based on the model type, size, batch size, and available hardware resources. To accomplish this, MII and DeepSpeed-Inference utilize one of many pre-specified model injection rules, which allows for the determination of the underlying PyTorch model architecture and the subsequent replacement with an optimized implementation. As a result, MII’s thousands of popular supported models gain instant access to DeepSpeed-comprehensive Inference’s set of optimizations.
Thousands of transformer models are accessible from several open-sourced model repositories, including Hugging Face, FairSeq, EluetherAI, etc. MII supports various applications like text creation, question answering, classification, etc. It works with extremely complex models with hundreds of millions of parameters, including those based on the BERT, RoBERTa, GPT, OPT, and BLOOM architectures. In addition, modern methods of image creation are supported, such as Stable Diffusion.
Inference workloads can be either latency critical, where the major goal is to minimize latency, or cost sensitive, where the primary goal is to minimize cost.
There are two DeepSpeed-Inference variants that MII can use. The first, ds-public, is included in the public DeepSpeed library and includes most of the aforementioned improvements. The second, ds-azure, is accessible to all Microsoft Azure users via MII and provides deeper connectivity with Azure. MII instances can be called utilizing the two DeepSpeed-Inference variations MII-Public and MII-Azure.
Compared to the open-source PyTorch implementation (Baseline), MII-Public and MII-Azure provide significant latency and cost reductions. However, for specific generative workloads, they can have distinct performances. MII can reduce latency by up to 6x for various open-source models across various workloads, making it ideal for latency-critical cases where a batch size of 1 is commonly employed. The team employed a large batch size that maximizes the baseline and MII throughput to get the lowest cost. The results show that expensive language models like Bloom, OPT, etc., can drastically reduce inference costs by using MII.
MII-Public can run locally or on any cloud service. MII develops a minimal GRPC server and supplies a GRPC inference endpoint for questions to aid in this deployment. MII can be used with Azure using AML Inference.
The researchers hope that their work will support a wide range of models. They believe that MII will enable a wider infusion of powerful AI skills into various applications and product offers by instantly reducing the latency and cost of inferencing.
Reference: https://www.microsoft.com/en-us/research/project/deepspeed/deepspeed-mii/
![]()
Asif Razzaq is an AI Journalist and Cofounder of Marktechpost, LLC. He is a visionary, entrepreneur and engineer who aspires to use the power of Artificial Intelligence for good.
Asif’s latest venture is the development of an Artificial Intelligence Media Platform (Marktechpost) that will revolutionize how people can find relevant news related to Artificial Intelligence, Data Science and Machine Learning.
Asif was featured by Onalytica in it’s ‘Who’s Who in AI? (Influential Voices & Brands)’ as one of the ‘Influential Journalists in AI’ (https://onalytica.com/wp-content/uploads/2021/09/Whos-Who-In-AI.pdf). His interview was also featured by Onalytica (https://onalytica.com/blog/posts/interview-with-asif-razzaq/).
Credit: Source link
Comments are closed.