Microsoft AI Research Proposes a New Artificial Intelligence Framework for Collaborative NLP Development (CoDev) that Enables Multiple Users to Align a Model with Their Beliefs
Although NLP models have demonstrated extraordinary strengths, they have challenges. The need to teach these models ideas is highlighted by unacceptable values buried in their training data, recurrent failures, or breaches of business standards. The phrase “religion does not connote sentiment” is an example of a notion that links a collection of inputs to desired behaviors. Similar to this, the larger idea of “downward monotonicity” in the domain of natural language inference (NLI) describes entailment relations when certain portions of statements are made more precise (for example, “All cats like tuna” implies “All small cats like tuna”). Introducing fresh training data that demonstrates the idea, such as introducing neutral phrases containing religious terms or adding entailment pairs that exhibit downward monotonicity, is the traditional method of teaching concepts to models.
It is difficult to guarantee that the data presented does not result in shortcuts, i.e., false correlations or heuristics, which allow models to make predictions without truly understanding the underlying concept, such as “all sentences with religious terms are neutral” or “going from general to specific leads to entailment.” The model may also overfit, failing to generalize from the supplied examples to the real notion, for instance, only recognizing pairings of the form (“all X…”, “all ADJECTIVE X…”). Not pairs like (“all animals eat” or “all cats eat”). Finally, shortcuts and overfitting both have the potential to interfere with the original data or other ideas, for example, by causing failures on statements like “I love Islam” or pairings like “Some cats like tuna,” “Some small cats like tuna,” etc.
In conclusion, operationalizing ideas is difficult because users frequently need help to foresee all concept borders and interactions. One potential option is asking subject matter experts to produce data that completely and accurately illustrates the concept as feasible, such as the GLUE diagnostics dataset or the FraCaS test suite. These datasets, however, are frequently expensive to produce, limited (and hence unsuitable for training), and incomplete since even specialists sometimes overlook important details and subtleties of a subject. Another method is to utilize adversarial training or adaptive testing, where users input data progressively while getting feedback from the model. These can reveal and address model flaws without requiring users to plan everything.
Contrarily, neither adversarial training nor adaptive testing directly address the idea of ideas, nor do they address how one concept interacts with another or with the original data. Users may need help to investigate idea borders properly. As a result, they need help to determine when a concept has been adequately covered or whether they have caused interference with other concepts. Researchers from Microsoft describe the Collaborative Development of NLP Models (CoDev) in this study. Instead of depending on a single user, CoDev uses the combined expertise of numerous users to cover a wide range of topics.
They depend on the idea that models display simpler behaviors in small regions and train a local model for each concept in addition to a global model incorporating the initial data and any extra ideas. The LLM is then directed to provide instances where the local and global models conflict. These instances are either in which the local model is not yet completely developed or in which the global model continues to produce conceptual mistakes due to overfitting or shortcut dependence. Both models are updated when users annotate these instances until convergence or until the idea has been learned in a fashion that does not contradict previous information or concepts (Figure 1).
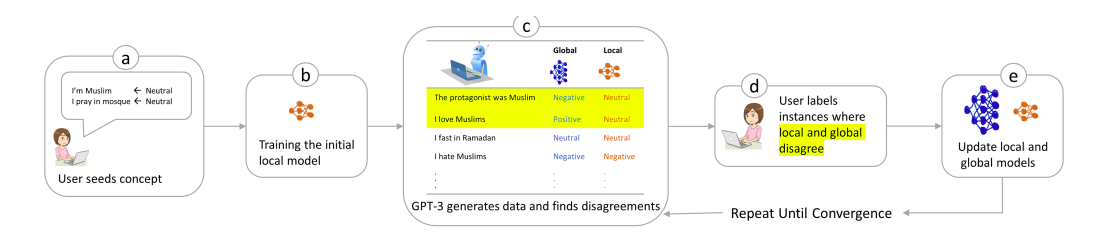
Figure 1: CoDev loop for operationalizing a single concept. (a) The user starts by providing some seed data from the concept and their labels, (b) they are used to learn a local concept model. GPT-3 is then prompted to generate new examples, prioritizing examples where the local model disagrees with the global model. (d) Actual disagreements are shown to the user for labeling, and (e) each label improves either the local or the global model. The loop c-d-e is repeated until convergence, i.e., until the user has operationalized the concept and the global model has learned it.
Every local model is a cheap specialist in its notion and is always developing. Users may investigate the boundaries between ideas and existent data thanks to the LLM’s quick local model predictions and diverse instances, which is an inquiry that would be difficult for users to carry out on their own. Their experimental findings demonstrate the efficiency of CoDev in operationalizing concepts and managing interference. They first demonstrate by identifying and resolving issues more thoroughly, CoDev beats AdaTest, a SOTA tool for debugging GPT-3-based NLP models. They then show that CoDev outperforms a model that exclusively depends on data gathering by operationalizing ideas even when the user starts with biased data.
By utilizing a simplified form of CoDev, wherein they iteratively choose samples from a pool of unlabeled data instead of GPT-3, they can compare the data selection process of CoDev to random selection and uncertainty sampling. They demonstrate that CoDev beats both baselines when teaching a sentiment analysis model about Amazon product reviews and an NLI model about downward- and upward-monotone ideas. Finally, they showed that CoDev assisted users in refining their concepts in pilot research.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.

Credit: Source link
Comments are closed.