Microsoft AI Researchers Develop ‘Ekya’ To Address The Problem Of Data Drift On The Edge Compute Box And Enables Both Retraining And Inference To Co-Exist On It

This article is based on the research paper 'Ekya: Continuous Learning of Video Analytics Models on Edge Compute Servers'. All credit for this research goes to the researchers of this paper from Microsoft, UC Berkeley and University of Chicago 👏👏👏 Please don't forget to join our ML Subreddit
Deep neural network (DNN) models for object recognition and classification, such as Yolo, ResNet, and EfficientNet, are used in video analytics applications such as urban mobility and smart automobiles. There is a symbiotic link between edge computing and video analytics, claiming that live video analytics is the “killer app” for edge computing. Edge devices come in various sizes and designs, but they are always resource-constrained compared to the cloud. Video analytics deployments send the videos to on-premises edge servers. The article handles the difficulty of supporting inference and retraining jobs on edge servers simultaneously, which necessitates navigating the fundamental tradeoff between the accuracy of the retrained model and the accuracy of the inference. Edge computation is preferred for video analytics because it eliminates the need for expensive network lines to broadcast videos to the cloud while simultaneously preserving video privacy. Edge computation has a finite amount of resources (e.g., with weak GPUs). The mismatch between the increasing rate of model compute needs, and the total cycles of processors exacerbate this problem. As a result, model compression is used in edge deployments.
Because of the limited resources at the edge, lightweight machine learning (ML) models are required. Using model specialization and compression techniques, the community has created edge models with significantly smaller compute and memory footprints (by 96x for object detector models). Such models are ideal for deployment at the edge.
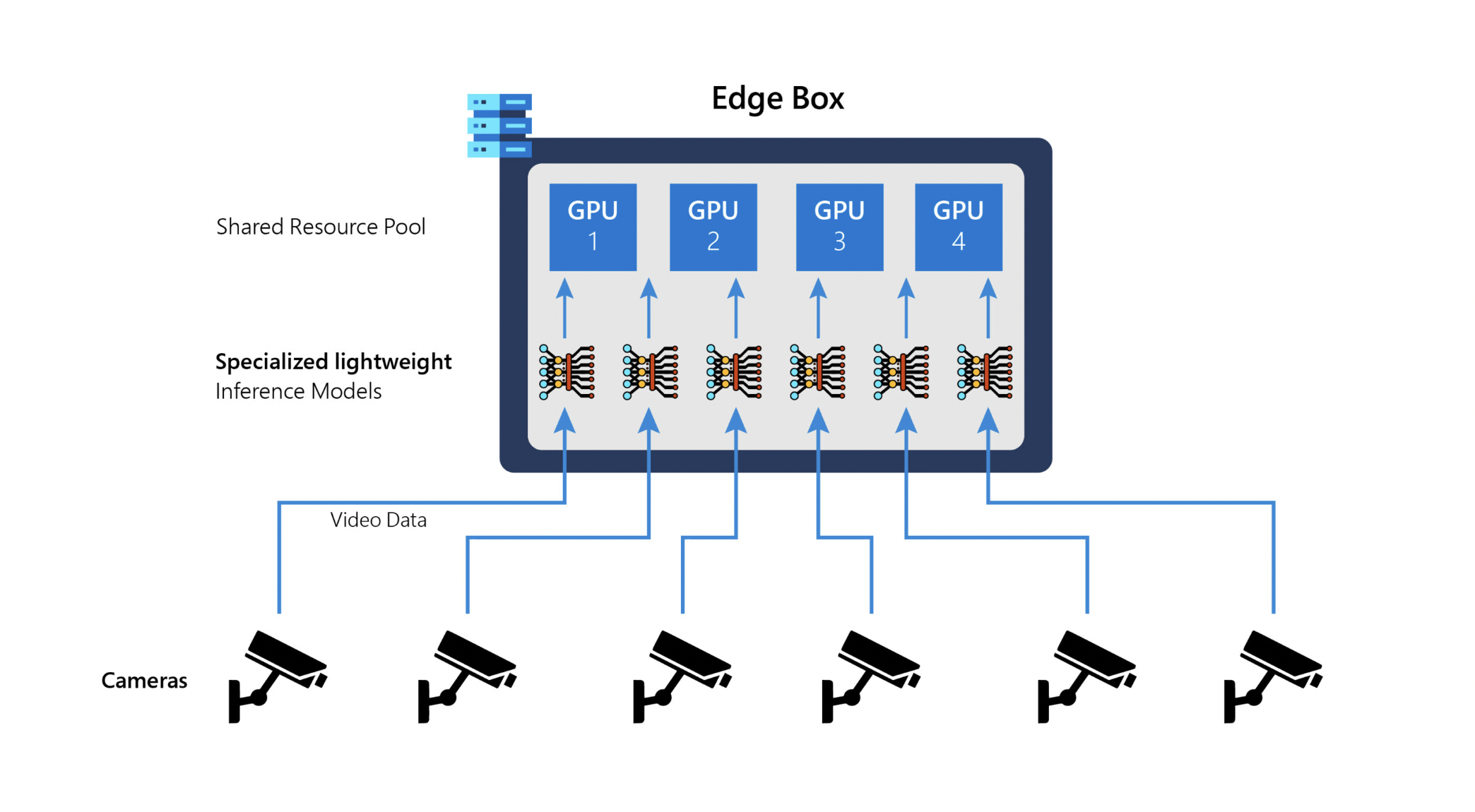
On-premises edge servers are often used to analyze videos in video analytics implementations (e.g., from AWS or Azure). A typical edge server may handle tens of video streams, such as those from building cameras, and each stream has its specialized model (see Figure 1). Edge computing is used in video analytics applications for the following reasons. 1) Edge deployments are typical in places where the uplink network to the cloud is prohibitively expensive for shipping continuous video feeds, such as on oil rigs with expensive satellite networks or in smart cars with data-limited cellular networks. 2) There are outages in network links outside of the edge sites. Edge compute ensures that data is not lost in the event of a cloud outage and that disruptions are avoided. 3) Videos frequently contain sensitive and personal information that users do not want to be uploaded to the cloud (e.g., many EU cities legally mandate that traffic videos be processed on-premise). As a result, it is preferable to execute both inference and retraining on edge compute device rather than relying on the cloud for network cost and video privacy. Cloud-based solutions are slower and have poorer accuracies than edge deployments with conventional bandwidths.


So far, everything has gone smoothly, but data drift is the story’s villain! This is a phenomenon in which real-time data in the field differs dramatically from the training data. Continuous model retraining – Continuous learning is a promising strategy for dealing with data drift. Even though some previous information is kept, the edge DNNs are incrementally retrained on new video samples. Continuous learning techniques retrain DNNs regularly; the time between two retraining is called the “retraining window,” and a sample of the data accumulated during each window is used for retraining. This continuous learning aids the compressed models in maintaining their high accuracy.
Ekya is a solution for data drift on edge compute boxes. On limited edge resources, continuous training necessitates making informed decisions about when to retrain each video stream’s model, how many resources to allocate, and what configurations to utilize. Making these choices brings two difficulties. First, the decision space of multi-dimensional configurations and resource allocations is computationally more complex than the multi-dimensional knapsack and multi-armed bandits, two fundamentally challenging problems. As a result, a thief scheduler is devised, a technique that makes joint retraining-inference scheduling practicable. Second, the scheduler requires the model’s actual performance (in terms of resource utilization and inference accuracy), which necessitates retraining for all configurations. Our micro-profiler solves this problem by retraining only a few select designs on a bit of data. The components of Ekya are shown in Figure 5.

Ekya’s performance is evaluated, and the following are the significant findings: 1) In both classification and detection, Ekya obtains up to 29 percent improved accuracy for compressed vision models compared to static retraining baselines. It would take four more GPU resources to meet Ekya’s accuracy for the baseline. 2) Ekya’s gains are primarily due to micro-profiling and the thief scheduler. The micro-profiler, in particular, estimates accuracy with low median errors of 5.8%. 3) When deciding on 10 video streams across 8 GPUs with 18 configurations per model for a 200s retraining window, the thief scheduler produces decisions in 9.4s. 4) Ekya delivers considerably higher accuracy without the network costs than alternative methods, such as reusing cached history models trained on similar data/scenarios and retraining the models in the cloud.
Paper: https://www.microsoft.com/en-us/research/uploads/prod/2021/07/nsdi22spring-final74.pdf
Github: https://github.com/edge-video-services/ekya
Source: https://www.microsoft.com/en-us/research/blog/dont-let-data-drift-derail-edge-compute-machine-learning-models/
Credit: Source link
Comments are closed.