Microsoft AI Researchers Developed a New Improved Framework ResLoRA for Low-Rank Adaptation (LoRA)
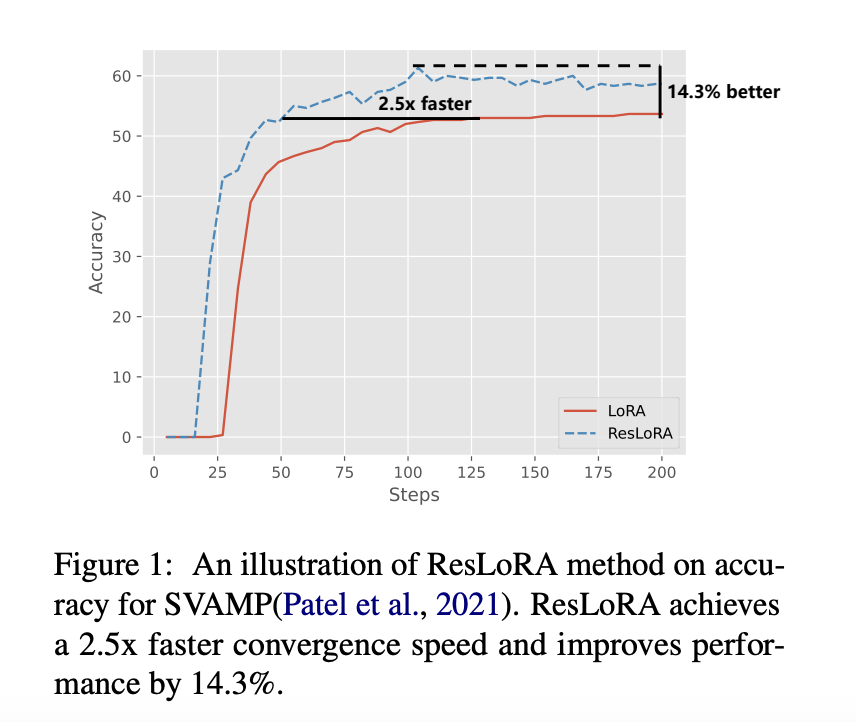
Large language models (LLMs) with hundreds of billions of parameters have significantly improved performance on various tasks. Fine-tuning LLMs on specific datasets enhances performance compared to prompting during inference but incurs high costs due to parameter volume. Low-rank adaptation (LoRA) is a popular parameter-efficient fine-tuning method for LLMs, yet updating LoRA block weights efficiently is challenging due to the model’s long calculation path.
Various parameter-efficient fine-tuning (PEFT) methods have been proposed to address this issue. PEFT methods freeze all parameters in the original model and only tune a few in the newly added modules. Among them, one of the most popular PEFT methods is LoRA. LoRA freezes most parameters in the original model and only updates a few in added modules. It employs low-rank adaptation, merging matrices parallel to frozen linear layers during inference. However, LoRA’s long backward path poses challenges. Integrating LoRA with ResNet and Transformers introduces design complexities, impacting gradient flow during training.
Researchers from the School of Computer Science and Engineering, Beihang University, Beijing, China, and Microsoft have introduced ResLoRA, an improved framework of LoRA. ResLoRA mainly consists of two parts: ResLoRA blocks and merging approaches. ResLoRA blocks add residual paths to LoRA blocks during training, while merging approaches convert ResLoRA to LoRA blocks during inference. Researchers also claimed that, to their knowledge, ResLoRA is the first work that combines the residual path with LoRA.
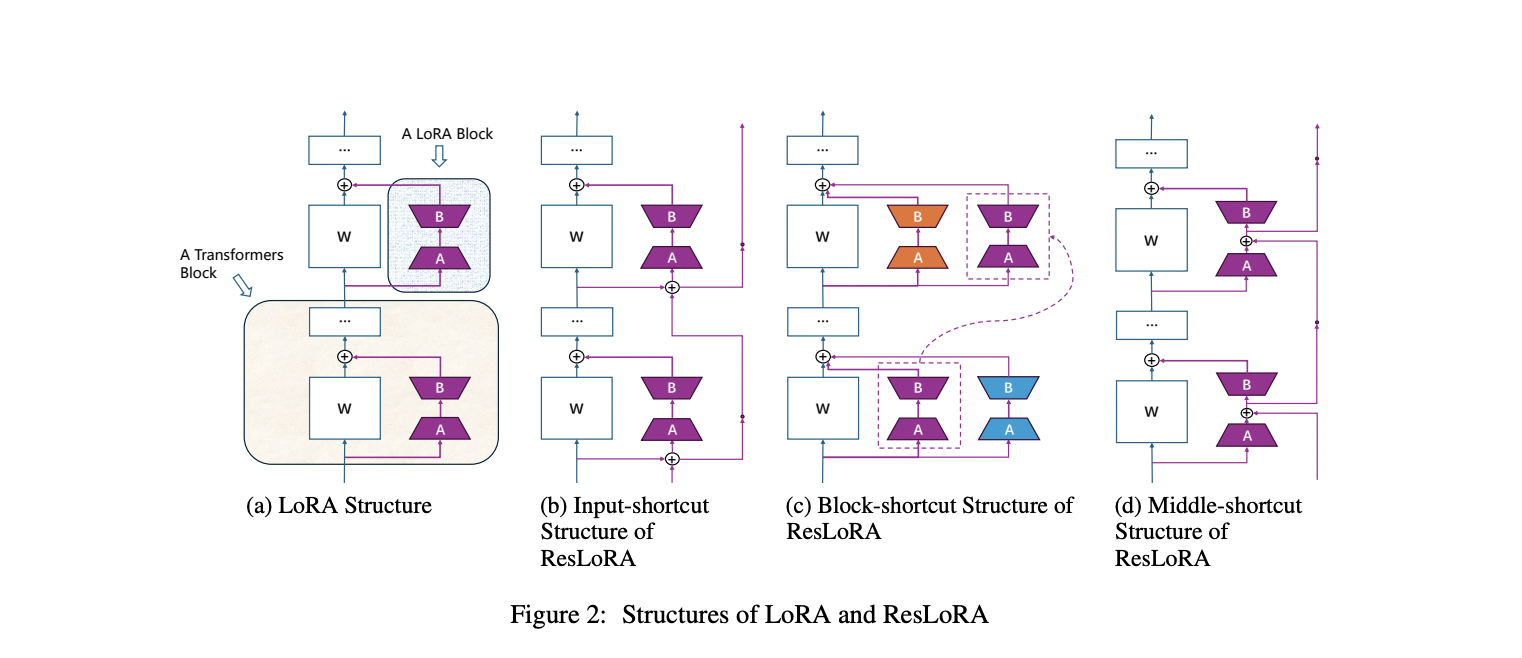
They designed three blocks inspired by ResNet: input-shortcut, block-shortcut, and middle-shortcut, adding residual paths to LoRA blocks. These structures aim to optimize gradient flow during training and are essential for efficient parameter tuning. An important issue arises as ResLoRA introduces a non-plain structure, unlike LoRA, which seamlessly merges with linear layers. To address this issue, they have designed a merging approach. For block-shortcut structures, merging relies on previous block weights. The precision of scaling factors, determined using Frobenius norms, ensures accurate model merging. Two approaches, based on input and block weights, facilitate seamless integration, minimizing latency in inference.
In extensive experiments spanning natural language generation (NLG) and understanding (NLU), ResLoRA outperforms LoRA variants such as AdaLoRA, LoHA, and LoKr. ResLoRA and ResLoRAbs consistently surpass LoRA across NLG and NLU benchmarks, showcasing improvements in accuracy ranging from 10.98% to 36.85%. ResLoRA also demonstrated faster training and superior image generation quality than LoRA in the text-to-image task.
To conclude, researchers from the School of Computer Science and Engineering, Beihang University, Beijing, China, and Microsoft have introduced ResLoRA, an enhanced framework for LoRA. ResLoRA introduces residual paths during training and employs merging approaches for path removal during inference. It outperforms original LoRA and other baseline methods across NLG, NLU, and text-to-image tasks. The results confirm ResLoRA’s effectiveness, achieving superior outcomes with fewer training steps and no additional trainable parameters.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link
Comments are closed.