Microsoft AI Researchers Introduce PPE: A Mathematically Guaranteed Reinforcement learning (RL) Algorithm For Exogenous Noise
This Article Is Based On The Research Paper 'Provable RL with Exogenous Distractors via Multistep Inverse Dynamics' and Microsoft article. All Credit For This Research Goes To The Researchers Of This Paper 👏👏👏 Please Don't Forget To Join Our ML Subreddit
Reinforcement learning (RL) is a machine learning training strategy that rewards desirable behaviors while penalizing undesirable ones. A reinforcement learning agent can perceive and comprehend its surroundings, act, and learn through trial and error in general. Although RL agents can heuristically solve some problems, such as assisting a robot in navigating to a specific location in a given environment, there is no guarantee that they will be able to handle problems in settings they have not yet encountered. The capacity of these models to recognize the robot and any obstacles in its path, but not changes in its surrounding environment that occur independently of the agent, which we refer to as exogenous noise, is critical to their success.
Existing RL algorithms are not powerful enough to handle exogenous noise effectively. They are either incapable of solving problems involving complicated observations or necessitate an impractically vast amount of training data to succeed. They frequently lack the mathematical assurance required to work on new exploratory topics. Because the cost of failure in the actual world might be considerable, this guarantee is desirable. To address these issues faced by an RL agent in the presence of exogenous noise, a team of Microsoft researchers introduced the Path Predictive Elimination (PPE) algorithm (in their paper, “Provable RL with Exogenous Distractors via Multistep Inverse Dynamics”), which guarantees mathematical assurance even in the presence of severe obstructions.
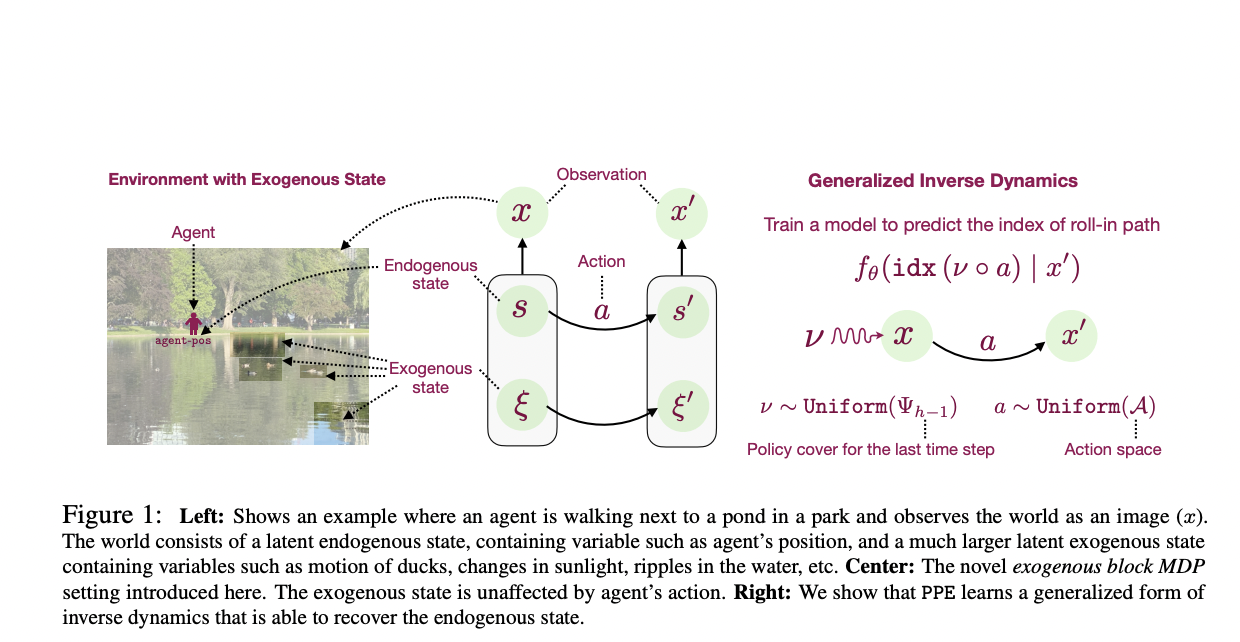
The agent or decision-maker has an action space with an ‘A’ number of actions in a general RL model, and it receives information about the world in the form of observations. An agent obtains more knowledge about its environment and a reward after performing a single action. The agent’s goal is to maximize the total reward. A real-world RL model must deal with the challenges of large observation spaces and complex observations. According to substantial research, observation in an RL environment is derived from a considerably more compact but hidden endogenous state. In their study, the researchers believed that endogenous state dynamics are near-deterministic. In most circumstances, doing a fixed action in an endogenous state always leads to the next endogenous state.

PPE is a quick and easy algorithm that uses a self-supervised ‘hidden state decoding’ approach. The agent trains a machine learning model called a decoder to extract the hidden endogenous state from an observation. It operates by teaching the agent a minimal number of pathways that will lead to all conceivable endogenous states. On the other hand, considering all alternative options can be overwhelming for the agent. By solving a novel self-supervised classification challenge, PPE removes redundant pathways that visit the same endogenous state. PPE works similarly to the breadth-first-search algorithm because the agent learns to explore all endogenous states that can be reached by performing a set of actions. In their study, the team looked at numerous model-free and model-based ways of optimizing the reward function.

While PPE is a significant advancement in Reinforcement Learning since it provides mathematical guarantees in the presence of exogenous noise, there is still room for improvement until we can answer every RL problem that contains exogenous noise. Questions about PPE’s performance on real-world issues, the necessity for substantial training datasets to enhance accuracy, and the assumptions made by the algorithm remain unresolved. Reinforcement Learning paves the way for a better tomorrow in various fields, ranging from automation, healthcare, and robotics to finance. On the other hand, Exogenous noise poses a significant difficulty in realizing the full potential of RL agents. The researchers anticipate that introducing PPE will serve as a springboard for further research on RL in the presence of exogenous noise.
Paper: https://www.microsoft.com/en-us/research/publication/provable-rl-with-exogenous-distractors-via-multistep-inverse-dynamics/
Source: https://www.microsoft.com/en-us/research/blog/ppe-a-fast-and-provably-efficient-rl-algorithm-for-exogenous-noise/?OCID=msr_blog_ExogenousBlockMDP_tw
Credit: Source link
Comments are closed.