Microsoft AI Unveils LLaVA-Med: An Efficiently Trained Large Language and Vision Assistant Revolutionizing Biomedical Inquiry, Delivering Advanced Multimodal Conversations in Under 15 Hours
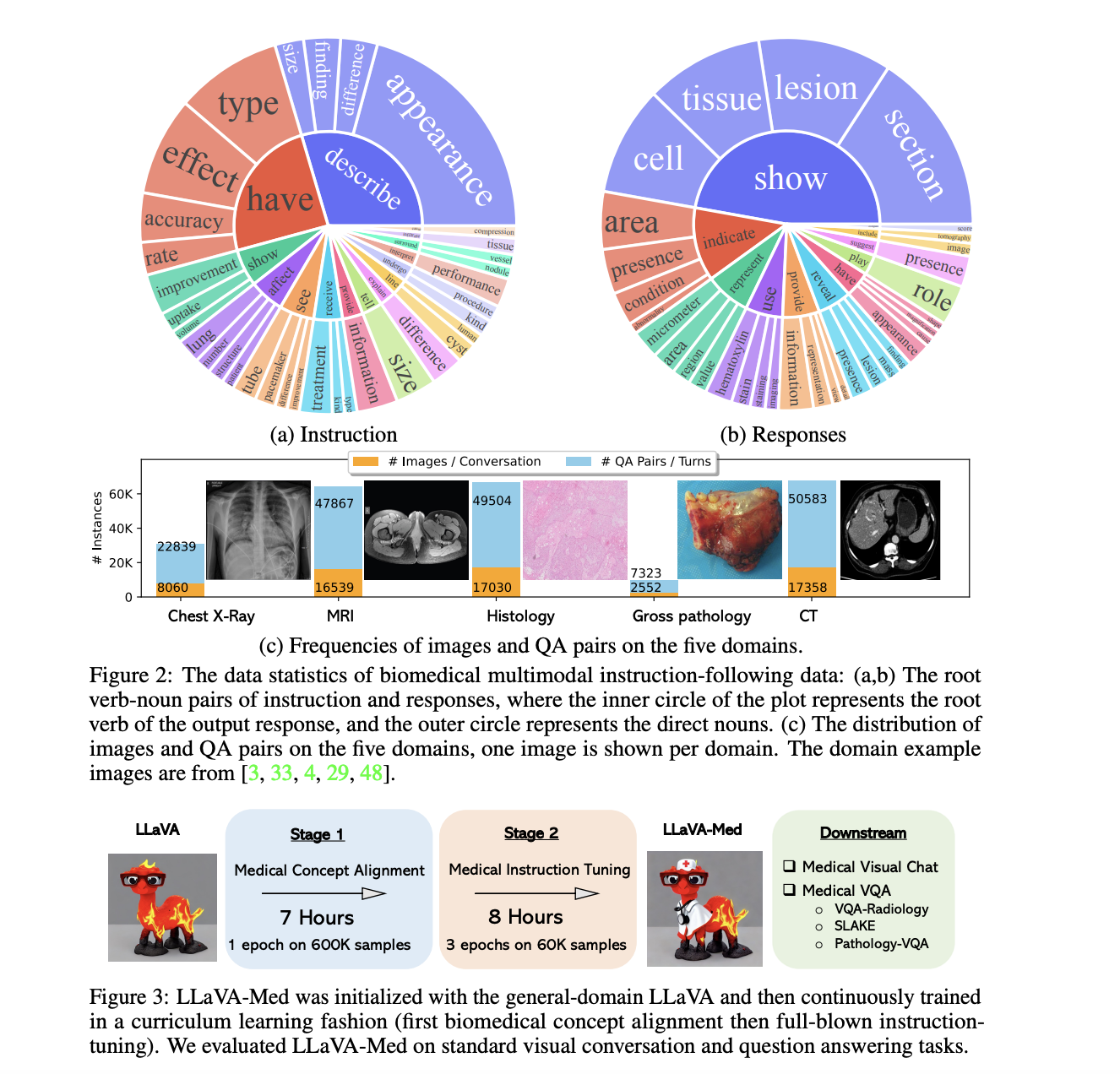
There is a lot of potentials for conversational generative AI to help medical professionals, but so far, the research has only focused on text. While advances in multi-modal conversational AI have been rapid because of billions of publicly available image-text pairings, such general-domain vision-language models still need more complexity when interpreting and chatting about biological pictures. The research team at Microsoft suggests a low-effort method for teaching a vision-language conversational assistant to respond to free-form inquiries about biomedical images. The team proposes a novel curriculum learning approach to the fine-tuning of a large general-domain vision-language model using a large-scale, broad-coverage biomedical figure-caption dataset extracted from PubMed Central and GPT-4 to self-instruct open-ended instruction-following data from the captions.
The model mimics the progressive process by which a layman gains biological knowledge by initially learning to align biomedical vocabulary using the figure-caption pairs as-is and then learning to master open-ended conversational semantics using GPT-4 generated instruction-following data. In less than 15 hours (with eight A100s), researchers can train a Large Language and Vision Assistant for BioMedicine (LLaVA-Med). With its multi-modal conversational capacity and ability to follow free-form instructions, LLaVA-Med is well-suited to answering questions regarding biological images. Fine-tuned LLaVA-Med achieves state-of-the-art performance on three benchmark biomedical visual question-answering datasets. The data on how well people follow directions and the LLaVA-Med model will be made public to advance multi-modal research in biomedicine.
The team’s key contributions are summed up as follows:
- Multi-modal medical training compliance statistics. By selecting biomedical picture-text pairs from PMC-15M and running GPT-4 to generate instructions from the text alone, they describe a unique data creation pipeline to generate diverse (image, instruction, output) instances.
- LLaVA-Med. Using the self-generated biomedical multi-modal instruction-following dataset, they offer a novel curriculum learning method to adapt LLaVA to the biomedical domain.
- Open-source. The biomedical multi-modal instruction-following dataset and the software for data generation and model training will be publicly available to promote further study in biomedical multi-modal learning.
The effectiveness of LLaVA-Med and the accuracy of the multi-modal biomedical instruction-following data obtained were the focus of the team’s investigations. Researchers look at two different contexts for evaluating research:
- How effective is LLaVA-Med as a general-purpose biomedical visual chatbot?
- Compared to the state-of-the-art methodologies, how does LLaVA-Med fare on industry benchmarks?
The team first proposes a novel data generation pipeline that samples 600K image-text pairs from PMC-15M, curates diverse instruction-following data through GPT-4, and aligns the created instructions to the model to solve the problem of a lack of multi-modal biomedical datasets for training an instruction-following assistant.
Researchers then introduce a new method of teaching LLaVA-Med’s curriculum. Specifically, they train the LLaVA multi-modal conversation model in broad domains and gradually shift their focus to the biomedical field. There are two phases to the training process:
- Specification of a Biomedical Idea Word embeddings is aligned with the relevant image attributes of a large set of innovative biological visual concepts.
- With its fine-tuned model based on biomedical language-image instructions, LLaVA-Med shows impressive zero-shot task transfer capabilities and facilitates natural user interaction.
To sum it up
The research team at Microsoft provides LLaVA-Med, a large language and vision model for the biomedical field. They use a self-instruct strategy to construct a data curation pipeline with language-only GPT-4 and external knowledge. Then they train the model on a high-quality biomedical language-image instruction-following dataset. LLaVA-Med beats earlier supervised SoTA on three VQA datasets on specific measures after fine-tuning, demonstrating great conversation abilities with domain knowledge. While LLaVA-Med is a big step in the right direction, they also recognize that it has hallucinations and a lack of depth of reasoning that plague many LMMs. Future initiatives will be towards making things more reliable and high-quality.
Check Out The Paper and Github. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.