Microsoft AI Unveils ‘TrOCR’, An End-To-End Transformer-Based OCR Model For Text Recognition With Pre-Trained Models
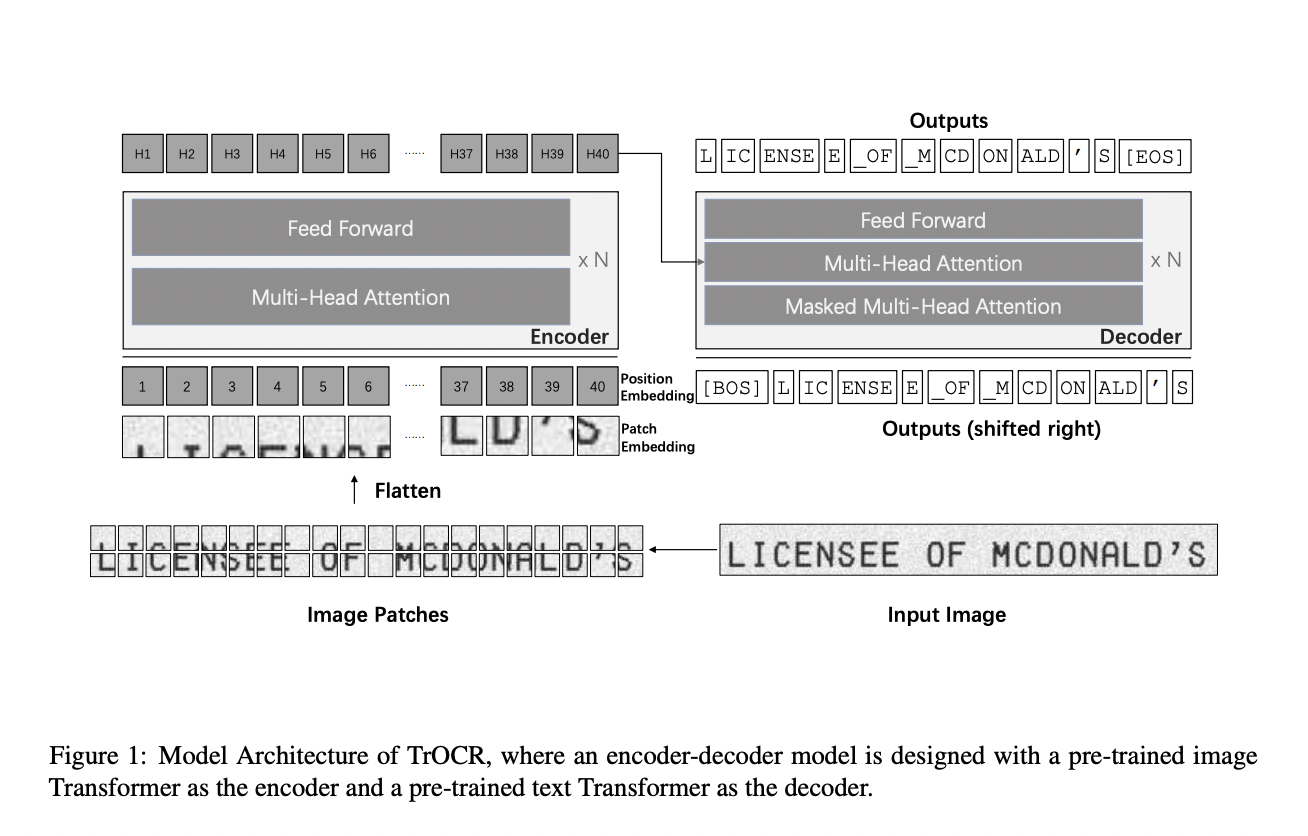

The problem of text recognition is a long-standing issue in document digitalization. Many current approaches for text recognition are usually built on top of existing convolutional neural network (CNN) models for image understanding and recurrent neural network (RNN) for char-level text generation. There are some latest progress records in text recognition by taking advantage of transformers, but this still needs the CNN as the backbone. Despite various successes by the current hybrid encoder/decoder methods, there is definitely some room to improve with pre-trained CV and NLP models.
Microsoft research team unveils ‘TrOCR,’ an end-to-end Transformer-based OCR model for text recognition with pre-trained computer vision (CV) and natural language processing (NLP) models. It is a simple and effective model which is that does not use CNN as the backbone. TrOCR starts with resizing the input text image into 384 × 384, and then the image is split into a sequence of 16 × 16 patches used as the input to image Transformers. The research team used standard transformer architecture with the self-attention mechanism on both encoder and decoder parts where word piece units are generated as recognized text from an input image.

In order to effectively train the TrOCR model, the research team initialized the encoder with pre-trained ViT-style models. At the same time, the decoder is being initialized with pretrained BERT-style models. Hence, the TrOCR model has three folds advantage:
- With TrOCR, you can use the power of pre-trained models to transform your images and text without needing an external language model.
- TrOCR is a game-changer because it does not require any sophisticated convolutional network for the backbone. This makes it very easy to implement and maintain, which will make AI training more accessible than ever before.
- Researchers are constantly improving upon their OCR algorithms to get better results. One such example is TrOCR, which has achieved state-of-the-art performance on both printed and handwritten text recognition tasks without any complex pre/post processing steps.
Paper: https://arxiv.org/pdf/2109.10282.pdf
Github: https://github.com/microsoft/unilm/tree/master/trocr
Suggested
Credit: Source link
Comments are closed.