Microsoft Announces The Release Of Their Two Billion Parameter Latest Vision-Language AI Model Called BEiT-3
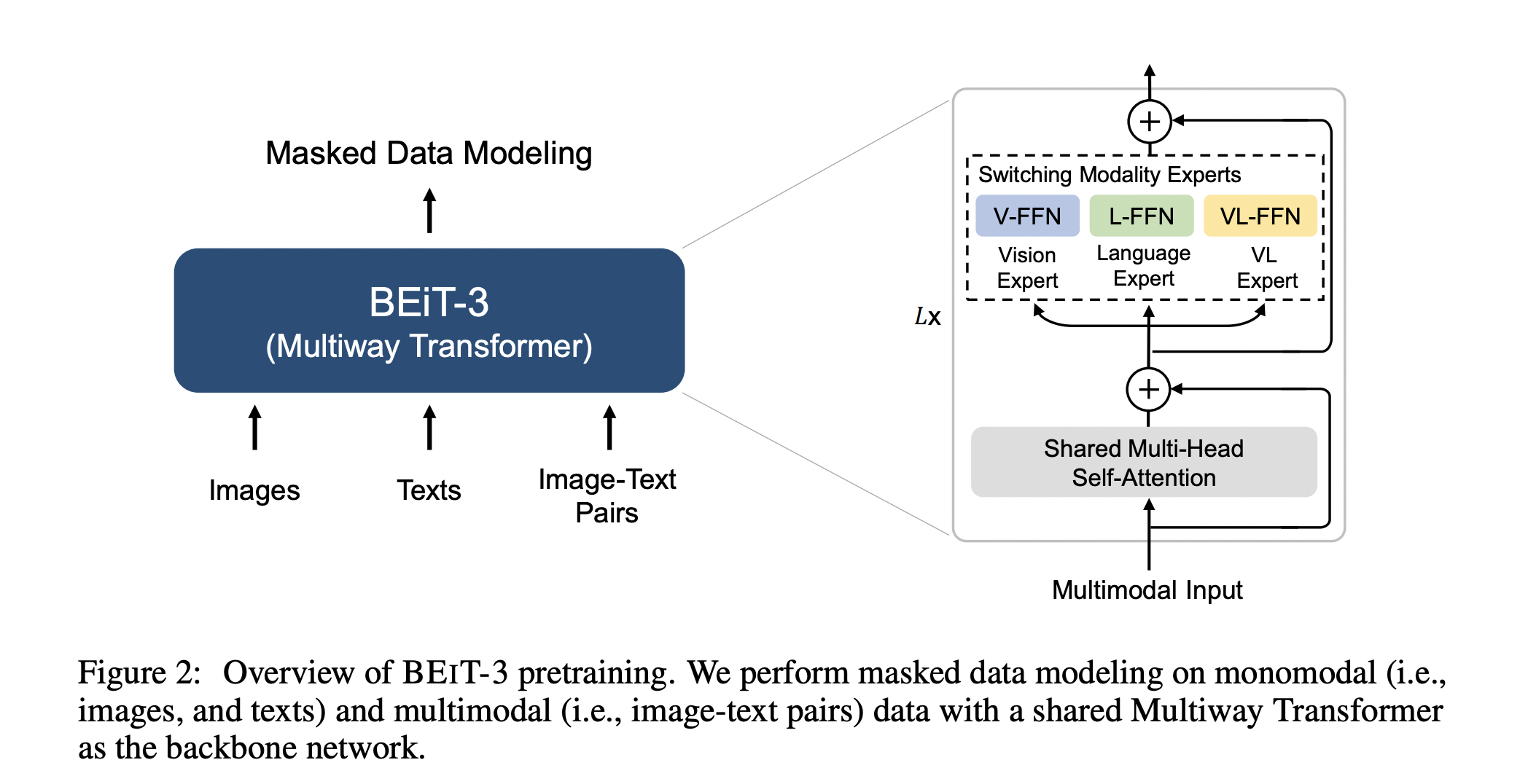
Microsoft’s Natural Language Computing (NLC) team recently introduced their latest vision-language AI model, BEiT-3, a Bidirectional Encoder representation from Image Transformers with 1.9 billion parameters.
BEiT-3’s central idea is to treat images as if they were written in a different language (which the authors refer to as “Imglish”), allowing the model to be pretrained with simply the masked language modeling (MLM) objective. Because of its unified architecture, BEiT-3 can support a wide variety of downstream tasks. In evaluation experiments, the model has already surpassed state-of-the-art records on several benchmarks, such as semantic segmentation, cross-modal retrieval, and visual question answering.
The transformer model has become the go-to framework for many NLP projects thanks to its promising results in many sectors. As a result, several scientists started using the Transformer for vision tasks, eventually merging NLP and vision into a single model. However, in addition to the typical MLM target, these multimodal systems typically include numerous pretraining objectives because they have separate encoder modules for the various inputs.
In contrast, the Multiway Transformer design used by BEiT-3 allows for a single self-attention module for visual and textual information. The information transmitted from the attention head is sent to an “expert” module tailored to a particular modality. Reduced GPU memory consumption is achieved by training batches of reduced size, made possible by the model pretraining’s exclusive focus on the MLM target.

BEiT-3 was pretrained on various publicly available text and picture datasets, such as ImageNet, COCO, and Wikipedia’s whole text and image content. This data included 160GB of text-only documents, 14M images, and 21M text-image pairs.
The researchers tested the model on various vision and vision-language benchmarks, such as semantic segmentation on the ADE20K, object identification, instance segmentation, picture captions and retrieval on COCO and Flickr30K, and visual question answering on VQAv2. A whole set of findings is accessible on Papers with Code which shows that BEiT-3 has achieved better outcomes than its predecessors on most assignments.
The straightforward efficiency of BEIT-3 bodes well for the future of expanding multimodal base models at a large scale. The team is working on pretraining multilingual BEIT-3 and adding other modalities (such as audio) to BEIT-3 in the future. They believe this will help converge large-scale pretraining across tasks, languages, and modalities.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, github and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.