Microsoft Proposes VALL-E X: A Cross-Lingual Neural Codec Language Model That Lets You Speak Foreign Languages With Your Own Voice
In the past few years, there have been some great advancements in the field of speech synthesis. With the rapid progress being made by natural language systems, the text is mostly chosen as the initial form to generate speech. A Text-To-Speech (TTS) system rapidly converts natural language into speech. Given a textual input, natural-sounding speech is produced. Currently, there are a number of texts to speech-language models that generate high-quality speech.
The traditional models are limited to producing the same robotic outputs, which are only according to a particular speaker in a particular language. With the introduction of deep neural networks in the approach, Text-to-speech models have already become more efficient with the added features of maintaining the stress and intonation in the generated speech. These audios seem more human-like and natural. But the feature of Cross-linguality of speech, which wasn’t touched upon yet, has now been added. A Microsoft team of researchers has presented a language model that exhibits cross-lingual speech synthesis performance.
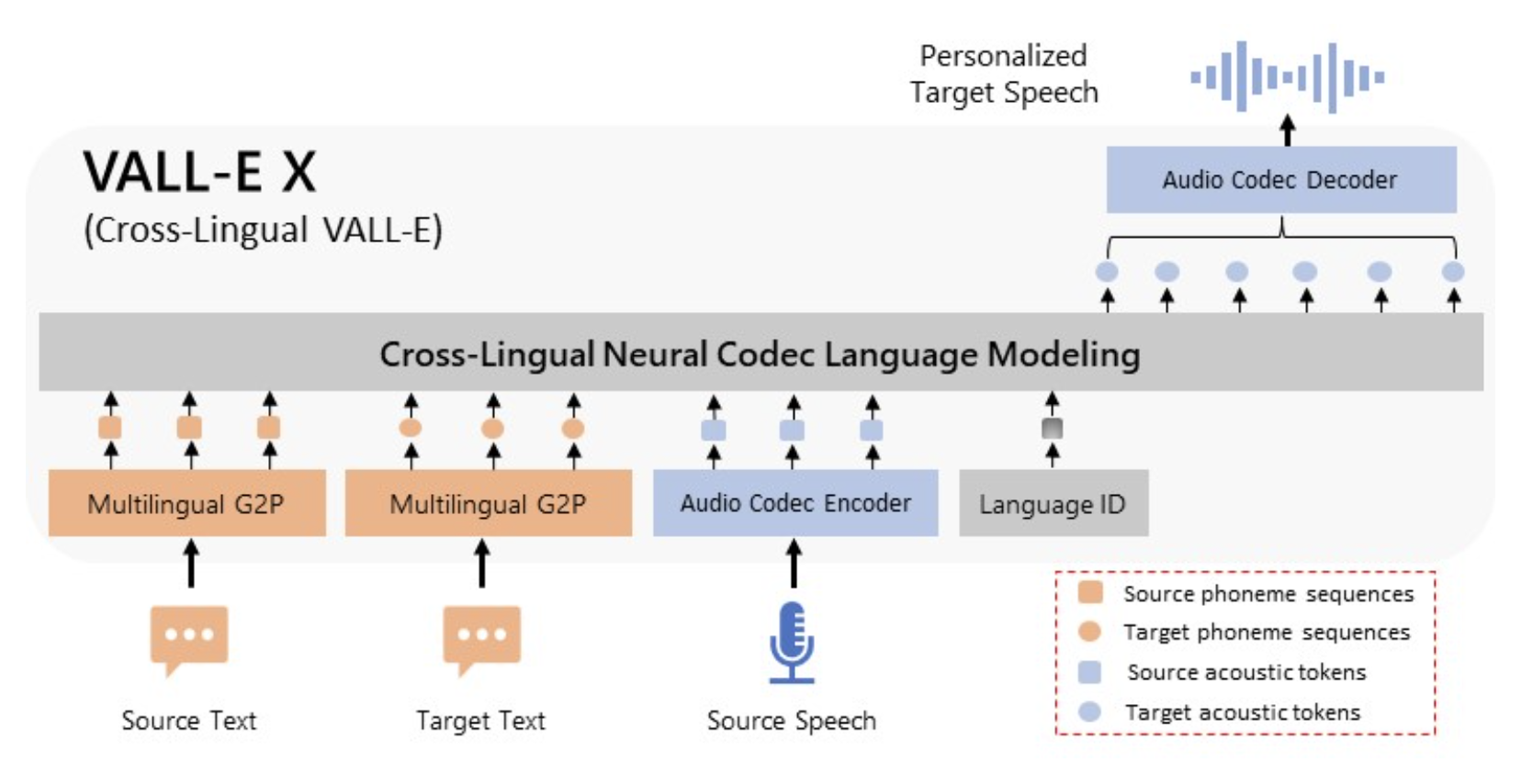
Cross-lingual speech synthesis is basically an approach for transmitting a speaker’s voice from one language to another. The cross-lingual neural codec language model that the researchers have introduced is called VALL-E X. It is an extended version of the VALL-E Text to speech model, which has been developed by acquiring strong in-context learning capabilities from the VALL-E TTS model.
The team has summarized their work as follows –
- VALL-E X is a cross-lingual neural codec language mode that consists of massive multilingual, multi-speaker, multi-domain unclean speech data.
- VALL-E X has been designed by training a multilingual conditional codec language model in order to predict the acoustic token sequences of the target language speech. This is done by using both the source language speech and the target language text as the fed prompts.
- The multilingual in-context learning framework allows the production of cross-lingual speech by VALL-E X. It maintains the unseen speaker’s voice, emotion, and speech background.
- VALL-E X overcomes the primary challenge of cross-lingual speech synthesis tasks: the foreign accent problem. It can generate speech in a native tongue for any speaker.
- VALL-E X has been applied to zero-shot cross-lingual text-to-speech synthesis and zero-shot speech-to-speech translation tasks. Upon experimentation, VALL-E X can beat the strong baseline regarding speaker similarity, speech quality, translation quality, speech naturalness, and human evaluation.
VALL-E X has been evaluated with LibriSpeech and EMIME for both English and Chinese languages, including English Text to speech prompted by Chinese speakers and Chinese TTS prompted by English speakers. It demonstrates high-quality zero-shot cross-lingual speech synthesis performance. This new model undoubtedly seems promising as it overcomes the foreign accent model and adds to the potential for cross-lingual speech synthesis.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.