Microsoft Research Introduces a General-Purpose Multimodal Foundation Model ‘BEIT-3,’ that Achieves State-of-the-Art Transfer Performance on Both Vision and Vision Language Tasks
The machine learning community has recently diverted its focus on the convergence of language, vision, and multimodal pretraining. The main intention behind this is to create general-purpose foundation models that can handle multiple modalities and be easily customized to various downstream tasks. A Microsoft research team recently presented BEiT-3 (BERT Pretraining of Image Transformers), a general-purpose state-of-the-art multimodal foundation model for both vision and vision-language tasks, in the paper Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks. The model improves the convergence technique from three aspects: the backbone design, the pretraining job, and the model scaling up, enabling it to achieve state-of-the-art performance.
The team proposed a cutting-edge shared Multiway Transformers network as the backbone of their architecture. The network has been pretrained on enormous monomodal and multimodal data to enable it to encode various modalities. The Multiway Transformer blocks use a pool of feed-forward networks for representing various modalities and a shared self-attention module that learns to align various modalities and offers deep fusion for multimodal activities. Under this common framework, BEiT-3 unifies masked “language” modeling on images, texts, and image-text pairs (also known as “parallel sentences”). The team uses a single masked data modeling aim on monomodal and multimodal data during the BEiT-3 pretraining procedure. They conceal text or image patches to train the model to anticipate the concealed tokens. They employ 21M image-text pairs and 15M photos for multimodal data, which they acquired from several open databases. The monomodal data consists of a 160GB text corpus and 14M pictures from ImageNet-21K.
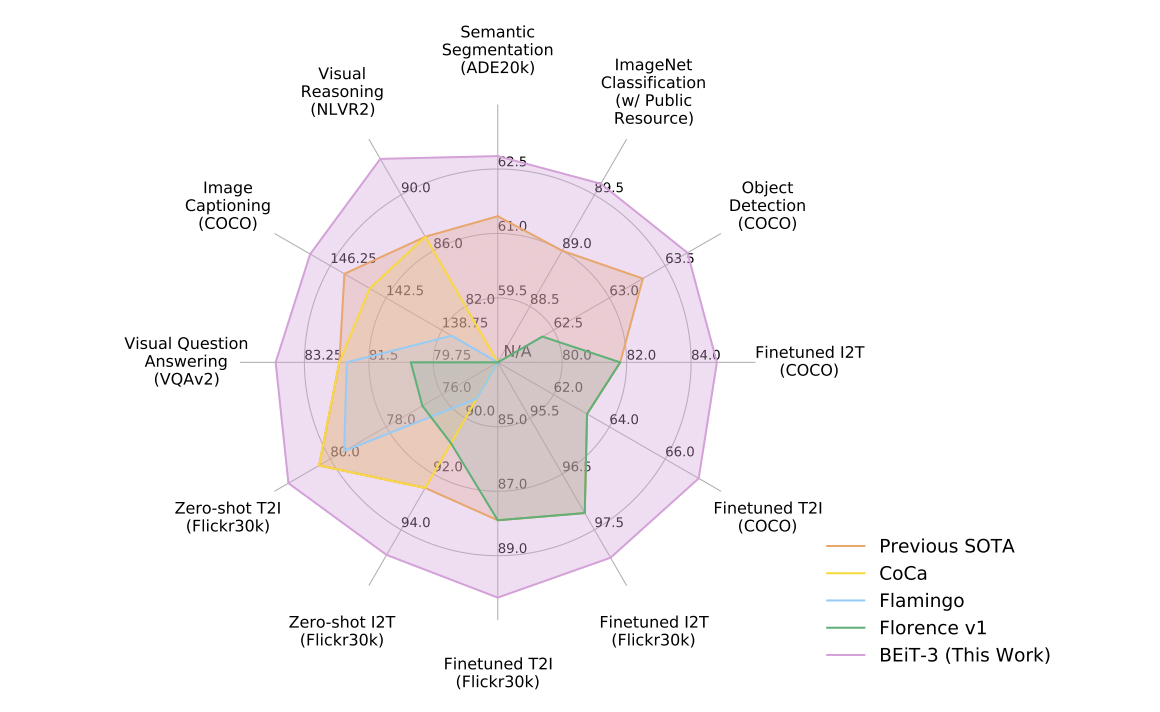
The researchers used BEiT-3 on well-known public benchmarks like Visual Question Answering (VQA), Visual Reasoning, Image Captioning, and Semantic Segmentation as part of their empirical investigation. According to these experimental assessments, BEiT-3 achieves state-of-the-art performance on language model-related tasks such as object detection, semantic segmentation, picture classification, visual reasoning, visual question-answering, image captioning, and cross-modal retrieval. BEIT-3’s central concept is that an image can be treated as a foreign language, allowing researchers to quickly and uniformly do masked “language” modeling over images, texts, and image-text pairs. The team also puts Multiway Transformers in a new light by showing how well they can represent various vision and vision-language tasks, making them an appealing choice for general-purpose modeling. The team thinks BEIT-3 is a good route for scaling up multimodal foundation models because it is straightforward and efficient. To facilitate a cross-lingual and cross-modality transfer, the researchers are working on pretraining multilingual BEIT-3 and adding other modalities like audio. Overall, the BEiT-3 proposal by Microsoft researchers presents a new, promising path for effectively scaling up multimodal foundation models while advancing such models’ development.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, github link and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.