Microsoft Research Introduces Florence-2: A Novel Vision Foundation Model with a Unified Prompt-based Representation for a Variety of Computer Vision and Vision-Language Tasks
There has been a noticeable trend in Artificial General Intelligence (AGI) systems toward using pre-trained, adaptable representations, which provide task-agnostic advantages in various applications. Natural language processing (NLP) is a good example of this tendency since sophisticated models demonstrate flexibility with thorough knowledge covering several domains and tasks with straightforward instructions. The popularity of NLP encourages a complementary strategy in computer vision. Unique obstacles arise from the necessity for broad perceptual capacities in universal representation for various vision-related activities. Whereas natural language processing (NLP) focuses mostly on text, computer vision has to handle complex visual data such as characteristics, masked contours, and object placement. In computer vision, achieving universal representation necessitates skillful handling of various challenging tasks arranged in two dimensions, as shown in Figure 1.
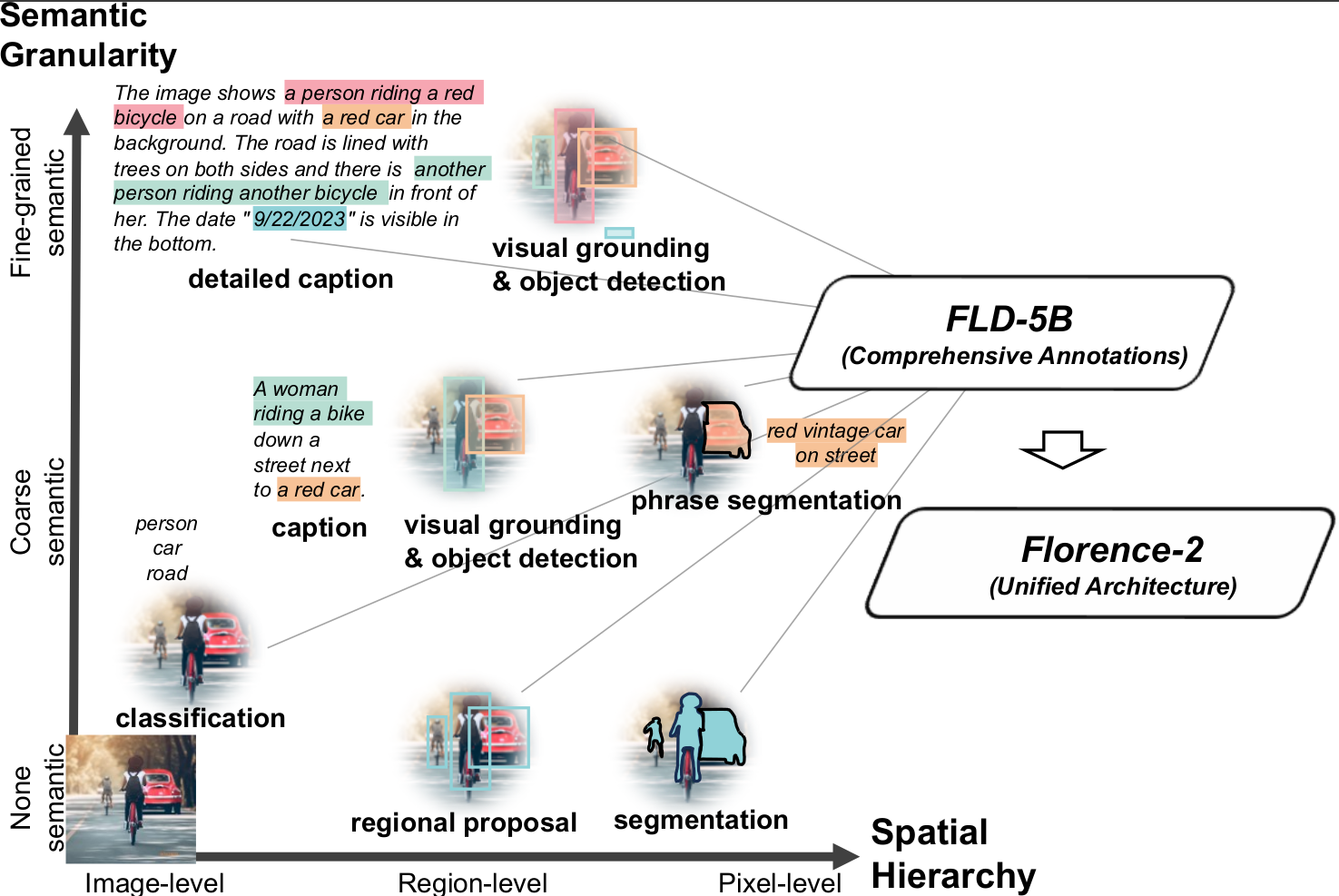
Figure 1
Spatial Hierarchy: The model has to recognize spatial information at different sizes, comprehending fine-grained pixel details and image-level ideas. To support the complex spatial hierarchy in vision, the model must be capable of managing a range of granularities.
Semantic Granularity: In computer vision, universal representation should cover a range of semantic granularities. The paradigm moves from abstract titles to more detailed explanations, providing flexible comprehension for various uses.
This pursuit is characterized by distinctiveness and substantial challenges. A key hurdle is the need for more, hindering the development of a foundational model capable of capturing the intricate nuances of spatial hierarchy and semantic granularity. Existing datasets, such as ImageNet, COCO, and Flickr30k Entities, tailored for specialized applications, are extensively labeled by humans. To overcome this constraint, it is imperative to generate extensive annotations for each image on a larger scale. Another challenge is the absence of a that seamlessly integrates spatial hierarchy and semantic granularity in computer vision. With task-specific design, traditional models perform well in tasks like semantic segmentation, object identification, and picture captioning. However, creating a complete, cohesive model that can adjust to different vision tasks in a task-independent way is crucial, even taking on new duties with little to no task-specific fine-tuning.
Through unified pre-training and network design, the model pioneers the integration of spatial, temporal, and multi-modal features in computer vision. The first evolutionary iteration excels in transfer learning through task-specific fine-tuning using customized adapters and pre-training with noisy text-image pairings. However, its reliance on big task-specific datasets and adapters results in gaps when it comes to tackling the two major issues mentioned above. In this work, researchers from Azure provide a universal backbone that is attained using multitask learning with rich visual annotations. This leads to a prompt-based, unified representation for various vision tasks, which successfully tackles the issues of incomplete comprehensive data and lack of a uniform architecture.
Large-scale, high-quality annotated data is necessary for multitask learning. Rather than depending on time-consuming human annotation, their data engine creates an extensive visual dataset named fld, which has 5.4B annotations for 126M photos. There are two effective processing modules in this engine. The first module departs from the conventional single and manual annotation strategy by using specialized models to annotate photos jointly and autonomously. Similar to the wisdom of crowds theory, many models collaborate to create a consensus, resulting in a more impartial and trustworthy picture interpretation. Using basic models that have been learned, the second module repeatedly refines and filters these automatic annotations.
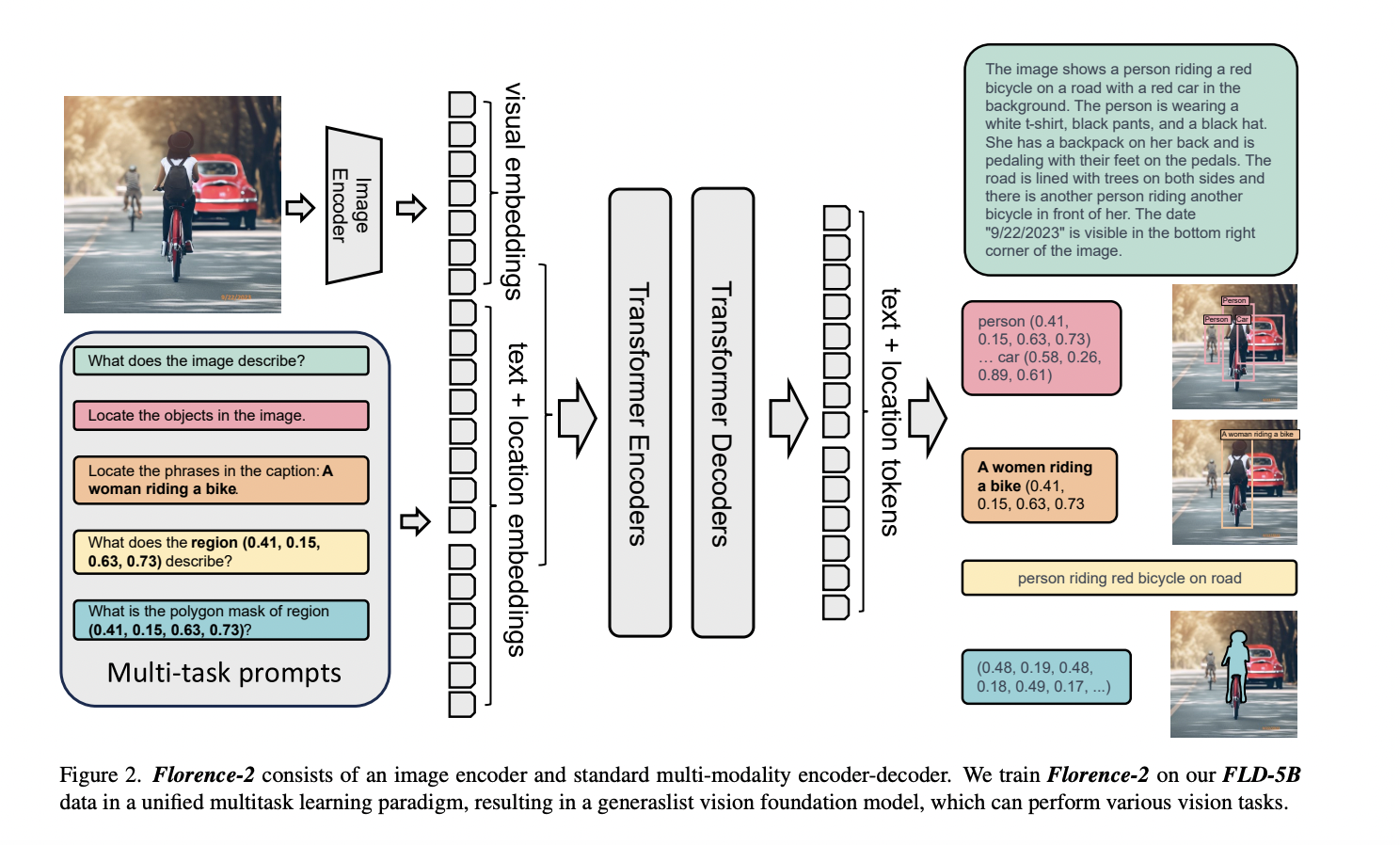
Their model uses a sequence-to-sequence (seq2seq) architecture, integrating an image encoder and a multi-modality encoder-decoder by leveraging this large dataset. This architecture supports a range of vision tasks without requiring task-specific architectural adjustments, in line with the NLP community’s goal of flexible model creation with a uniform foundation. Every annotation in the dataset is consistently standardized into textual outputs. This enables the consistent optimization of a single multitask learning strategy using the same loss function as the goal. The result is a flexible vision foundation model, or model, that can handle a range of functions, including object recognition, captioning, and grounding, all under the control of a single model with standardized parameters. Textual prompts are utilized to activate tasks, consistent with the methodology employed by large language models (LLMs).
Their method achieves a universal representation and has wide-ranging use in many visual tasks. Key findings consist of:
- The model is a flexible vision foundation model that provides new state-of-the-art zero-shot performance in tasks, including referencing expression comprehension on RefCOCO, visual grounding on Flick30k, and captioning on COCO.
- Notwithstanding its small size, it competes with more specialized models after being fine-tuned using publicly available human-annotated data. Most notably, the improved model sets new benchmark state-of-the-art scores on RefCOCO.
- The pre-trained backbone outperforms supervised and self-supervised models on downstream tasks, COCO object detection and instance segmentation, and ADE20K semantic segmentation. Their model, which uses the Mask-RCNN, DINO, and UperNet frameworks, delivers significant increases of 6.9, 5.5, and 5.9 points on COCO and ADE20K datasets, respectively and quadruples the training efficiency of pre-trained models on ImageNet.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.