Microsoft Research Introduces i-Code: An Integrative and Composable Multimodal Machine Learning Framework
This Article Is Based On The Research Paper 'i-Code: An Integrative and Composable Multimodal Learning Framework'. All Credit For This Research Goes To The Researchers 👏👏👏 Please Don't Forget To Join Our ML Subreddit
Machine learning has long aimed to provide models with intelligence comparable to humans. Humans can automatically blend multiple sensory inputs like visual, linguistic, and acoustic signals to generate a complete knowledge of their surroundings by virtue of their intelligence. Even the most robust pre-trained AI models, in contrast to humans, are incapable of doing so, confining themselves to one or two input modalities. Researchers have always been interested in developing effective multimodal learning strategies to support this viewpoint. In their new paper, to further support this idea, the Microsoft Azure Cognitive Services Research team proposes a self-supervised pretraining framework names i-Code: An Integrative and Composable Multimodal Learning Framework.

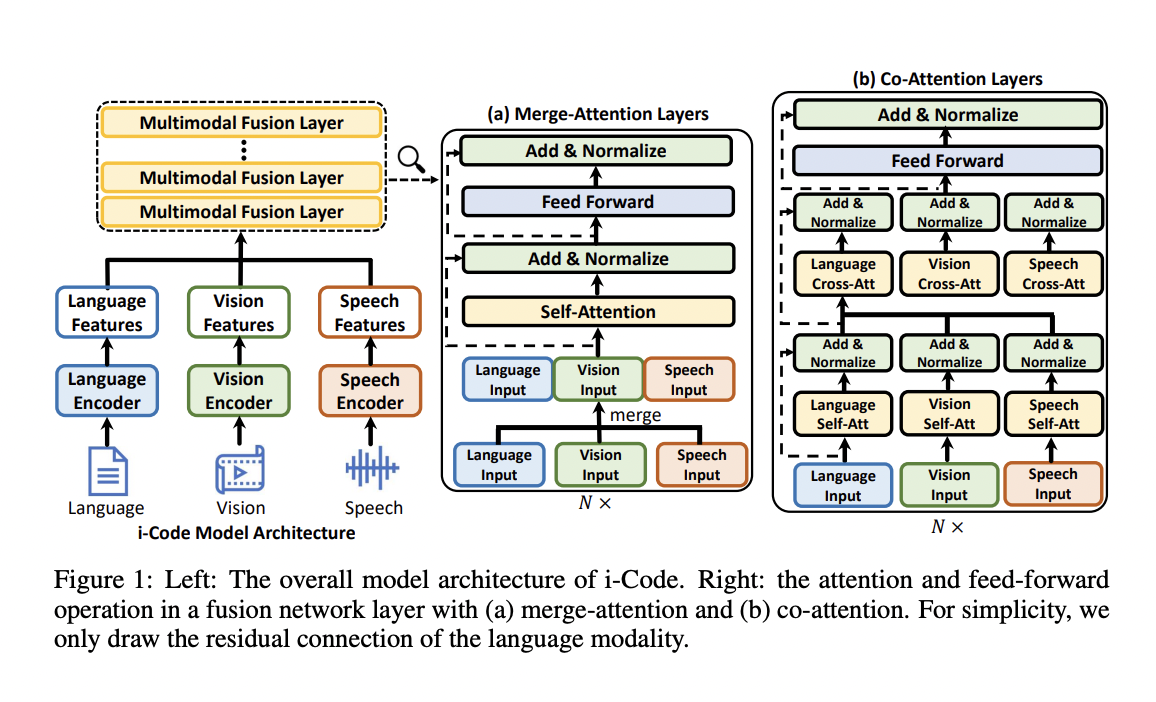
This approach works by first sending data points from each modality into a single-modality encoder that has been pre-trained. The encoder outputs are then sent into a multimodal fusion network, which employs innovative attention processes and other architectural advances to mix data from various modalities successfully. Unlike prior experimental studies that relied solely on video for pre-training, the i-Code architecture can dynamically handle single, dual, and triple-modality data, allowing multiple combinations of modalities to be projected into a single representation space. The team devised two techniques to lessen the load of the unified modality pretraining procedure’s extensive training data requirements. These techniques are based on using large-scale dual-modality data as a supplement to video jobs. The team also presented a fusing architecture that employs contextual outputs from current state-of-the-art single-modality encoders as a building component rather than training the model from scratch.
I-Code comprises four modules, with the first three constituting single-modality encoders for vision, language, and speech. At the same time, the fourth is a modality fusion network that feeds encoded inputs from each modality into a linear projection layer. The researchers used a range of self-supervision objectives to pretrain i-Code on dual or triple-modality data to create a fusing module that effectively combines the outputs of the single-modality encoders and conducts cross-modality understanding for final prediction. All input signals are converted to discrete tokens, which are then utilized to predict the proper token of the masked units for each modality using masked unit modeling. Contrastive learning determines whether given signals in the training data come from the same pair. The framework can process various input types and combinations using this design, including combinations of one, two, or three modalities.

The team compared the i-Code framework against many baselines, including MISA, MulT, and CLIP, on downstream tasks such as multimodal sentiment and emotion analysis, multimodal inference, and video question answering as part of their empirical study. According to the research team’s extensive testing, i-Code surpasses previous state-of-the-art methodologies by 11 percent on five video understanding tasks and the GLUE NLP benchmark, illustrating the value of integrative multimodal pretraining. The authentic paper behind this research can be found here.
Paper: https://arxiv.org/pdf/2205.01818.pdf
Credit: Source link
Comments are closed.