Microsoft Research Introduces LongNet: A Transformer Variant That Can Scale Sequence Length To More Than 1 Billion Tokens With No Loss In Shorter Sequences
Scaling neural networks has been popular in recent years. Several potent deep networks are produced with the depth largely increased for exponential expressivity. Then, the hidden dimension is effectively expanded using sparse MoE models and model parallelism techniques. As the last atomic dimension of the neural network, the sequence length should be as long as possible. There are several benefits when the sequence length restriction is removed. First, it gives models a sizable memory and receptive field, enabling them to interact with people and the outside environment. Second, lengthier contexts include more intricate causal chains and thought processes, which models may use in training data.
On the other hand, short dependence has more erroneous correlations, which is detrimental to generalization. Third, it allows for exploring the boundaries of in-context learning, representing a paradigm change for many-shot education since an extraordinarily extended context might lessen catastrophic forgetting in the models. Finding the ideal balance between computational complexity and model expressivity is the main difficulty in scaling up sequence length.
The main goal of RNN-style models is to extend the length. The parallelization during training, crucial in long-sequence modeling, is nonetheless constrained by its sequential character. Sequence modeling has more recently found favor with state space models. It may function as a CNN during training and switch to an effective RNN during testing. They perform well at long-range benchmarks but on shorter lengths. They fall short of Transformers. This is mostly due to the model’s expressivity. Reducing the difficulty of Transformers, or the quadratic complexity of self-attention, is another aspect of scaling the sequence length. Implementing sliding windows or convolution modules over the attention is simple to make the complexity almost linear. However, doing so costs memory for the early tokens, causing one to overlook the prompts at the start of the series. Sp sparse attention decreases computation by sparsifying the attention matrix while keeping the ability to recall distant information. Obtains O(N (√ N) d) time complexity, for instance, using a fixed sparse pattern.
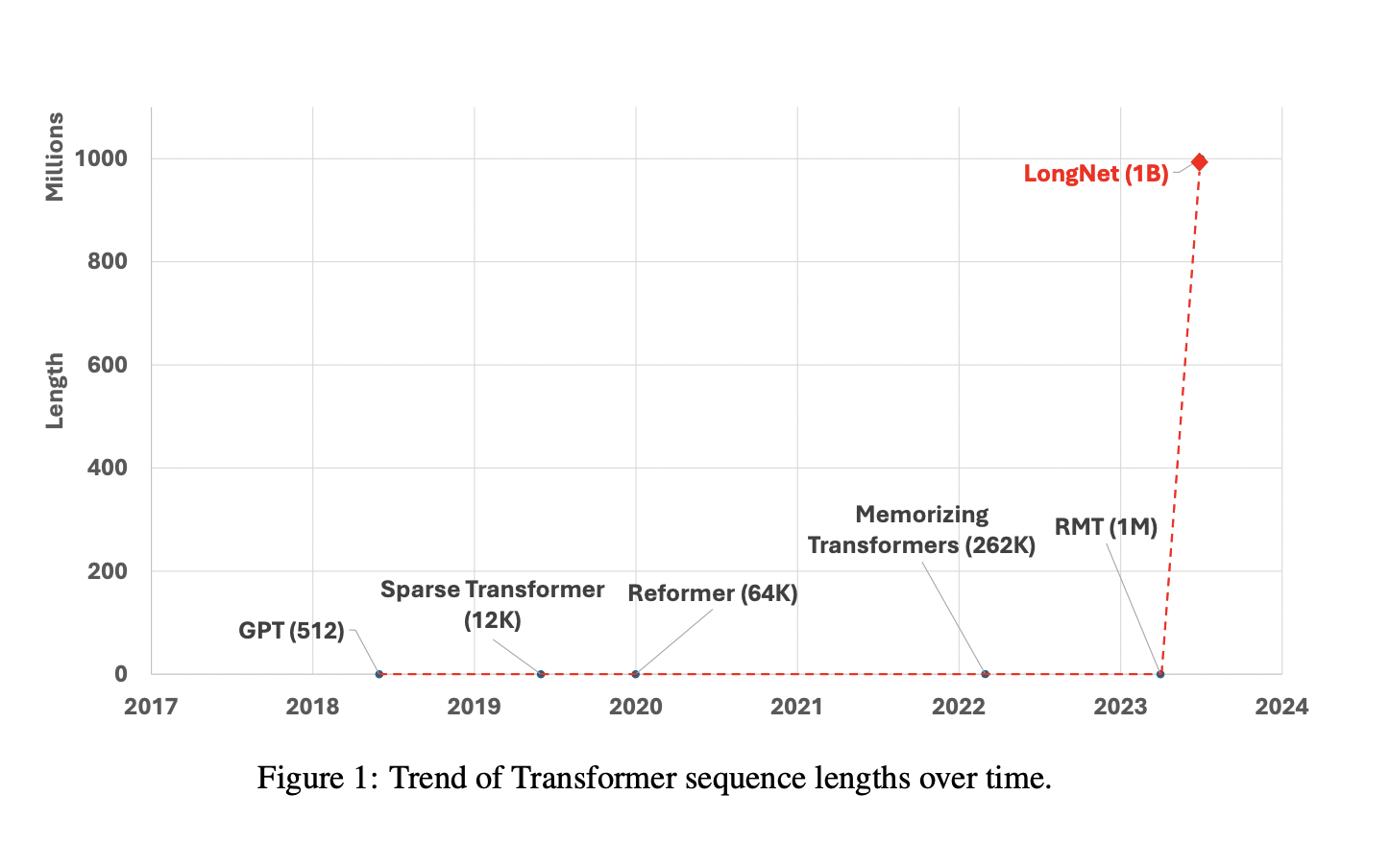
The learnable patterns, in addition to the heuristic patterns, work well for sparse attention. Low-rank attention, kernel-based techniques, downsampling strategies, recurrent models, and retrieval-based techniques are a few more effective Transformer-based versions. Despite this, none have been scaled to 1 billion tokens. They successfully scale the sequence length to 1 billion tokens in their study. Researchers from Microsoft Research developed LONGNET, which swaps the focus of conventional Transformers with a cutting-edge element known as dilated attention. The main design tenet is that attention allocation falls off rapidly as the distance between tokens increases. They demonstrate that it achieves a logarithm dependence between tokens and linear processing complexity.
This addresses the conflict between the accessibility of all tokens and the finite amount of attention resources. LONG NET may be converted into a dense Transformer in the implementation, which supports the standard Transformer optimizations (such as kernel fusion, quantization, and distributed training) without problems. By using linear complexity, LONGNET can divide the training among nodes and overcome the limitations of both CPU and memory. Since the vanilla Transformer suffers from quadratic complexity, this enables us to efficiently scale up the sequence length to 1B tokens with practically constant runtime.
Check out the Paper and Github link. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.