Microsoft Research Introduces Visual ChatGPT That Incorporates Different Visual Foundation Models Enabling Users To Interact With ChatGPT
Recent years have seen remarkable advances in developing large language models (LLMs), including T5, BLOOM, and GPT-3. ChatGPT, based on InstructGPT, is a major advancement because it is taught to hold on to conversational context, respond appropriately to follow-up inquiries, and generate accurate responses. While ChatGPT is impressive, it is only trained with a single language modality, limiting its ability to handle visual information.
Visual Foundation Models (VFMs) have shown enormous potential in computer vision thanks to their capacity to comprehend and construct complex visuals. However, VFMs are less adaptable than conversational language models in human-machine interaction due to the constraints imposed by the nature of task definition nature and the predefined input-output formats.
Training a multimodal conversational model is a natural solution that can create a system similar to ChatGPT but with the ability to comprehend and create visual content. Constructing such a system, however, would necessitate a substantial quantity of information and processing power.
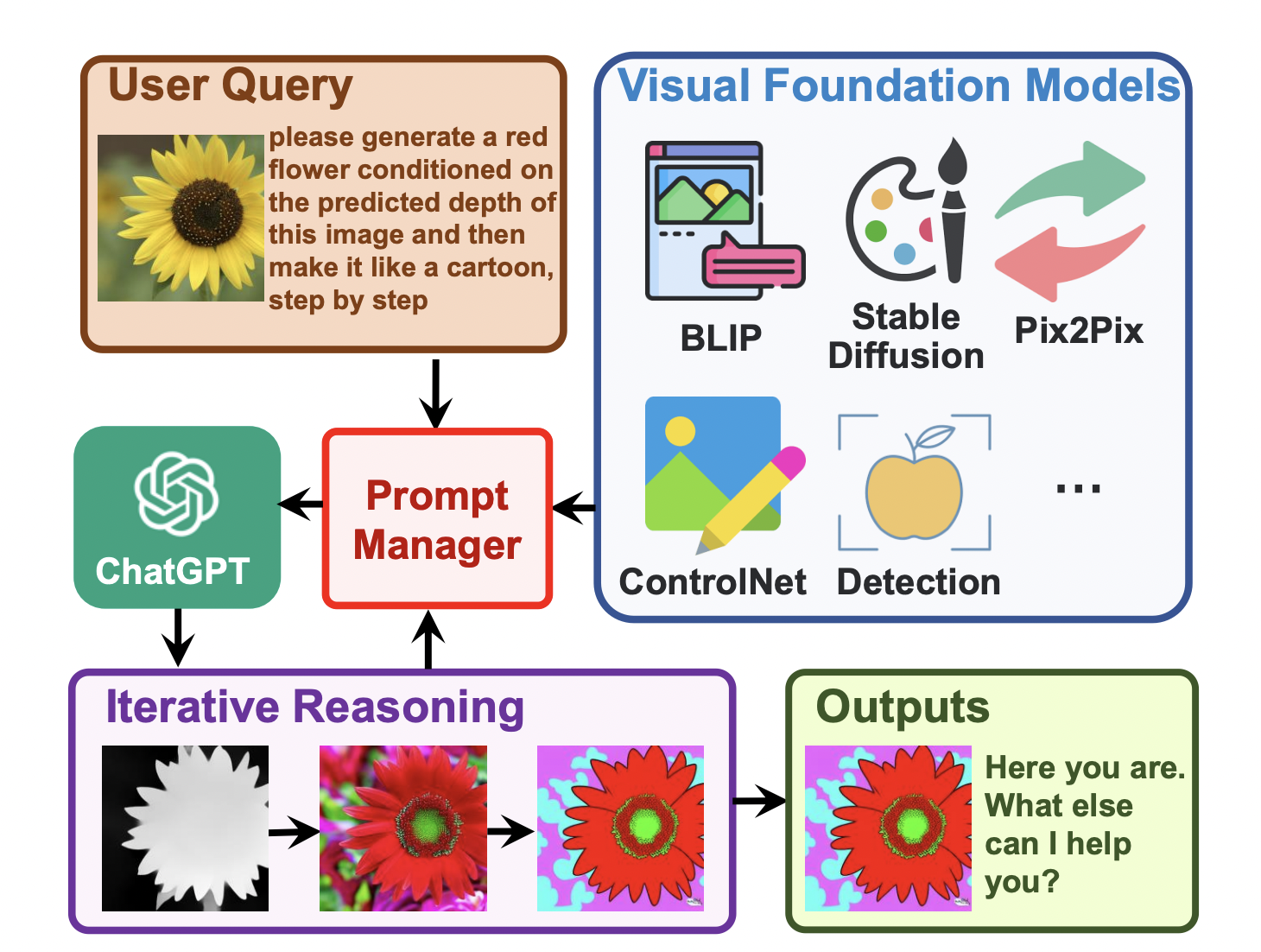
A new Microsoft study proposes a solution to this issue with Visible ChatGPT that interacts with vision models via text and prompt chaining. The researchers developed Visual ChatGPT on top of ChatGPT and added several VFMs as an alternative to training a brand-new multimodal ChatGPT from the start. They introduce a Prompt Manager that bridges the gap between ChatGPT and these VFMs with the following features:
- Specifies the input and output formats and informs ChatGPT on the capabilities of each VFM
- Handles the histories, priorities, and conflicts of various Visual Foundation Models
- Turns various visual information, such as png images, depth images, and mask matrix, into language format to aid ChatGPT in understanding.
By integrating the Prompt Manager, ChatGPT may iteratively employ these VFMs and learn from their responses until it either satisfies the users’ needs or reaches the end state.
For instance, suppose a user uploads an image of a yellow flower and adds a difficult language instruction like “please generate a red flower conditioned on the predicted depth of this image and then construct it like a cartoon, step by step.” Visual ChatGPT initiates the execution of linked Visual Foundation Models using the Prompt Manager. Specifically, it first employs a depth estimation model to identify the depth information, then a depth-to-image model to create a figure of a red flower using the depth information, and finally a style transfer VFM based on a Stable Diffusion model to transform the aesthetics of this image into a cartoon. In the above processing chain, the Prompt Manager acts as a dispatcher for ChatGPT by supplying the visual representations and tracking the information transformation. After collecting “cartoon” hints from Prompt Manager, Visual ChatGPT will halt the pipeline’s execution and display the final output.
When running the source through Pyreverse, it would be possible to accomplish multimodality by using a “god model” to select among various small models, with text as the universal interface.
The researchers mention in their paper that the failure of VFMs and the inconsistency of the Prompt are causes for worry since they lead to less-than-satisfactory generation results. For this reason, a single self-correcting module is required to verify that execution results are consistent with human intentions and to make the needed edits. It’s possible that the model’s inference time would balloon due to its tendency to constantly course-correct itself. The team plans to address this issue in their future study.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.