Microsoft Research Proposes BioGPT: A Domain-Specific Generative Transformer Language Model Pre-Trained on Large-Scale Biomedical Literature
With recent technological breakthroughs, researchers have started employing several machine learning techniques on the abundance of biomedical data that is available. Using techniques like text mining and knowledge extraction on biomedical literature has been demonstrated to be crucial in developing new medications, clinical therapy, pathology research, etc. A growing number of biomedical publications are published daily due to ongoing scientific advancements, necessitating the constant need to draw meaningful information from this material. This is where pre-trained language models come into play. Biomedical researchers have gained much interest in pre-trained language models due to their exceptional effectiveness in the general natural language domain.
However, the performance of these models when used directly in the biomedical area has not been adequate. The models excel in various discriminative downstream biological tasks, but their range of applications is limited because they lack generational capability. To counter this issue, researchers in the past pre-trained their models on biomedical texts. Of the two main branches of pre-trained language models in the general language domain—GPT and BERT, and their variants; BERT has received the most attention in the biomedical field. BioBERT and PubMedBERT are two of the most well-known pre-trained language models in the biomedical industry that have achieved superior performance compared to other general pre-trained models on biomedical text.
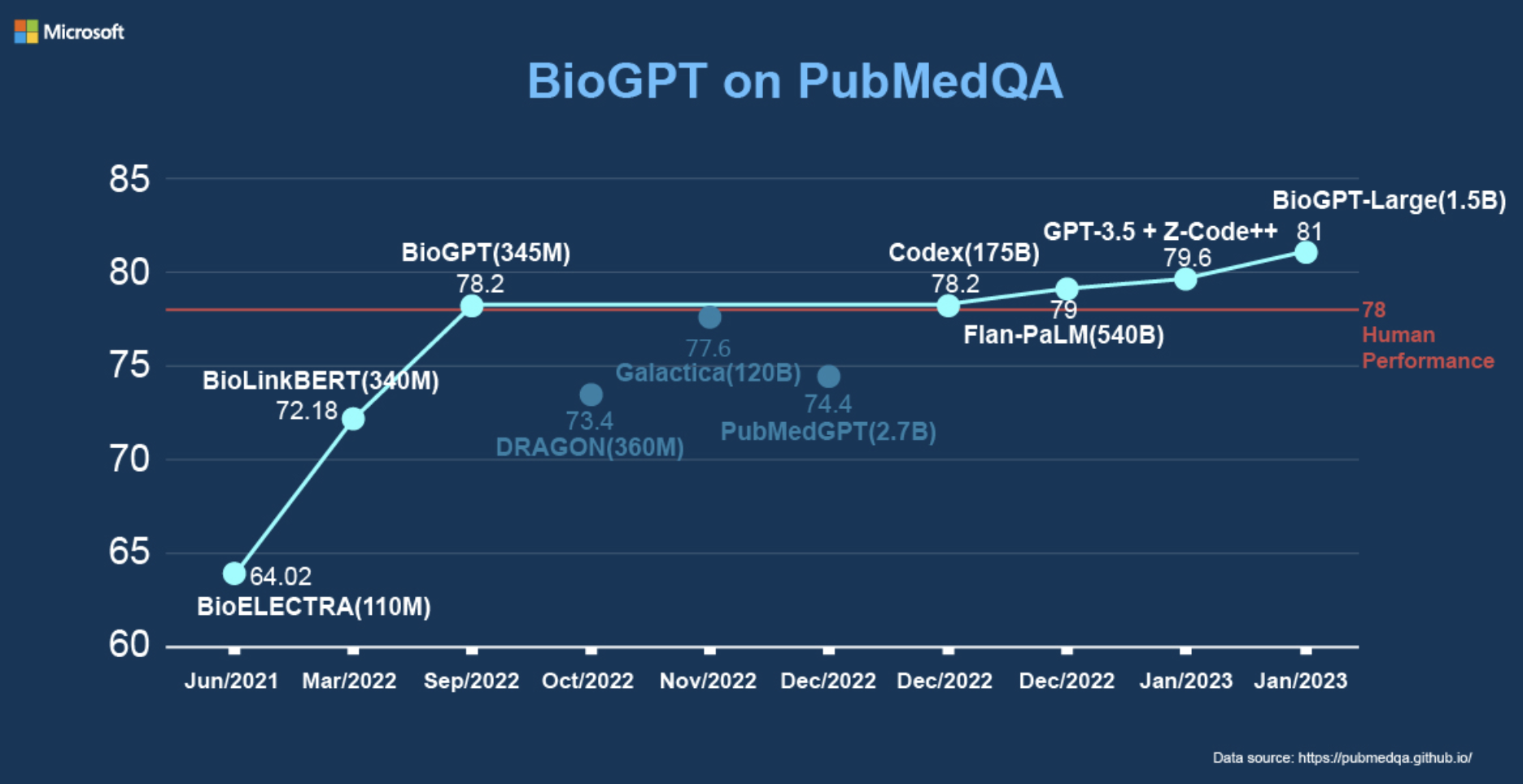
However, the majority of current research makes use of BERT models, which are more suitable for comprehension tasks as compared to generation tasks. While GPT models have proven adept at generating tasks, their performance in the biomedical area has yet to be fully scrutinized. In response to this problem statement, Microsoft researchers recently introduced BioGPT, a domain-specific generative Transformer language model pre-trained on extensive biomedical literature. BioGPT is pre-trained on an enormous corpus of 15M PubMed abstracts and is built on the Transformer language model. The researchers used six biological NLP tasks to evaluate the language model, some of which include question answering, document categorization, and end-to-end relation extraction. According to several experimental evaluations, BioGPT significantly outperforms alternative baseline models across most tasks.
For pre-training a language model, a high-quality dataset is highly crucial. The researchers used in-domain text data from PubMed to pre-train their model from scratch. The GPT-2 model, essentially a Transformer decoder, serves as the foundation for BioGPT. However, rather than using the vocabulary of GPT-2, the researchers concentrated on learning the vocabulary on the gathered in-domain corpus using byte pair encoding. The primary component of the BioGPT model is the multi-head attention layer which produces query Q, the key K, and the value V after three linear transformations. These are then used to compute the output of the multi-head attention layer, which is subsequently sent into a feed-forward layer to create a Transformer block.
The pre-trained model was later fine-tuned to adapt downstream tasks like text generation, question answering, and end-to-end relation extraction. While the input type for all of these activities, i.e., sequences, remains the same, the output formats vary. Thus, when applying pre-trained BioGPT to these tasks, the researchers carefully looked into the prompt and the target sequence format. BioGPT achieves state-of-the-art performance on three end-to-end relation extraction tasks and one question-answering task. Additionally, it outperforms GPT-2 on the text generation task in terms of biomedical text generation skills. To adapt BioGPT to additional downstream activities, the Microsoft research team intends to train it on an even greater scale of biomedical data in the future. The underlying implementation of BioGPT can be found below.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.