Microsoft Researchers Develop a Game Theoretic Approach to Provably Correct and Scalable Offline Reinforcement Learning
Even though Machine learning is used in most fields and aspects, most of the automation is designed by humans, not artificial intelligence. For example, decision-making strategies in robotics and other applications with long-term consequences are implemented by experienced human engineers.
In reinforcement learning, the online RL agents learn by trial and error. They try out various actions, know the consequences and improve upon that. So they make different sub-optimal decisions and learn through them, which is okay and acceptable in most cases, but it’s not an option in every task, for example, in self-driving cars.
Offline RL is a model that learns from large static datasets previously collected. It does not collect online data for learning policies, and neither does it interact with a simulator. Offline RL has excellent potential for large-scale deployment in the real world.
Challenge faced by offline RL.
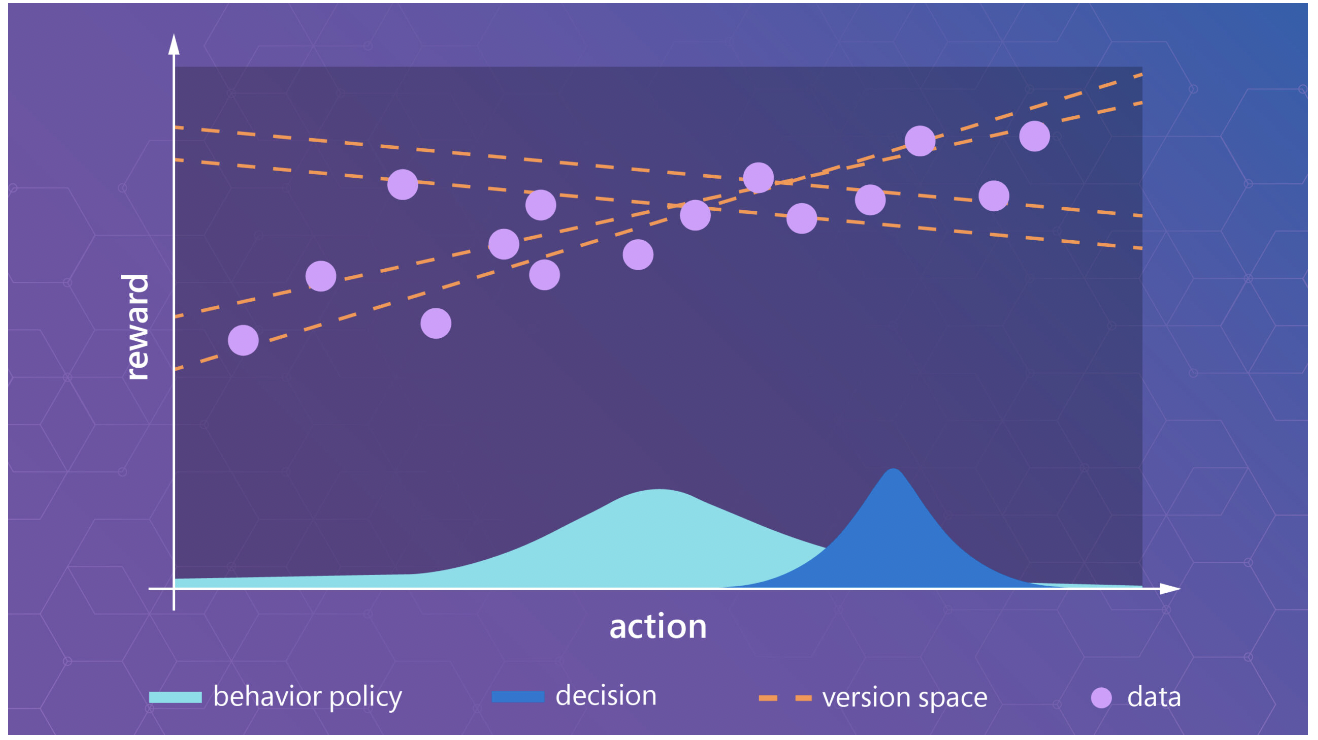
The most fundamental challenge faced by offline RL is that the data collected lacks diversity, making it difficult to estimate its policy’s goodness in the real world. Making the dataset diverse is impossible because it requires humans to run unrealistic experiments, for example, for self-driving cars-Staging a car crash, etc. So because of all this, the data collected in large quantities lacks diversity, reducing its usefulness.
Microsoft researchers have tried to solve this problem. They introduce a generic game-theoretic framework for offline RL where they pose the offline RL as a two-player game between the learning agent and adversary that simulates the uncertain decision outcomes due to missing data coverage. They also showed that this framework, through generative adversarial networks, provides a natural connection between offline RL and imitation learning. It is also shown that this framework is no worse than the data collection policies. Existing data can be used robustly to learn policies that improve upon human strategies in the system. To solve the central issue of not having all possible outcomes, The agent must carefully consider uncertainties brought on by missing data to solve this problem. Before making a choice, the agent should consider all potential outcomes rather than fixate on a specific data-consistent result. When the agent’s choices could have unfavorable effects, in reality, this kind of purposeful conservatism is exceptionally crucial.
This is done through the concept of version space which is mathematical. You can read further from the sources.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Adversarially Trained Actor Critic for Offline Reinforcement Learning'. All Credit For This Research Goes To Researchers on This Project. Check out the paper1, paper2 and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Prathvik is ML/AI Research content intern at MarktechPost, he is a 3rd year undergraduate at IIT Kharagpur. He has a keen interest in Machine learning and data science.He is enthusiastic in learning about the applications of in different fields of study .
Credit: Source link
Comments are closed.