Microsoft Researchers Introduce LoRAShear: A Novel Artificial Intelligence Efficient Approach to Structurally Prune LLMs and Recover Knowledge
LLMs can process vast amounts of textual data and retrieve relevant information quickly. This has applications in search engines, question-answering systems, and data analysis, helping users find the information they need more easily.LLMs can augment human knowledge by providing instant access to vast databases of information, which can be valuable for researchers, professionals, and individuals seeking knowledge in various domains.
Knowledge recovery is one of the most important tasks in LLM. One common way to recover knowledge in LLMs is through fine-tuning. Developers can take a pre-trained model and fine-tune it on a specific dataset to update its knowledge. If you want the model to be knowledgeable about recent events or specialized domains, fine-tuning with relevant data can help. Researchers and organizations that maintain LLMs periodically update them with new information, which involves retraining the model with a more recent dataset or a specific knowledge update procedure.
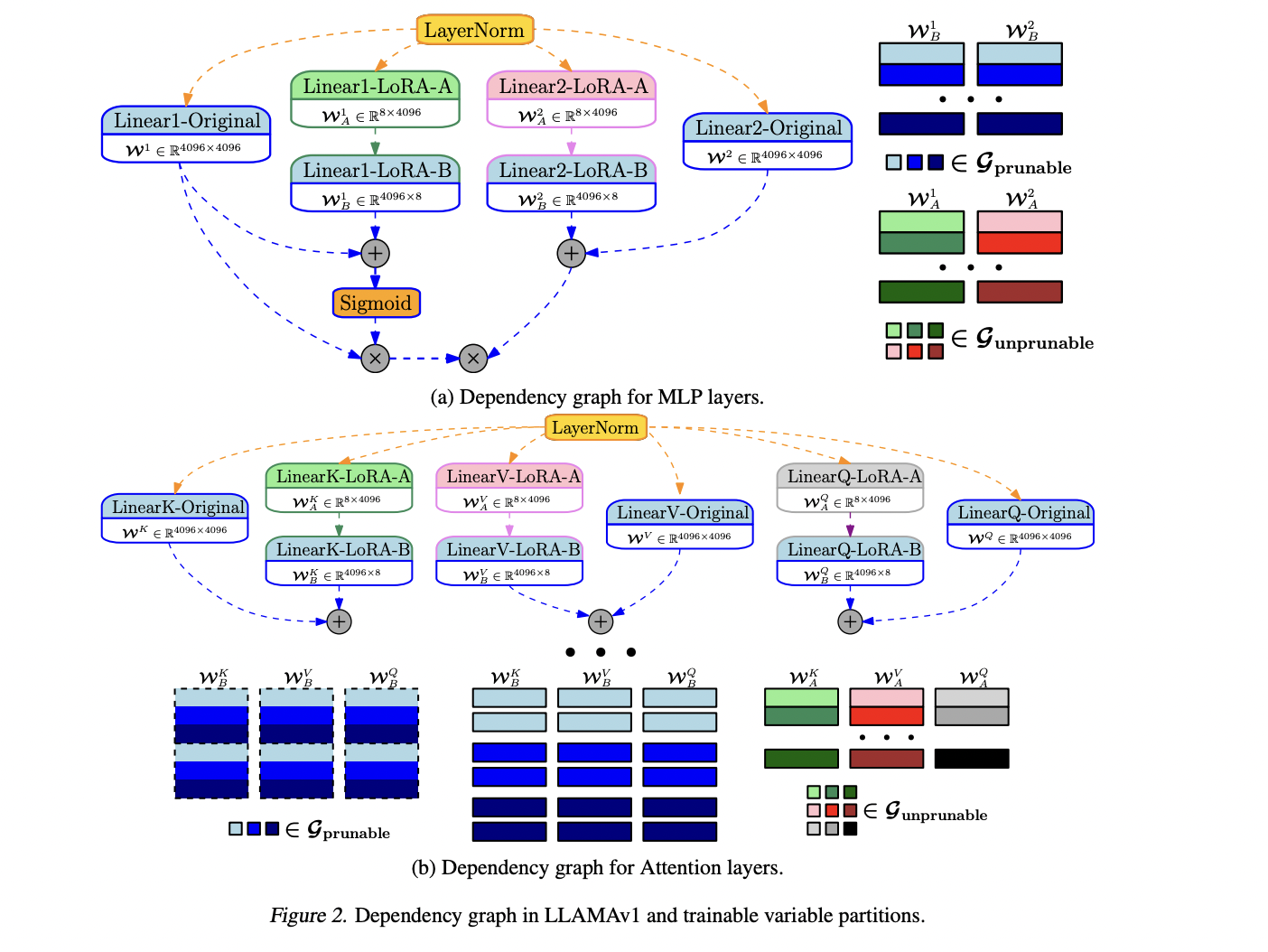
Researchers at Microsoft have developed a novel, efficient approach to prune LLMs and recover knowledge structurally. They call it as “LoRAShear “. Structure pruning refers to removing or reducing certain components or elements of a neural network’s architecture to make it more efficient, compact, and computationally less demanding. They propose Lora Half-Space Projected Gradient (LHSPG) to enable progressive structured pruning with inherent knowledge transfer over LoRA modules and a dynamic knowledge recovery stage to perform multi-stage fine-tuning in the manner of both pretraining and instructed fine-tuning.
Researchers say that LoRAShear can be applied to general LLMs by performing dependency graph analysis over LLMs with LoRA modules. Their approach uniquely defines an algorithm to create dependency graphs for the original LLM and LoRA modules. They further also introduce a structured sparsity optimization algorithm that utilizes information from LoRA modules to update weights, which enhances knowledge preservation.
LoRAPrune integrates LoRA with iterative structured pruning, achieving parameter-efficient fine-tuning and direct hardware acceleration. They say this approach is memory efficient as it relies only on LoRA’s weights and gradients for pruning criteria. Given an LLM, they construct a trace graph and establish node groups that are to be compressed. They partition the trainable variables into minimally removal structures, reform the trainable variable group, and return it to the LLM.
They demonstrate its effectiveness by implementing it on an open-source LLAMAv1. They find that 20% pruned LLAMAv1 regresses 1% performance, and the 50% pruned model preserves 82% performance on the evaluation benchmarks. However, its application to LLMs is facing significant challenges due to the requirements of massive computational resources and the unavailable training datasets of both pretraining and instructed fine-tuning datasets, and future work would be to resolve it.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.