Microsoft Researchers Introduce ‘Mesh Graphormer’, A Graph-Convolution-Reinforced Transformer
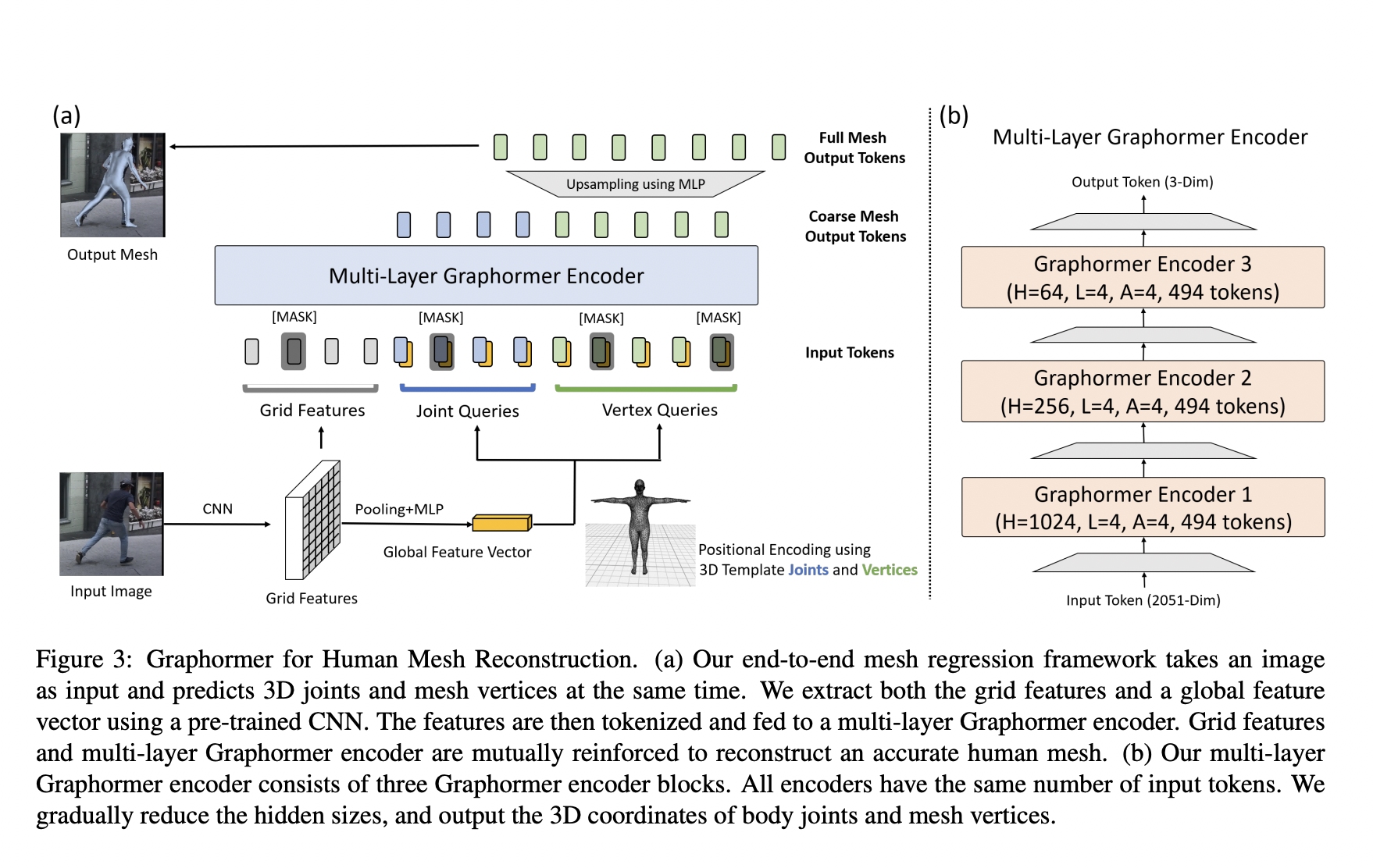

While 3D human pose and mesh reconstruction from a single image is a trending area of research because of its applications for human-computer interactions, it is also a very challenging process due to the complex body articulation.
The current progress tools include transformers and graph convolutional neural networks in human mesh reconstruction. Transformer-based approaches are more effective in modeling nonlocal interactions among 3D mesh vertices and body joints. In contrast, GCNNs are good at exploiting neighborhood vertex interactions based on a pre-specified mesh topology.
Researchers from Microsoft introduced a graph-convolution-reinforced transformer, named Mesh Graphormer, for reconstructing human pose and mesh from a single image. The researchers inject graph convolutions into transformer blocks to improve the local interactions among neighboring vertices and joints. The proposed Graphormer is free to join and attend all image grid features to leverage the strength of graph convolutions. Therefore, Graphormer and image grid features are utilized and enforced to improve human pose and mesh reconstruction performance.

The researchers introduce Mesh Graphormer, a graph-convolution reinforced transformer that models local and global interactions for 3D human pose reconstruction. With Mesh Graphormer, the joint and mesh vertices are free to finely tune their coordinate prediction in order for 3D coordinates with accuracy. Mesh Graphormer is a new technology that outperforms previous state-of-the-art methods on Human3.6M, 3DPW, and FreiHAND datasets.
Paper: https://arxiv.org/pdf/2104.00272.pdf
Github: https://github.com/microsoft/MeshGraphormer
Suggested
Credit: Source link
Comments are closed.