Microsoft Researchers Propose A New AI Method That Uses Both Forward And Backward Language Models To Meet In The Middle And Improve The Training Data Efficiency
Language models (LMs) have been extensively utilized for various aided writing activities, including text summarization, code completion, and paraphrasing. LMs are effective tools for creating both natural and programming languages. Most LMs must be able to develop the next token from the sequence of earlier tokens to be useful in a wide range of applications. Due to the significance of this operation, pretraining has concentrated on improving the model’s perplexity in predicting the next token given the last tokens. However, they do have extra information that they are not using during pretraining.
For instance, they entirely disregard the following tokens while training the model to predict one token and only condition on the prefix (prior tokens) (suffix). There are alternative approaches to include the suffix in pretraining that have yet to be discussed in the literature, even though it cannot be utilized as an input to the model. They want to increase the pretraining data’s usefulness while maintaining the underlying LM’s autoregressive properties. Their strategy calls for more modeling, which at first glance could appear useless. After all, an autoregressive left-to-right LM is a primary artifact created during pretraining, and the pretraining aim closely resembles how the LM is used.
Yet, there are two reasons to explore different training objectives. Data efficiency is discussed in the first. The LM is trained using a sparse, inexpensive signal that generates a probability distribution over all potential next-token selections. However, it is only supervised using the actual next token from the training set. What if a more intense kind of supervision was used during training, where the probability distribution for the next tokens was compared to a different probability distribution? The second justification relates to other connected responsibilities. For instance, the user may prefer to fill in or edit an existing sequence of tokens in many real-world settings rather than creating text entirely from scratch.
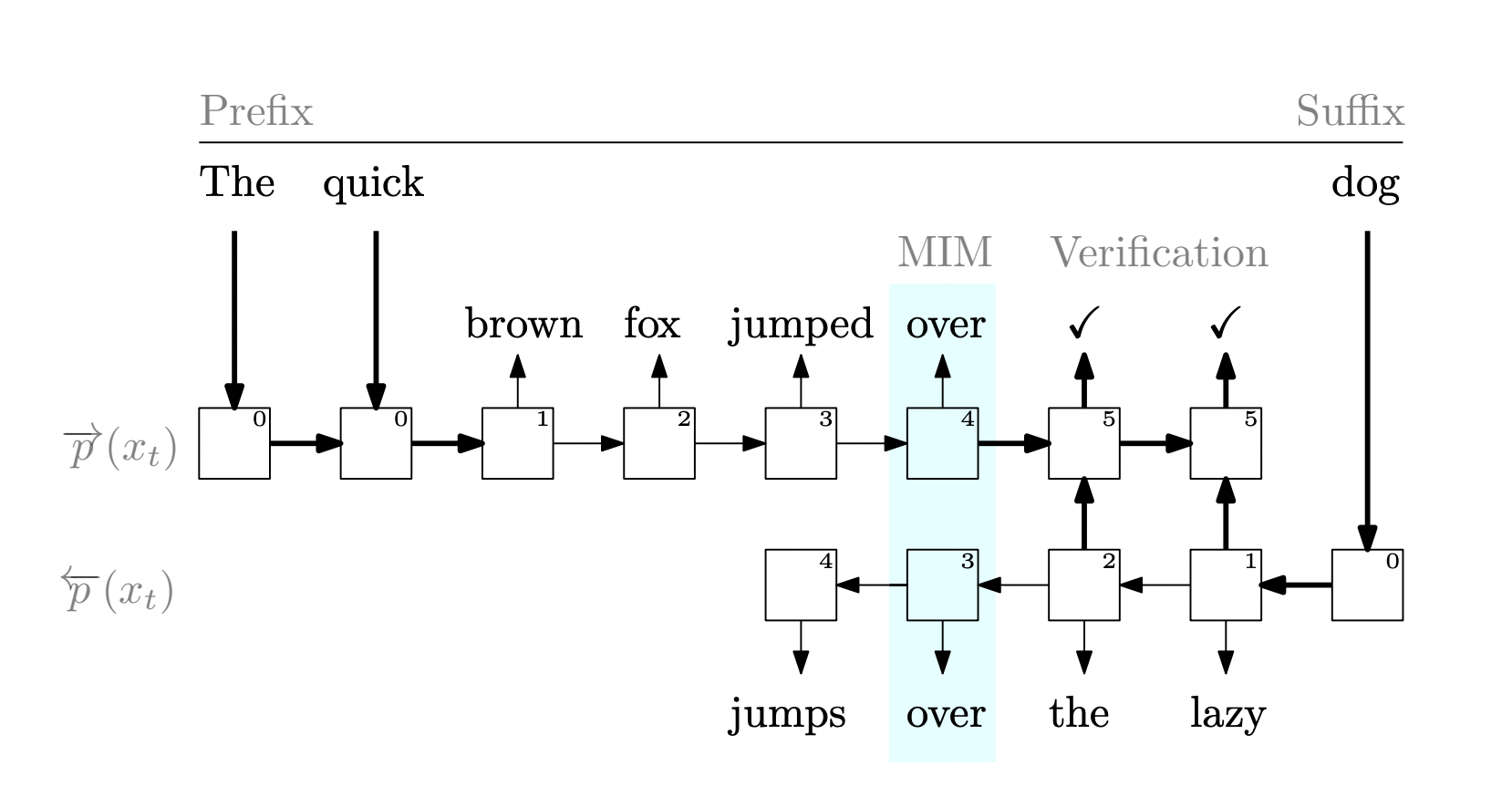
A writer may wish to include a sentence or two to strengthen a paragraph’s coherence, for instance, or a programmer may want to add a new parameter to a function. A left-to-right LM cannot use the context from both sides of the insertion location in these situations, which might lead to unsatisfactory outcomes. We can also create a cutting-edge infilling method using the additional modeling they perform during training. To address both pretraining and infilling, researchers from Microsoft suggest a combined pretraining and inference paradigm they name “Meet in the Middle” (MIM) in this study. MIM uses two key concepts. The first suggestion is to build a second language model that reads tokens from left to right and then use the two models to co-regularize one another. In doing so, each LM can benefit from the context that the other LM provides, increasing the effectiveness and consistency of the data.
The second concept is a straightforward and efficient inference process for infilling that uses all the pretraining artifacts, including both language models and their propensity to agree. In this instance, the two models will physically “meet in the middle” by creating the complete one from each side. The models figuratively “meet in the middle” by changing their output probabilities to support the opposing viewpoint. Their agreement regularizer provides two key advantages: it regularises and improves the consistency of the two language models and aids in the early termination of the generation process during the infilling job by identifying the point at which the two models converge to the same token.
In other words, they deploy a single shared decoder-only architecture with two decoding processes to train MIM. The two LMs produce tokens in opposing directions. The forward direction predicts the following token given the prefix and the tokens it makes. Given the suffix and the tokens it produces, the reverse direction indicates the last token. They use a mix of the agreement regularizer and the conventional language modeling loss to jointly pre-train the two models on a sizable text corpus. They conduct trials to assess the efficacy of MIM for pretraining LMs on various domains and tasks. When pretraining is finished, the forward model may be used as a drop-in replacement for current autoregressive LMs. You may throw away the backward model or use it for related tasks like infilling.
They pre-train LMs of various sizes using language and public code data, and then they assess how well they perform using perplexity and code completion tests. They demonstrate that MIM surpasses them in terms of confusion as well as task-specific assessment metrics by contrasting it with FIM and other baselines, as well as different baselines. They also undertake ablation studies to demonstrate the success of their key suggestions during training and inference.
In summary, their primary contributions are:
• They develop a novel pretraining paradigm for LMs that maintains the autoregressive character of LMs while better using the training data by utilizing both the prefix and the suffix. They train both a forward and a backward model to do this, and they nudge them towards agreement.
• For the infilling job, provide a quick and effective inference process that uses the context from both sides and the likelihood of the forward and backward models to agree. Their method delivers greater quality and latency than the state-of-the-art and can employ parallelism more efficiently than current infilling methods.
• Use MIM to pre-train language models of various sizes using publicly available code and linguistic data, assess them using both programming and human languages, and demonstrate that MIM outperforms several baselines in common evaluation criteria. Ultimately, a few models and pieces of code are made public.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.