Microsoft Researchers Propose BioViL-T: A Novel Self-Supervised Framework Ushering in Enhanced Predictive Performance and Data Efficiency in Biomedical Applications
Artificial Intelligence (AI) has emerged as a significant disruptive force across numerous industries, from how technological businesses operate to how innovation is unlocked in different subdomains in the healthcare sector. In particular, the biomedical field has witnessed significant advancements and transformation with the introduction of AI. One such noteworthy progress can be boiled down to using self-supervised vision-language models in radiology. Radiologists rely heavily on radiology reports to convey imaging observations and provide clinical diagnoses. It is noteworthy that prior imaging studies frequently play a key role in this decision-making process because they provide crucial context for assessing the course of illnesses and establishing suitable medication choices. However, current AI solutions in the mark cannot successfully align images with report data due to limited access to previous scans. Furthermore, these methods frequently do not consider the chronological development of illnesses or imaging findings typically present in biological datasets. This lack of contextual information poses risks in downstream applications like automated report generation, where models may generate inaccurate temporal content without access to past medical scans.
With the introduction of vision-language models, researchers aim to generate informative training signals by utilizing image-text pairs, thus, eliminating the need for manual labels. This approach enables the models to learn how to precisely identify and pinpoint discoveries in the images and establish connections with the information presented in radiology reports. Microsoft Research has continually worked to improve AI for reporting and radiography. Their prior research on multimodal self-supervised learning of radiology reports and images has produced encouraging results in identifying medical problems and localizing these findings within the images. As a contribution to this wave of research, Microsoft released BioViL-T, a self-supervised training framework that considers earlier images and reports when available during training and fine-tuning. BioViL-T achieves breakthrough results on various downstream benchmarks, such as progression classification and report creation, by utilizing the existing temporal structure present in datasets. The study will be presented at the prestigious Computer Vision and Pattern Recognition Conference (CVPR) in 2023.
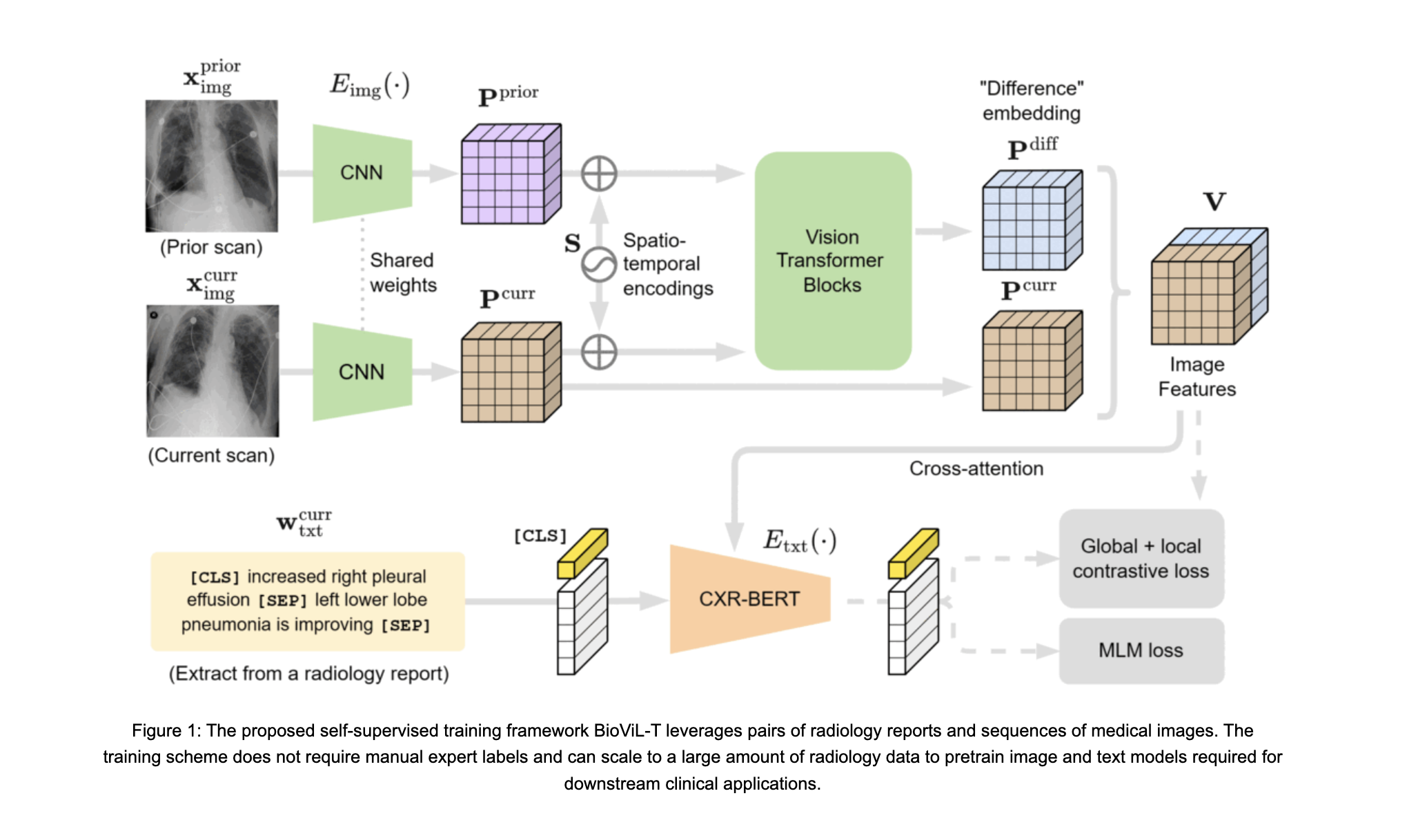
The distinguishing characteristic of BioViL-T lies in its explicit consideration of previous images and reports throughout the training and fine-tuning processes rather than treating each image-report pair as a separate entity. The researchers’ rationale behind incorporating prior images and reports was primarily to maximize the utilization of available data, resulting in more comprehensive representations and enhanced performance across a broader range of tasks. BioViL-T introduces a unique CNN-Transformer multi-image encoder that is jointly trained with a text model. This novel multi-image encoder serves as the fundamental building block of the pre-training framework, addressing challenges such as the absence of previous images and pose variations in images over time.
A CNN and a transformer model were chosen to create the hybrid multi-image encoder to extract spatiotemporal features from image sequences. When previous images are available, the transformer is in charge of capturing patch embedding interactions across time. On the other hand, CNN is in order of giving visual token properties of individual images. This hybrid image encoder improves data efficiency, making it suitable for datasets of even smaller sizes. It efficiently captures static and temporal image characteristics, which is essential for applications like report decoding that call for dense-level visual reasoning over time. The pre-training procedure of the BioViL-T model can be divided into two main components: a multi-image encoder for extracting spatiotemporal features and a text encoder incorporating optional cross-attention with image features. These models are jointly trained using cross-modal global and local contrastive objectives. The model also utilizes multimodal fused representations obtained through cross-attention for image-guided masked language modeling., thereby effectively harnessing visual and textual information. This plays a central role in resolving ambiguities and enhancing language comprehension, which is of utmost importance for a wide range of downstream tasks.
The success of the Microsoft researchers’ strategy was aided by a variety of experimental evaluations that they conducted. The model achieves state-of-the-art performance for a variety of downstream tasks like progression categorization, phrase grounding, and report generation in single- and multi-image configurations. Additionally, it improves over previous models and yields appreciable results on tasks like disease classification and sentence similarity. Microsoft Research has made the model and source code available to the public to encourage the community to investigate their work further. A brand-new multimodal temporal benchmark dataset dubbed MS-CXR-T is also being made public by the researchers to stimulate additional research into quantifying how well vision-language representations can capture temporal semantics.
Check Out The Paper and Microsoft Article. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.