Microsoft Researchers Propose DeepSpeed-VisualChat: A Leap Forward in Scalable Multi-Modal Language Model Training
Large language models are sophisticated artificial intelligence systems created to understand and produce language similar to humans on a large scale. These models are useful in various applications, such as question-answering, content generation, and interactive dialogues. Their usefulness comes from a long learning process where they analyze and understand massive amounts of online data.
These models are advanced instruments that improve human-computer interaction by encouraging a more sophisticated and effective use of language in various contexts.
Beyond reading and writing text, research is being carried out to teach them how to comprehend and use various forms of information, such as sounds and images. The advancement in multi-modal capabilities is highly fascinating and holds great promise. Contemporary large language models (LLMs), such as GPT, have shown exceptional performance across a range of text-related tasks. These models become very good at different interactive tasks by using extra training methods like supervised fine-tuning or reinforcement learning with human guidance. To reach the level of expertise seen in human specialists, especially in challenges involving coding, quantitative thinking, mathematical reasoning, and engaging in conversations like AI chatbots, it is essential to refine the models through these training techniques.
It is getting closer to allowing these models to understand and create material in various formats, including images, sounds, and videos. Methods, including feature alignment and model modification, are applied. Large vision and language models (LVLMs) are one of these initiatives. However, because of problems with training and data availability, current models have difficulty addressing complicated scenarios, such as multi-image multi-round dialogues, and they are constrained in terms of adaptability and scalability in various interaction contexts.
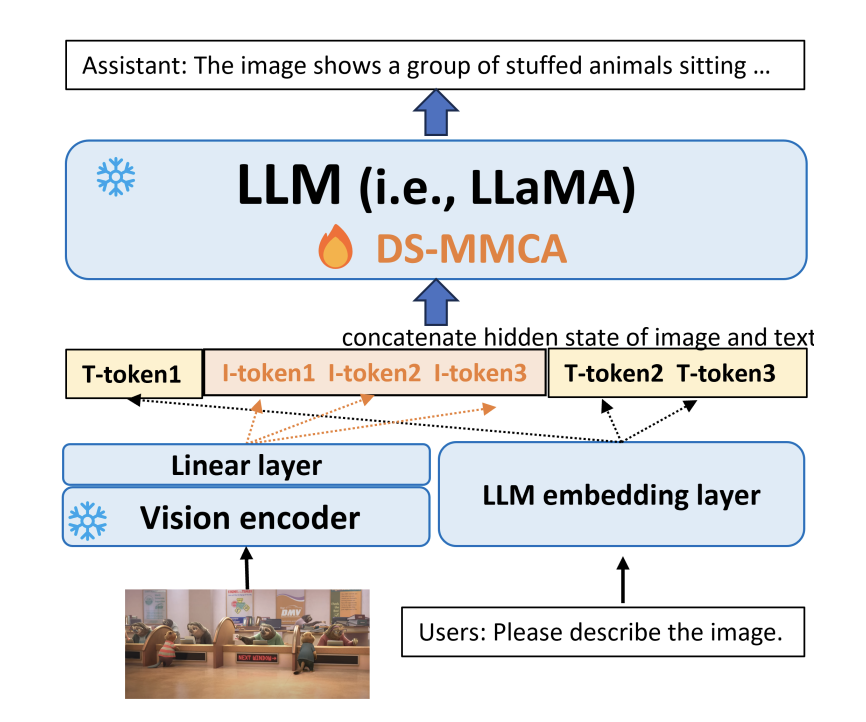
The researchers of Microsoft have dubbed DeepSpeed-VisualChat. This framework enhances LLMs by incorporating multi-modal capabilities, demonstrating outstanding scalability even with a language model size of 70 billion parameters. This was formulated to facilitate dynamic chats with multi-round and multi-picture dialogues, seamlessly fusing text and image inputs. To increase the adaptability and responsiveness of multi-modal models, the framework uses Multi-Modal Causal Attention (MMCA), a method that separately estimates attention weights across several modalities. The team has used data blending approaches to overcome issues with the available datasets, resulting in a rich and varied training environment.
DeepSpeed-VisualChat is distinguished by its outstanding scalability, which was made possible by thoughtfully integrating the DeepSpeed framework. This framework exhibits exceptional scalability and pushes the limits of what is possible in multi-modal dialogue systems by utilizing a 2 billion parameter visual encoder and a 70 billion parameter language decoder from LLaMA-2.
The researchers emphasize that DeepSpeed-VisualChat’s architecture is based on MiniGPT4. In this structure, an image is encoded using a pre-trained vision encoder and then aligned with the output of the text embedding layer’s hidden dimension using a linear layer. These inputs are fed into language models like LLaMA2, supported by the ground-breaking Multi-Modal Causal Attention (MMCA) mechanism. It is significant that during this procedure, both the language model and the vision encoder stay frozen.
According to the researchers, classic Cross Attention (CrA) provides new dimensions and problems, but Multi-Modal Causal Attention (MMCA) takes a different approach. For text and image tokens, MMCA uses separate attention weight matrices such that visual tokens focus on themselves and text permits focus on the tokens that came before them.
DeepSpeed-VisualChat is more scalable than previous models, according to real-world outcomes. It enhances adaption in various interaction scenarios without increasing complexity or training costs. With scaling up to a language model size of 70 billion parameters, it delivers particularly excellent scalability. This achievement provides a strong foundation for continued advancement in multi-modal language models and constitutes a significant step forward.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.