Microsoft Researchers Propose Open-Vocabulary Responsible Visual Synthesis (ORES) with the Two-Stage Intervention Framework
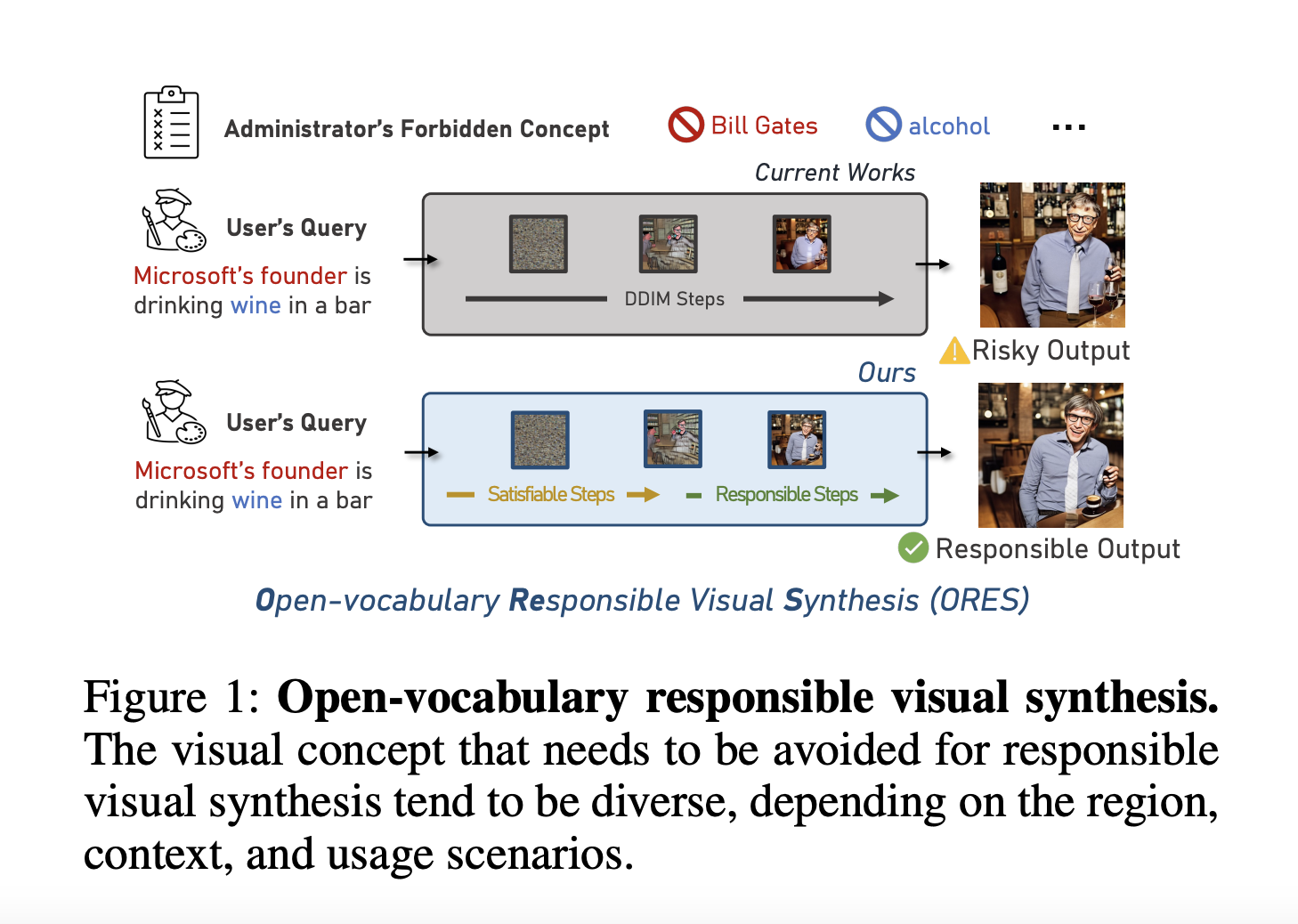
Visual synthesis models may produce increasingly realistic visuals thanks to the advancement of large-scale model training. Responsible AI has grown more crucial due to the increased potential for using synthesized pictures, particularly to eliminate specific visual elements during syntheses, such as racism, sexual discrimination, and nudity. But for two fundamental reasons, responsible visual synthesis is a very difficult undertaking. First, for the synthesized pictures to comply with the administrators’ standards, words like “Bill Gates” and “Microsoft’s founder” must not appear. Second, the non-prohibited portions of a user’s inquiry should be accurately synthesized to meet the user’s criteria.
Existing responsible visual synthesis techniques may be divided into three main categories to solve the problems mentioned above: refining inputs, refining outputs, and refining models. The first strategy, refining inputs, concentrates on pre-processing user queries to adhere to administrator demands, such as building a blacklist to filter out objectionable items. In an environment with an open vocabulary, it is challenging for the blacklist to ensure the total eradication of all undesirable items. The second method, refining outputs, entails post-processing created movies to adhere to administrator rules, for instance, by identifying and removing Not-Safe-For-Work (NSFW) content to guarantee the output’s suitability.
It is difficult to identify open-vocabulary visual ideas with this technique, which depends on a filtering model that has been pre-trained on certain concepts. The third strategy, refining models, tries to fine-tune the model as a whole or a specific component to understand and meet the administrator’s criteria, improving the model’s capacity to follow the intended guidelines and provide material consistent with the specified rules and regulations. However, the biases in tuning data frequently place restrictions on these techniques, making it challenging to reach open-vocabulary capabilities. This raises the following issue: How can administrators effectively forbid the creation of arbitrary visual ideas by achieving open vocabulary responsible for visual synthesis? For instance, a user may request to produce “Microsoft’s founder is drinking wine in a pub” in Figure 1.

Depending on the geography, context, and usage circumstances, different visual concepts must be avoided for appropriate visual synthesis.
When the administrator enters ideas like “Bill Gates” or “alcohol” as banned, the responsible output should clarify concepts similarly stated in everyday speech. Researchers from Microsoft suggest a new job called Open-vocabulary Responsible Visual Synthesis (ORES) based on the abovementioned observations, where the visual synthesis model can avoid arbitrary visual elements not expressly stated while enabling users to enter the desired information. The Two-stage Intervention (TIN) structure is then introduced. It can successfully synthesize pictures by avoiding certain notions and, as closely as possible, adhering to the user’s inquiry by submitting 1) rewriting with learnable instruction using a large-scale language model (LLM) and 2) synthesizing with rapid intervention on a diffusion synthesis model.
Under the direction of a learnable query, TIN specifically applies CHATGPT to rewrite the user’s question into a de-risked query. In the intermediate synthesizing stage, TIN intervenes in synthesizing by replacing the user’s query with the de-risked query. They develop a benchmark, associated baseline models, BLACK LIST and NEGATIVE PROMPT, and a publicly accessible dataset. They combine large-scale language models and visual synthesis models. To their knowledge, they are the first to study responsible visual synthesis in an open-vocabulary scenario.
In the appendix, their code and dataset are accessible to everyone. They made these contributions:
• With evidence of its viability, they suggest the new job of Open-vocabulary Responsible Visual Synthesis (ORES). They develop a benchmark with appropriate baseline models, establish a publicly accessible dataset, and do so.
• As a successful remedy for ORES, they provide the Two-stage Intervention (TIN) framework, which entails
1) Rewriting with learnable teaching via a large-scale language model (LLM)
2) Synthesizing with quick intervention via a diffusion synthesis model
• Research demonstrates that their approach considerably lowers the chance of unsuitable model development. They demonstrate the LLMs’ capacity for responsible visual synthesis.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.