Microsoft Researchers Unveil FP8 Mixed-Precision Training Framework: Supercharging Large Language Model Training Efficiency
Large language models have shown previously unheard-of proficiency in language creation and comprehension, paving the way for advances in logic, mathematics, physics, and other fields. But LLM training is quite expensive. To train a 540B model, for instance, PaLM needs 6,144 TPUv4 chips, whereas GPT-3 175B needs several thousand petaflop/s-days of computation for pre-training. This highlights the need to lower LLM training costs, particularly to scale the next generation of extremely intelligent models. One of the most promising approaches to save costs is low-precision training, which offers fast processing, little memory usage, and minimal communication overhead. Most current training systems, such as Megatron-LM, MetaSeq, and Colossal-AI, train LLMs by default using FP16/BF16 mixed-precision or FP32 full-precision.
For big models, this is optional to obtain complete accuracy, though. FP8 is emerging as the next-generation datatype for low-precision representation with the arrival of the Nvidia H100 GPU. In comparison to the existing 16-bit and 32-bit floating point mixed-precision training, FP8 has the potential to theoretically achieve a 2x speed-up, 50% – 75% memory cost reductions, and 50% – 75% communication savings. These results are highly encouraging for scaling out next-generation foundation models. Regretfully, there needs to be more and infrequent assistance for FP8 training. The Nvidia Transformer Engine is the only workable framework; however, it only uses FP8 for GEMM computation and maintains master weights and gradients with extreme accuracy, such as FP16 or FP32. Because of this, the end-to-end performance increase, memory savings, and communication cost savings are relatively little, which keeps the full potential of FP8 hidden.
Researchers from Microsoft Azure and Microsoft Research provide a highly efficient FP8 mixed-precision framework for LLM training to solve this problem. The main concept is to leverage low-precision FP8 for computation, storage, and communication during the big model training process. This will significantly reduce system demands in comparison to earlier frameworks. To be more precise, they create three optimization stages that use FP8 to simplify distributed and mixed precision training. The three tiers incrementally introduce the optimizer, distributed parallel training, and 8-bit collective communication. A greater optimization level suggests that more FP8 was used in the LLM training process. Furthermore, their system offers FP8 low-bit parallelism, including tensor, pipeline, and sequence parallelism. It enables large-scale training, such as GPT-175B trained on thousands of GPUs, opening the door to next-generation low-precision parallel training.
It takes work to train LLMs with FP8. The difficulties arise from problems like data overflow or underflow, as well as quantization mistakes caused by the FP8 data formats’ decreased accuracy and smaller dynamic range. Throughout the training process, these difficulties lead to permanent divergences and numerical instabilities. To address these issues, they suggest two methods: automatic scaling to prevent information loss and precision decoupling to isolate the impact of data precision on parameters like weights, gradients, and optimizer states. The first method entails reducing precision for non-precision-sensitive components and preserving gradient values within the FP8 data format representation range by dynamically adjusting tensor scaling factors. This prevents underflow and overflow incidents during all-reduce communication.
They use the suggested FP8 low-precision framework for GPT-style model training, which includes supervised fine-tuning and pre-training, to verify it. Comparing their FP8 methodology to the widely used BF16 mixed-precision training approach, the experimental results show significant improvements, such as a 27% to 42% decrease in real memory usage and a noteworthy 63% to 65% decrease in weight gradient communication overhead. Both in pre-training and downstream tasks, the models trained with FP8 show performance parity to those utilizing BF16 high accuracy, without any adjustments to hyper-parameters such as learning rate and weight decay. During the GPT-175B model’s training, it is noteworthy that their FP8 mix-precision framework uses 21% less memory on the H100 GPU platform and saves 17% less training time than TE.
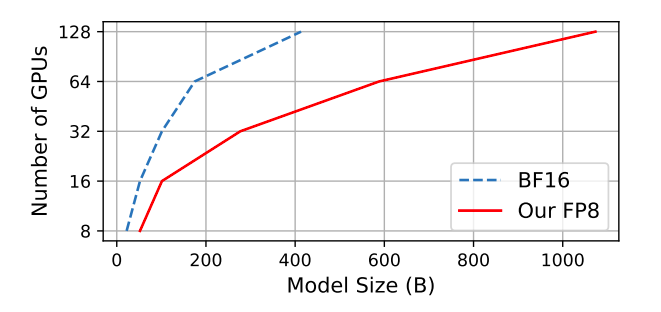
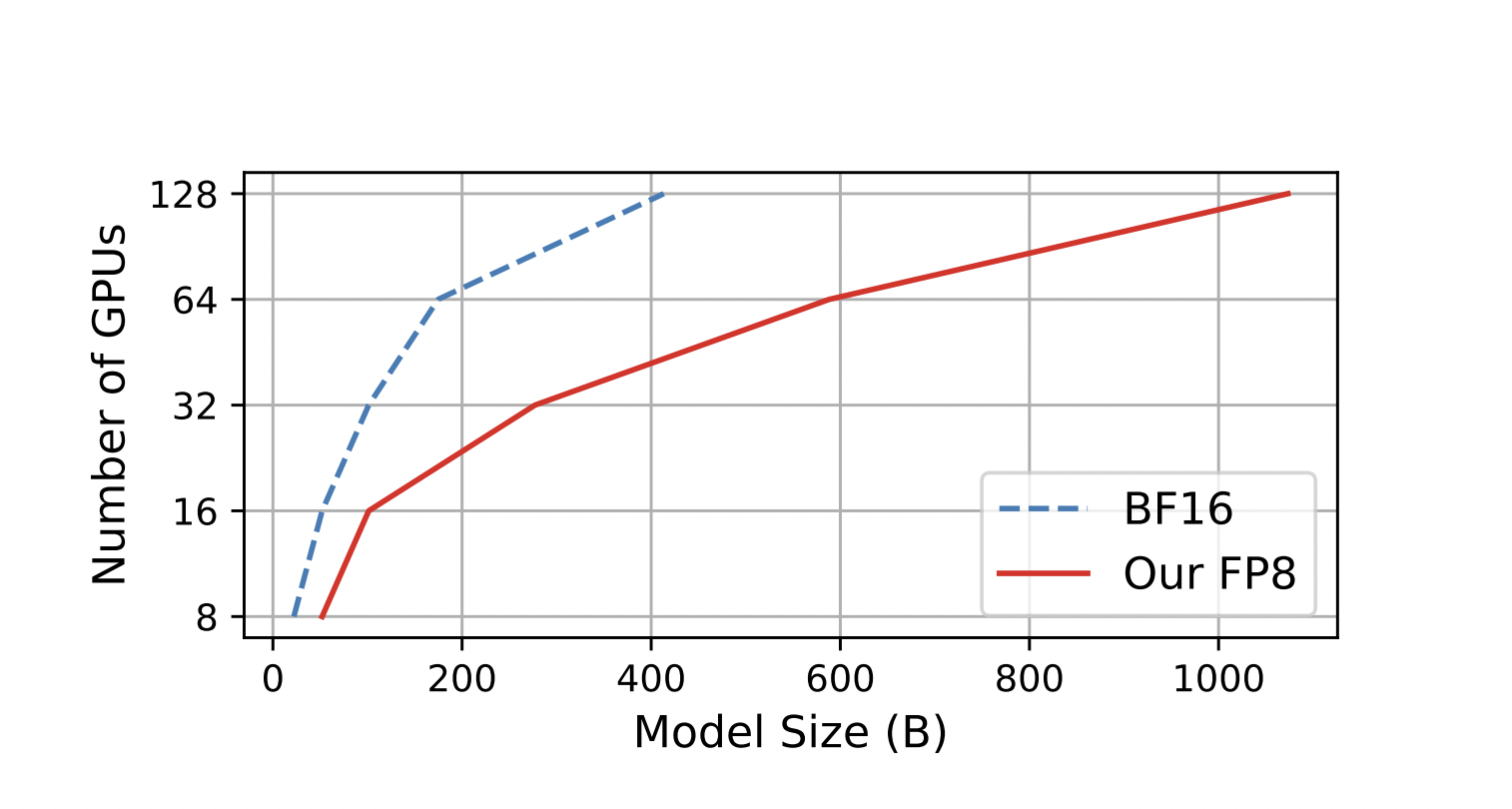
Figure 1: A comparison of the largest model sizes that may be achieved on a cluster of Nvidia H100 GPUs with 80G RAM by using our FP8 mixed-precision training method with the more popular BF16 method.
More significantly, when the scale of models increases, as seen in Fig. 1, the cost savings attained by using low-precision FP8 may be further enhanced. To better match pre-trained LLMs with end tasks and user preferences, they use FP8 mixed precision for instruction tweaking and reinforcement learning with human input. In particular, they employ publicly available user-shared instruction-following data to fine-tune pre-trained models. While obtaining 27% gains in training speed, the models adjusted with their FP8 mixed-precision perform similarly to those using the half-precision BF16 on the AlpacaEval and MT-Bench benchmarks. Additionally, FP8 mixed-precision shows significant promise in RLHF, a procedure that requires loading many models in training.
The popular RLHF framework AlpacaFarm may achieve a 46% decrease in model weights and a 62% reduction in optimizer states’ memory usage by using FP8 during training. This shows even more how flexible and adaptive their FP8 low-precision training architecture is. The following are the contributions they are making to further the development of FP8 low-precision training for LLMs in the future generation. • A fresh framework for mixed-precision training in FP8.It is easy to use and gradually unlocks 8-bit weights, gradients, optimizer, and distributed training in an add-on manner. The current 16/32-bit mixed-precision equivalents of this 8-bit framework may be easily swapped out for this one by just changing the hyper-parameters and training receipts. They also give an implementation for Pytorch that allows 8-bit low-precision training with just a few lines of code.
A fresh line of FP8-trained GPT-style models. They illustrate the proposed FP8 scheme’s capabilities across a range of model sizes, from 7B to 175B parameters, by applying it to GPT pretraining and fine-tuning. They provide FP8 supports (tensor, pipeline, and sequence parallelisms) to popular parallel computing paradigms, allowing FP8 to be used for training massive foundation models. The first FP8 GPT training codebase, which is based on the Megatron-LM implementation, is made publicly available. They anticipate that introducing their FP8 framework will provide a new standard for low-precision training systems geared at big foundation models in the future generation.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.