Microsoft’s Latest Machine Learning Research Introduces μTransfer: A New Technique That Can Tune The 6.7 Billion Parameter GPT-3 Model Using Only 7% Of The Pretraining Compute

Scientists conduct trial and error procedures which experimenting, that many times lear to freat scientific breakthroughs. Similarly, foundational research provides for developing large-scale AI systems theoretical insights that reduce the amount of trial and error required and can be very cost-effective.
Microsoft team tunes massive neural networks that are too expensive to train several times. For this, they employed a specific parameterization that maintains appropriate hyperparameters across varied model sizes. The used µ-Parametrization (or µP, pronounced “myu-P”) is a unique way to learn all features in the infinite-width limit. The researchers collaborated with the OpenAI team to test the method’s practical benefit on various realistic cases.
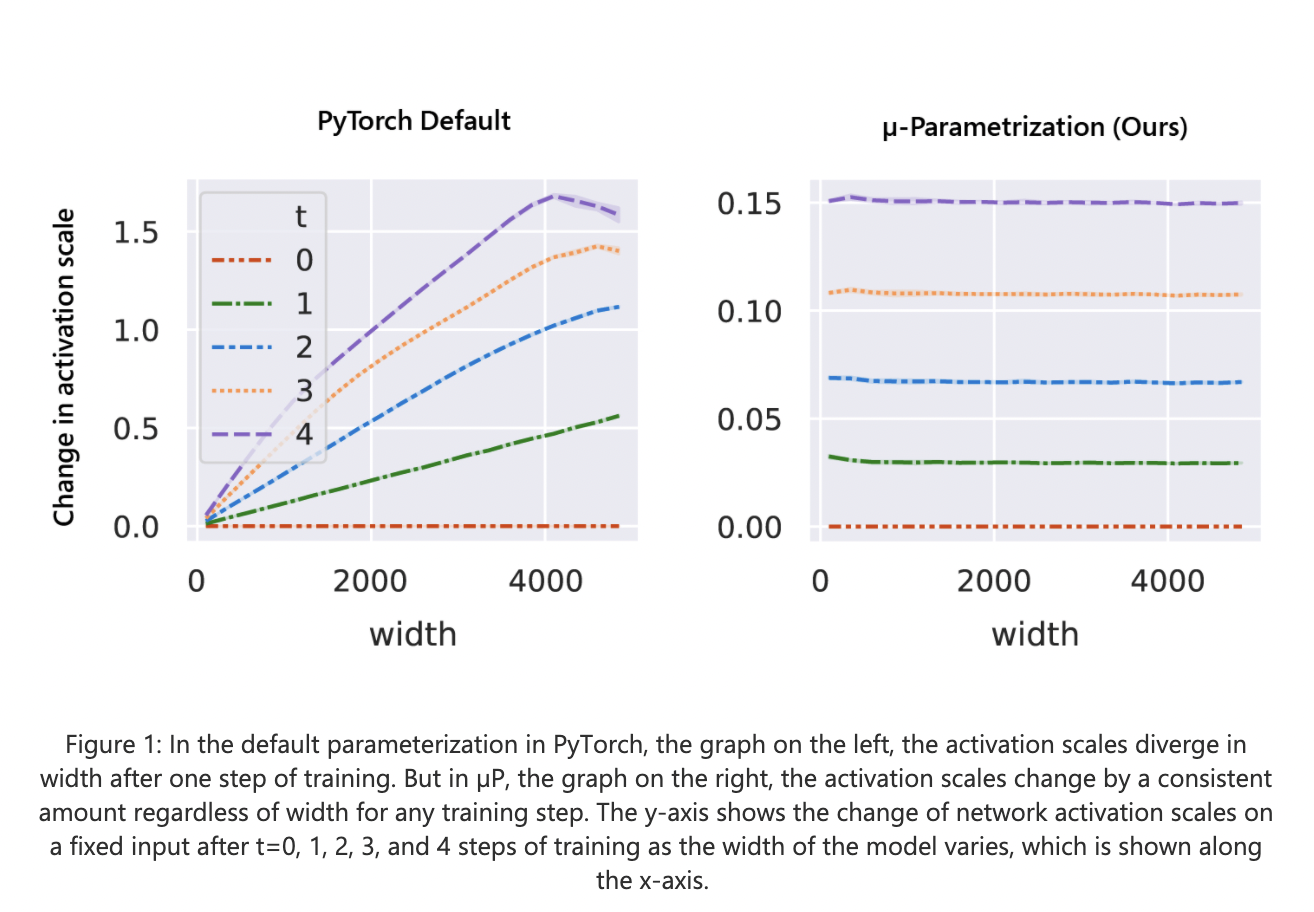
Studies have shown that training large neural networks because their behavior changes as they grow in size are uncertain. Many works suggest heuristics that attempt to maintain consistency in the activation scales at initialization. However, as training progresses, this uniformity breaks off at various model widths.
Further, training behavior is far more difficult to mathematically analyze. To minimize numerical overflow and underflow, the team aimed at achieving a comparable consistency so that as the model width grows, the change in activation scales during training remains consistent and similar to initialization.
Their parameterization ensures complete consistency during training. It is based on two key insights:
- When the width is large, gradient updates operate differently than random weights. This is due to the fact that gradient updates are based on data and include correlations, whereas random initializations do not. As a result, they must be scaled differently.
- When the width is big, the parameters of different forms respond differently. While the parameters are usually divided based on weights and biases, with the former being matrices and the latter being vectors, some weights behave like vectors in the large-width case.
These key insights led researchers to create µP that ensures that neural networks of diverse and sufficiently large widths behave similarly throughout training. This makes them converge to a desirable limit (feature learning limit) beyond just maintaining the activation scale consistent throughout training.
Their scaling theory allows the creation of a method for transferring training hyperparameters across model sizes. If µP networks of different widths have comparable training dynamics, they will likely have similar optimal hyperparameters. As a result, they should simply apply the best hyperparameters from a tiny model to a larger version. However, the findings show that P can accomplish the same result with no alternative initialization and learning rate scaling rule. This practical method is referred to as “µTransfer.”
They change the parameterization by interpolating between PyTorch default and µP’s initialization and learning rate scaling. µP achieves the best performance for the model. Also, broader models always perform better for a given learning rate.
µTransfer operates automatically for advanced designs such as Transformer and ResNet. It can also transfer a large number of hyperparameters at the same time. It is based on the theoretical underpinning of Tensor Programs. The notion of Tensor Programs (TPs) enables the researchers to compute the limit of any universal computing graph as its matrix dimensions get enormous, much as autograd enables practitioners to compute the gradient of any general computation graph. When applied to the underlying graphs for neural network initialization, training, and inference, the TP approach gives important theoretical conclusions.
Scaling modern neural networks needs a lot more than just width. The team also considers how P may be used in realistic training circumstances by combining it with basic heuristics for non-width dimensions.
The team combined the verified separate hyperparameters in a more realistic scenario. To directly tune it, they compared a µTransfer (which transfers tuned hyperparameters from a small proxy model to a large target model). In both cases, tuning is accomplished using a random search.
They compared the relative tuning compute budget to the tuned model quality (BLEU score) on the machine translation dataset IWSLT14 De-En. The results show that µTransfer is around an order of magnitude (in base 10) more compute-efficient for adjusting across all compute budget levels.
According to researchers, implementingµP (which enables µTransfer) from scratch can be difficult. To tackle this issue, they designed the mup package to enable practitioners to incorporate P into their own PyTorch models, just as frameworks like PyTorch, TensorFlow, and JAX have made autograd a given.
This new technique can speed up research on massive neural networks like GPT-3 and perhaps larger successors by drastically lowering the need to predict the training hyperparameters to utilize. The team believes that extensions of TP theory to depth, batch size, and other scale dimensions will be the key to the reliable scaling of huge models beyond width in the future.
The team has released a PyTorch package on the GitHub website that gives instructions to integrate their technology into existing models.
Paper: https://www.microsoft.com/en-us/research/uploads/prod/2021/11/TP5.pdf
Github:https://github.com/microsoft/mup
Reference: https://www.microsoft.com/en-us/research/blog/%C2%B5transfer-a-technique-for-hyperparameter-tuning-of-enormous-neural-networks/?OCID=msr_blog_enormousneuralnetworks_TW
Suggested
Credit: Source link
Comments are closed.