Microsoft’s New AI Model, VALL-E, Can Generate Speech From Text Using Only A Three-Second Audio Sample
Through the advancement of neural networks and end-to-end modeling, the field of voice synthesis has made significant strides during the past ten years. Currently, vocoders and acoustic models are frequently used in cascaded text-to-speech (TTS) systems, with mel spectrograms serving as the intermediate representations. Advanced TTS systems can synthesize high-quality speech from a single speaker or a group of speakers. However, they still need clean, high-quality data from the recording studio. Large amounts of Internet-crawled material cannot meet the criterion, which inevitably results in performance reduction. Because of the small training data, existing TTS systems still need better generalization.
In the zero-shot scenario, speaker resemblance and speech naturalness for unseen speakers substantially decrease. Existing research uses speaker adaption and speaker encoding techniques to address the zero-shot TTS issue, necessitating further fine-tuning, intricate pre-designed features, or significant structural engineering. The ideal strategy, inspired by the success in the field of text synthesis, is to train a model with huge and diverse data as much as possible instead of developing a sophisticated and particular network for this issue. The text language model’s performance has improved substantially recently, going from 16GB of uncompressed text to 160GB to 570GB, eventually, 1TB.
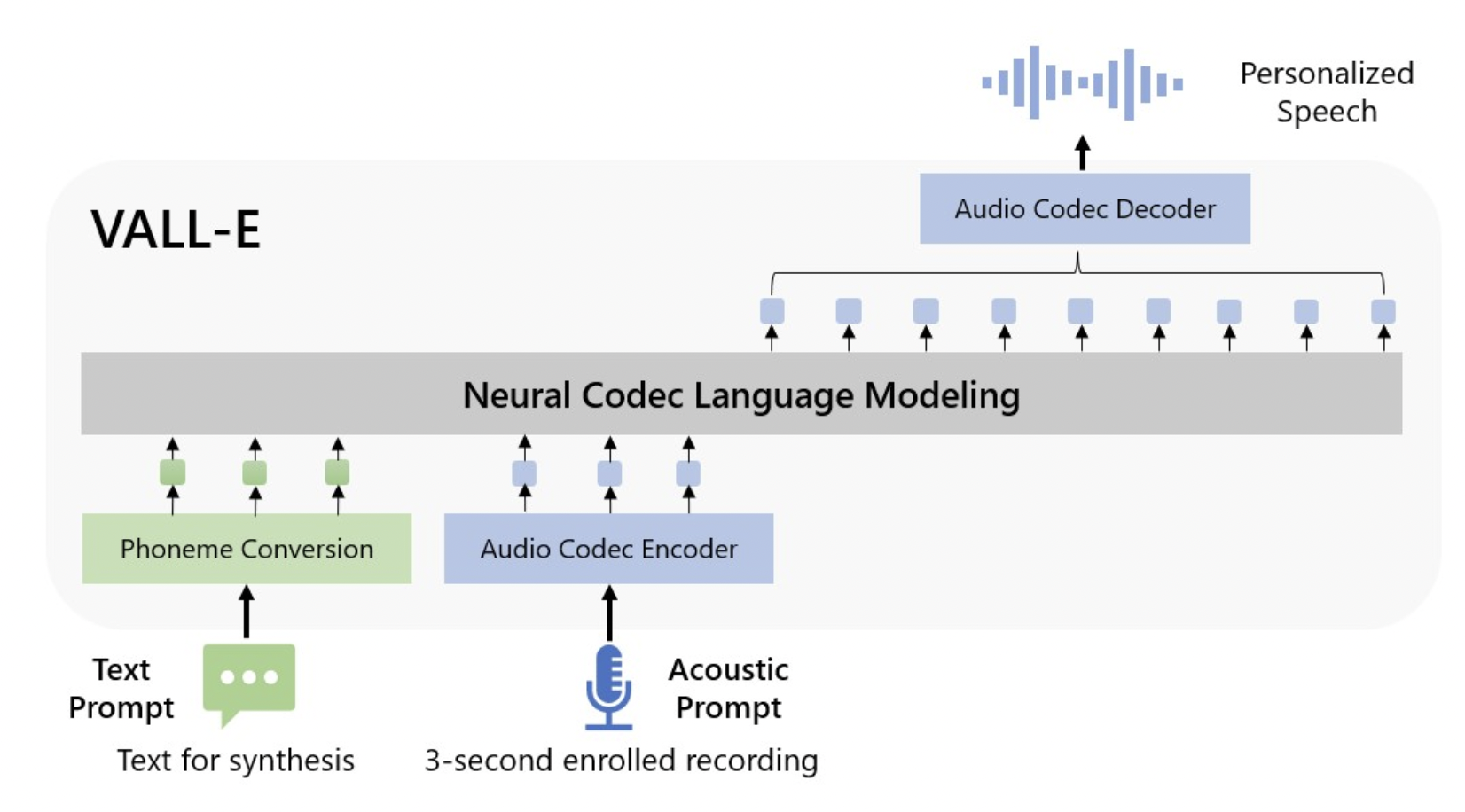
They introduce VALL-E, the first language model-based TTS framework utilizing the massive, varied, and multi-speaker voice data to transfer this accomplishment to the area of speech synthesis. As seen in the figure below, VALL-E creates the appropriate acoustic tokens conditioned on the acoustic tokens of the 3-second enrolled recording and the phoneme prompt, which confine the speaker and content information, respectively, to synthesize individualized speech (e.g., zero-shot TTS). The final waveform is synthesized using the produced acoustic tokens and the appropriate neural codec decoder. We may regard TTS as conditional codec language modeling thanks to the discrete acoustic tokens from an audio codec model. The TTS tasks can benefit from sophisticated prompting-based large-model techniques (as in GPTs).
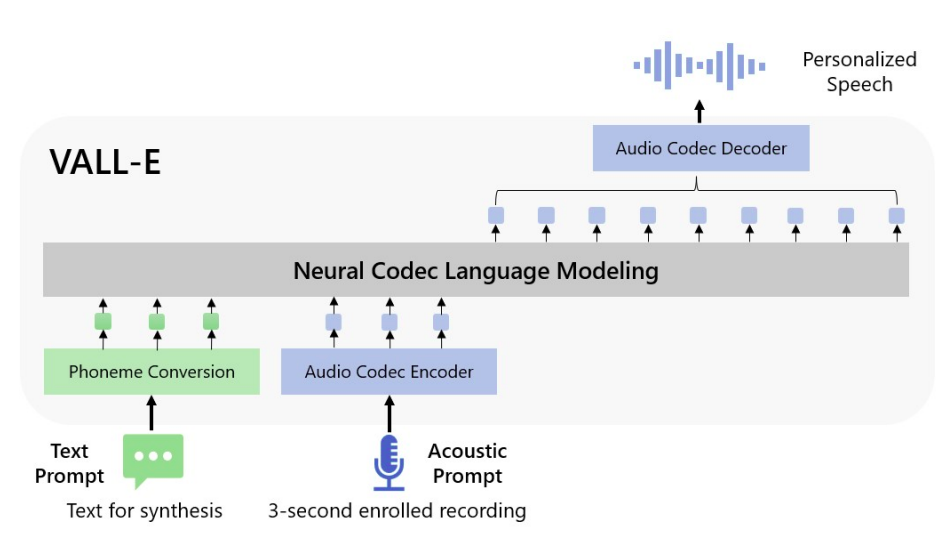
Based on phoneme and acoustic code cues that correlate to the target content and the speaker’s voice, VALL-E creates discrete audio codec codes. When paired with other generative AI models like GPT-3, VALL-E directly allows a variety of speech synthesis applications, including zero-shot TTS, voice editing, and content creation.
By utilizing various sampling techniques throughout the inference process, the acoustic tokens also enable us to provide a variety of synthesized outputs in TTS. LibriLight, a corpus of 60K hours of English speech from over 7000 distinct speakers, is used to train VALL-E. The transcriptions are produced using a speech recognition model because the original data was audio-only. Their collection has more loud speech and erroneous transcriptions than earlier TTS training datasets, like LibriTTS, but it also offers a variety of speakers and prosodies.
By utilizing vast data, they think the suggested technique is resilient to noise and generalizes well. It’s important to note that VALL-E is hundreds of times smaller than existing TTS systems, which are always trained with dozens of hours of single-speaker data or hundreds of hours of multi-speaker data. The originality of VALLE, a language model method for TTS, is outlined in Table 1. This technique uses intermediate representations such as audio codec codes and huge and diverse data sets to produce powerful in-context learning capabilities. All test speakers are hidden in the training corpus for the LibriSpeech and VCTK datasets, which are used to evaluate VALL-E.

Regarding speech naturalness and speaker similarity, VALL-E greatly surpasses the most advanced zero-shot TTS system, with improvements of +0.12 in the comparative mean option score (CMOS) and +0.93 in the parallel mean option score (SMOS) on LibriSpeech. Additionally, VALL-E outperforms the baseline on VCTK with increases of +0.11 SMOS and +0.23 CMOS. The synthetic voice of unseen speakers even achieved a +0.04 CMOS score versus ground truth, demonstrating that it is just as natural as human recordings on VCTK. Additionally, the qualitative analysis indicates that VALL-E can synthesize a variety of outputs from a single text and target speaker, which might be advantageous for creating pseudo-data for the voice recognition job.
Additionally, they discovered that VALL-E could preserve the acoustic cue’s acoustic context (such as reverberation) and mood (such as rage). In conclusion, they contribute the following.
• They suggest VALL-E, the first TTS framework with robust in-context learning capabilities as GPT-3, which approaches TTS as a language model job with audio codec codes acting as an intermediate representation in place of the conventional mel spectrogram. It allows prompt-based techniques for zero-shot TTS and has in-context learning capabilities. Thus unlike earlier work, it does not need extra structural engineering, pre-designed acoustic elements, or fine-tuning.
• They utilize a sizable quantity of semi-supervised data to develop a generic TTS system in the speaker dimension, indicating that the potential of semi-supervised data for TTS has been underutilized.
• They confirm that VALL-E synthesizes realistic speech with high speaker similarity by prompting in the zero-shot scenario and demonstrate that it can produce a variety of outputs from the same input text while maintaining the acoustic environment and the speaker’s mood of the acoustic prompt. According to evaluation results, VALL-E performs much better on LibriSpeech and VCTK than the most advanced zero-shot TTS system. Demos for the same are available on their website. People all over the internet are relating it to DALL-E. Image and Audio both are continuous signals and can be quantized into discrete tokens.
Check out the Paper, GitHub, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
What are your thoughts on VALL-E? Answer here
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.