Mimicking is the Way: Innovative AI Model Lets Robots Learn Tasks by Watching Human Videos
Robots are incredible. They have already revolutionized the way we live and work, and they still have the potential to do it again. They changed the way we live by doing mundane tasks for us, like vacuuming. Moreover, and more importantly, they changed the way we produce. Robots can perform complex tasks with speed, precision, and efficiency that far exceeds what humans are capable of.
Robots helped us to significantly increase productivity and output in industries such as manufacturing, logistics, and agriculture. As they continue to advance, we can expect them to become even more sophisticated and versatile. We will be able to use them to perform tasks that were previously thought impossible. For example, robots equipped with artificial intelligence and machine learning algorithms can now learn from their environment and adapt to new situations, making them even more useful in a wide range of applications.
However, robots are still expensive and fancy toys. Building them is one story, but teaching them to do something is often extremely time-consuming and requires extensive programming skills. Teaching robots how to perform manipulation tasks that are generally applicable with high efficiency has been a persistent challenge for a long time.
One approach to teaching robots efficiently is to use imitation learning. Imitation learning is a method of teaching robots how to perform tasks by imitating human demonstrations. Robots can observe and mimic human movements and then use that data to improve their own abilities. While recent advancements in imitation learning have shown promise, there are still significant obstacles to overcome.
Imitation learning is really useful to train robots to perform simple tasks such as opening a door or picking up a specific object, as these actions have a single goal, require short-horizon memory, and conditions usually do not change during the action. However, the issue arises when we change the task to a more complex one with varied initial and goal conditions.
The biggest challenge here is the time and labor required to collect long-horizon demonstrations. There are two main research directions to scale up imitation learning for more complex tasks; hierarchical imitation learning and learning from play data. Hierarchical imitation learning breaks down the learning process into high-level planners and low-level visuomotor controllers to increase sample efficiency and make it easier for robots to learn complex tasks.
On the other hand, learning from play data is about training robots using data collected from human-teleoperated robots interacting with the environment without specific task goals or guidance. This type of data is usually more diverse than task-oriented ones as they cover a wide range of behaviors and situations. However, collecting such play data can be costly.
These two approaches solve different problems, but we need something to combine them both. A way to utilize the efficiency of hierarchical imitation and effectiveness of learning from play data. Let us meet with MimicPlay.
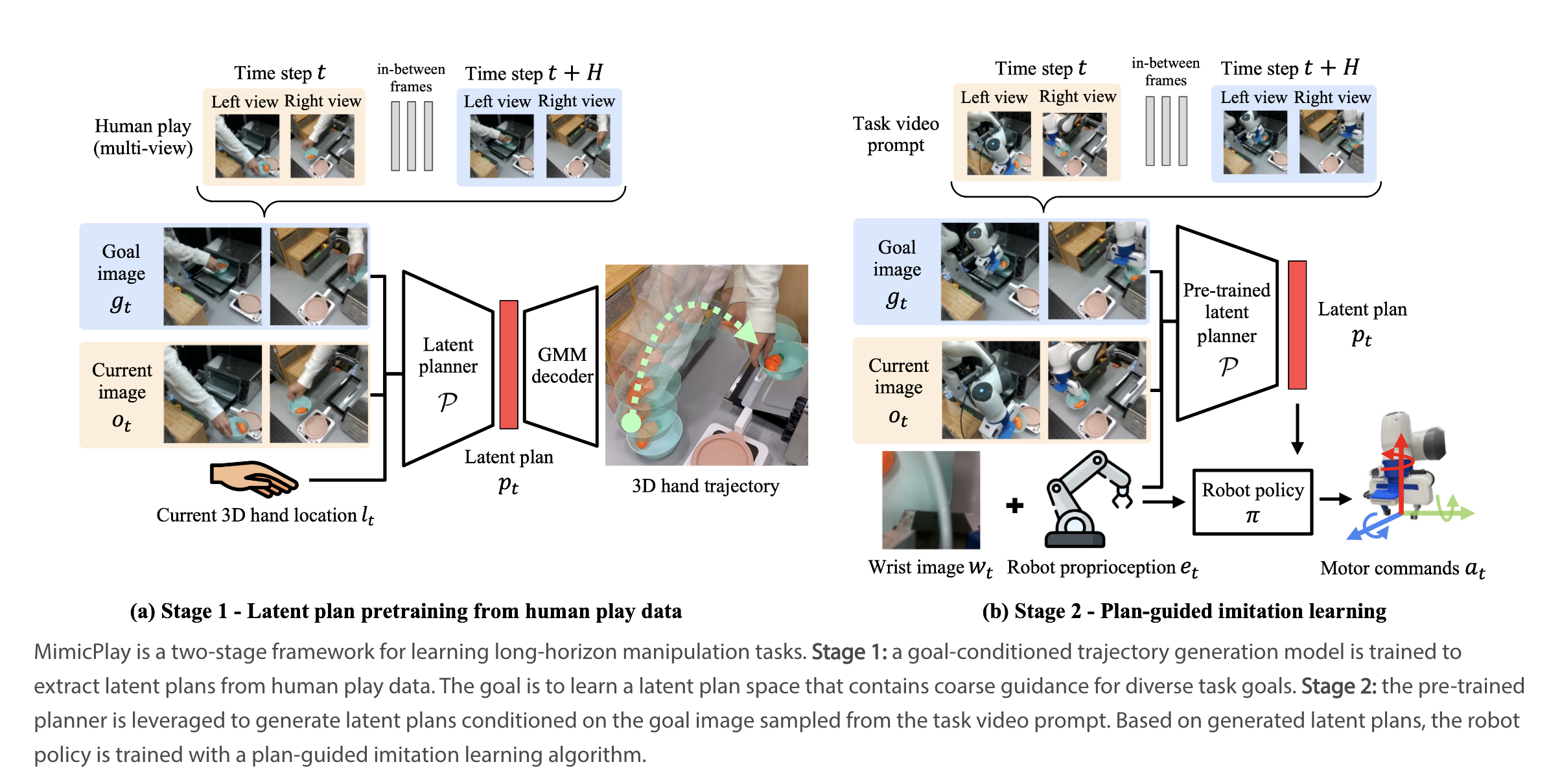
MimicPlay aims to enable robots to learn long-horizon manipulation tasks using a combination of human play data and demonstration data. A goal-conditioned latent planner is trained using human play data that predicts future human hand trajectories based on goal images. This plan provides coarse guidance at each time step, making it easier for the robot to generate guided motions and perform complex tasks. Once the plan is ready, the low-level controller incorporates state information to generate final actions.
MimicPlay is evaluated on 14 long-horizon manipulation tasks in six different environments, and it managed to significantly improve the performance over state-of-the-art imitation learning methods, especially in sample efficiency and generalization abilities. This means MimicPlay was able to teach the robot how to perform complex tasks more quickly and accurately while also managing to generalize this knowledge to new environments.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.