MIT AI Researchers Introduce ‘PARP’: A Method To Improve The Efficiency And Performance Of A Neural Network

Recent developments in machine learning have enabled automated speech-recognition technologies, such as Siri, to learn the world’s uncommon languages, which lack the enormous volume of transcribed speech required to train algorithms. However, these methods are frequently too complicated and costly to be broadly used.
Researchers from MIT, National Taiwan University, and the University of California, Santa Barbara, have developed a simple technique that minimizes the complexity of a sophisticated speech-learning model, allowing it to run more efficiently and achieve higher performance.
Their method entails deleting unneeded components from a standard but complex speech recognition model and then making slight tweaks to recognize a given language. Teaching this model an unusual language is a low-cost and time-efficient process because only minor adjustments are required once the larger model is trimmed down to size.
The researchers used Wave2vec 2.0, a sophisticated neural network that has been pretrained to learn basic speech from raw audio. Since it is a self-supervised learning model, it learns to recognize a spoken language after being fed a lot of unlabeled speech. Only a few minutes of transcribed speech are required for the training process. This opens up the possibility of voice recognition for rare languages with limited transcribed speech, such as Wolof, which 5 million people speak in West Africa.
However, because the neural network has around 300 million individual connections, training on a given language demands a lot of processing resources.
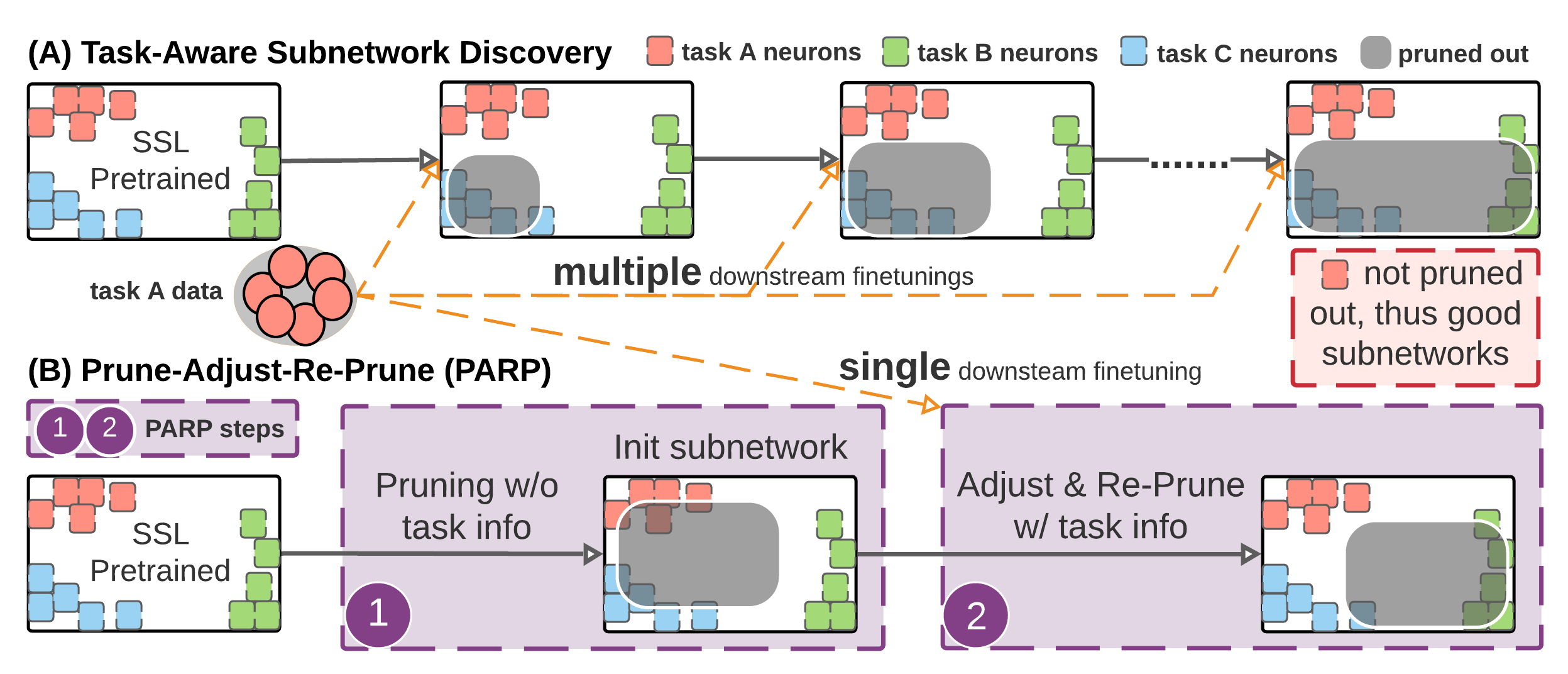
The researchers wanted to improve the network’s efficiency by pruning it. This involves eliminating connections that aren’t required for a given task, in this study, language learning. They trained the subnetwork with a limited amount of labeled Spanish audio and then again with French speech, a technique known as fine-tuning, after pruning the complete neural network to generate a smaller subnetwork.
Because these two models are fine-tuned for distinct languages, one would anticipate them to be highly different. Surprisingly, the researchers found that these models have remarkably comparable pruning patterns. There is a 97 percent overlap between French and Spanish.
They tested ten languages, ranging from Romance languages such as Italian and Spanish to languages with entirely distinct alphabets, such as Russian and Mandarin. The end result was the same: all of the fine-tuned models had a lot of overlap.
Inspired by their unique observation (Prune, Adjust, and Re-Prune), they suggest PARP (Prune-AdjustRe-Prune), a simple strategy to improve the efficiency and performance of the neural network.
A pretrained voice recognition neural network, such as Wave2vec 2.0, is pruned in the first stage by deleting superfluous connections. The resulting subnetwork is then tuned for a specific language and pruned again in the second stage. Connections that had been eliminated are permitted to develop again in this second step if they are essential for that language.
The model only needs to be fine-tuned once rather than several times. This is made possible because the connections are allowed to grow back during the second stage resulting in a significant reduction in computational power.
The researchers compared PARP to other popular trimming approaches and discovered that it surpassed them all in terms of voice recognition. According to findings, their approach worked very effectively when there was only a small amount of transcribed speech to train on.
The results also suggest that PARP can build a single smaller subnetwork that can be fine-tuned for ten languages at once, removing the need to prune separate subnetworks for each language and potentially lowering the cost and time required to train these models.
Because self-supervised learning (SSL) is transforming the field of voice processing, reducing the size of SSL models without sacrificing performance is a critical research direction. PARP achieves this breakthrough by reducing the size of the SSL models while also improving recognition accuracy. The researchers would like to employ PARP in text-to-speech models in the future and explore if their technique may increase the efficiency of other deep learning networks.
Paper: https://arxiv.org/pdf/2106.05933.pdf
Project: https://people.csail.mit.edu/clai24/parp/
Source: https://news.mit.edu/2021/speech-recognition-uncommon-languages-1104
Suggested
Credit: Source link
Comments are closed.