MIT Researchers Created a New Annotated Synthetic Dataset of Images that Depict a Wide Range of Scenarios to Help Machine-Learning Models Understand the Concepts in a Scene
Large-scale pre-trained Vision and language models have demonstrated remarkable performance in numerous applications, allowing for the replacement of a fixed set of supported classes with zero-shot open vocabulary reasoning over (nearly arbitrary) natural language queries. However, recent research has revealed a fundamental flaw in these models. For instance, their inability to comprehend Visual Language Concepts (VLC) that extend “beyond nouns,” such as the meaning of non-object words (e.g., attributes, actions, relations, states, etc.), or their difficulty with compositional reasoning, such as comprehending the significance of the word order in a sentence.
Vision and language models, powerful machine-learning algorithms that learn to match text with images, have demonstrated remarkable results when requested to generate video captions or summaries. While these models excel at distinguishing objects, they frequently need help comprehending concepts, such as the attributes of things or the arrangement of items in a scene. For example, a vision and language model may perceive the cup and table in an image but fail to comprehend that the cup is atop the table.
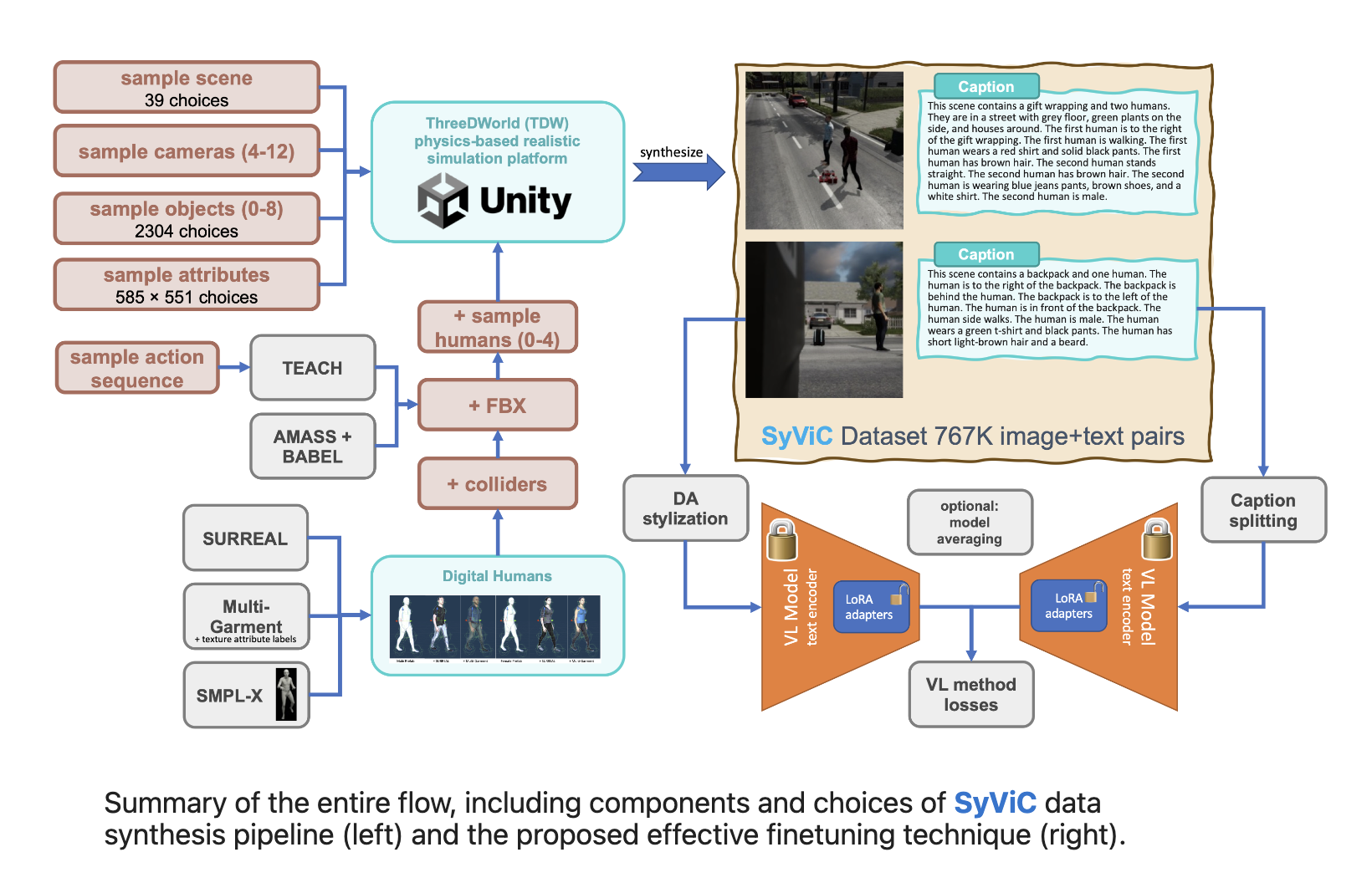
Researchers from MIT have demonstrated a new technique that employs computer-generated data to assist vision and language models in overcoming this deficiency. In particular, they propose enhancing the VLC and compositionality aspects of the generated visual and text data and then using these data to fine-tune VL models by instructing them to pay closer attention to these characteristics. Moreover, in addition to being essentially free and infinitely scalable, synthetic data can also be free of the privacy concerns that always accompany real data. Creating synthetic data that can be effectively used to enhance VLC and compositionality aspects of VL models pre-trained on massive amounts of real data presents additional technical challenges. In contrast to most prior work on generating synthetic visual data, they must develop images and text describing a scene’s compositional elements. In addition, they generate synthetic videos that utilize genuine physical 3D simulation, such as diverse 3D environments and diverse 3D objects, human motions, and action assets], added interaction with things, and various camera angles.
Previous works utilized motion assets to generate synthetic data, but the visual data was not accompanied by textual captions and needed to be designed with compositionality in mind. Researchers contribute to Synthetic Visual Concepts (SyViC), a large (million-scale) generated synthetic VL dataset with rich textual captions readily extendable via the data synthesis code and all previously generated million-scale synthetic data.
Making Contributions
- Researchers contribute SyViC – a million-scale synthetic dataset with rich textual annotations designed to enhance VLC comprehension and compositional reasoning in VL models, as well as the methodology and generation of codebase 2 for its synthesis and potential extensibility.
- Effective general VL model fine-tuning that leverages SyViC data to improve the characteristics of strong pre-trained VL models without compromising their zero-shot performance.
- Experimental results and a comprehensive ablation study demonstrate a significant (over 10% in some cases) improvement in VLC comprehension and compositional reasoning, as measured on the most recent VL-Checklist, ARO, and Winoground benchmarks and validated on the most popular CLIP model and its derivatives (e.g., the most recent CyCLIP.
The Results
Variants of all models were generated using the proposed method and SyViC synthetic data. Before fine-tuning on SyViC, each model is compared to its respective source model trained on large-scale real data. According to the findings of the researchers, both the SyViC synthetic data and the proposed fine-tuning recipe demonstrate significant enhancements over their respective source baselines. In addition, researchers illustrate the individual VLC metrics improvements acquired for CLIP in VL-Checklist and ARO benchmarks in showing up to 9.1% and 12.6% respective absolute improvements. This demonstrates the efficiency and potential of the method and SyViC synthetic data for enhancing VLC comprehension and compositional reasoning in VL models.
Try here https://synthetic-vic.github.io/
Limitations
While researchers have obtained quite promising results in three different benchmarks, there are limitations to their work. As an illustration, the graphics simulator has a simplified model of lighting, sensor noise, and reflectance functions compared to the actual world, which may affect color constancy robustness. More sophisticated domain adaptation and rendering techniques are likely required to enhance the outcomes further. In addition, a more in-depth examination of the scaling laws for synthetic data would be an excellent way to completely realize the work’s potential.
To summarize
Large vision and language models have dictated the status quo in computer vision and multimodal perception, achieving cutting-edge results in several difficult benchmarks. However, existing models need help with compositional reasoning and comprehending concepts beyond object nouns, such as attributes and relationships. This is the first investigation into whether synthetic data can mitigate these deficiencies. Researchers at MIT proposed a data generation pipeline to create a million-scale dataset of synthetic images and accompanying captions and an efficient fine-tuning strategy with a comprehensive analysis to improve the compositional and concept understanding capabilities of multimodal models without compromising their zero-shot classification performance.
Check out the Project Page and Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.