MIT Researchers Introduce A Novel Lightweight Multi-Scale Attention For On-Device Semantic Segmentation
The goal of semantic segmentation, a fundamental problem in computer vision, is to classify each pixel in the input image with a certain class. Autonomous driving, medical image processing, computational photography, etc., are just a few real-world contexts where semantic segmentation can be useful. Therefore, there is a high demand for installing SOTA semantic segmentation models on edge devices to benefit various consumers. However, SOTA semantic segmentation models have high processing requirements that edge devices cannot meet. This prevents these models from being used on edge devices. Semantic segmentation, in particular, is an example of a dense prediction task that necessitates high-resolution images and robust context information extraction capability. Therefore, transferring the effective model architecture used in image classification and applying it to semantic segmentation is inappropriate.
When asked to classify the millions of individual pixels in a high-resolution image, machine learning models face a formidable challenge. Recently, a highly effective use of a novel sort of model called a vision transformer has emerged.
The original intent of transformers was to improve the efficiency of NLP for languages. In such a setting, they tokenize the words in a sentence and create a network diagram that displays how those words are connected. The attention map enhances the model’s ability to comprehend context.
To generate an attention map, a vision transformer uses the same idea, slicing an image into patches of pixels and encoding each little patch into a token. The model employs a similarity function that learns the direct interaction between every pair of pixels to generate this attention map. By doing so, the model creates a “global receptive field,” allowing it to perceive all the important details in the image.
The attention map soon grows very large since a high-resolution image may include millions of pixels divided into thousands of patches. As a result, the computation required to process an image with increasing resolution climbs at a quadratic rate.
The MIT team replaced the nonlinear similarity function with a linear one to simplify the method used to construct the attention map in their new model series, dubbed EfficientViT. Because of this, the order in which operations are performed can be changed to reduce the number of calculations required without compromising functionality or the global receptive field, and with their approach, the amount of processing time needed to make a forecast scales linearly with the pixel count of the input image.
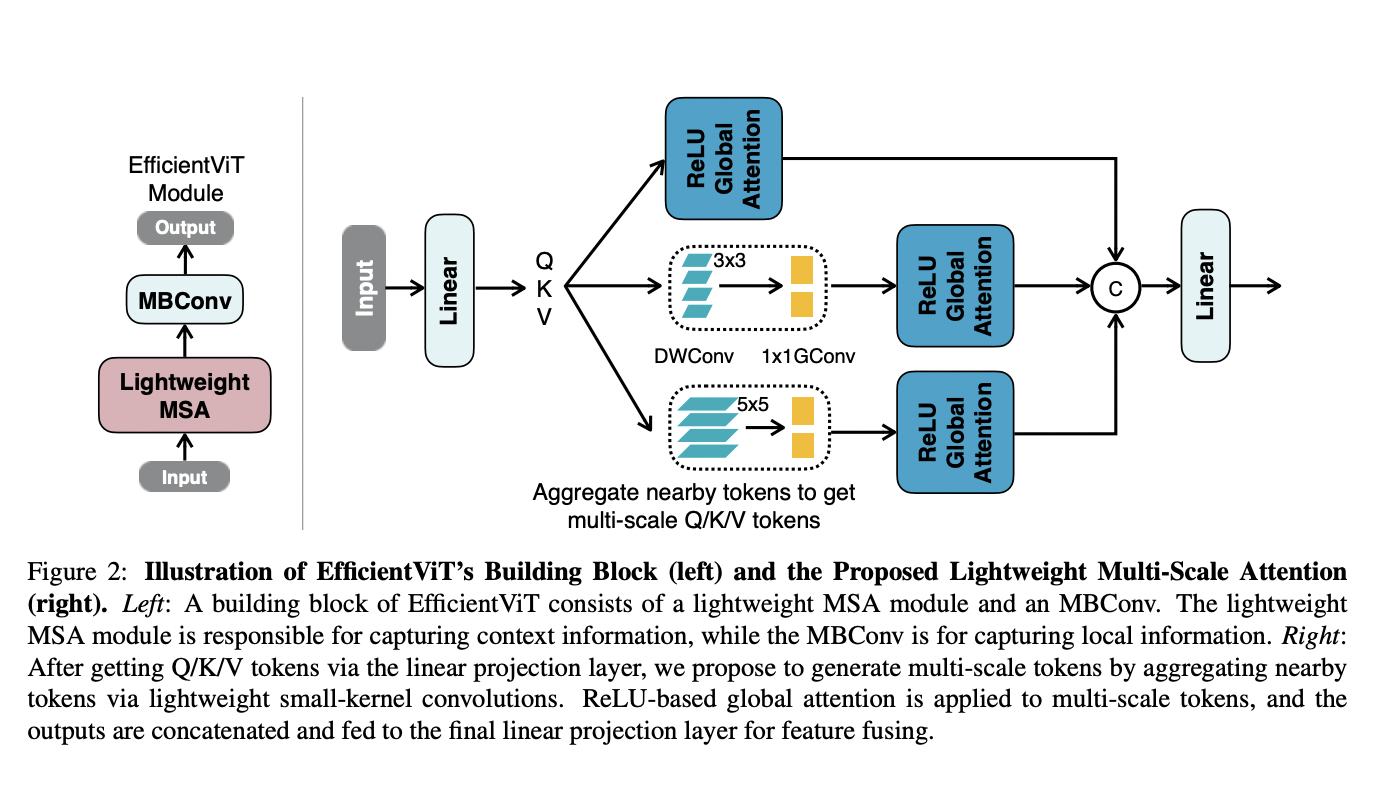
New models in the EfficientViT family do semantic segmentation locally on the device. EfficientViT is built around a novel lightweight multi-scale attention module for hardware-efficient global receptive field and multi-scale learning. Previous approaches for semantic segmentation in SOTA inspired this component.
The module was created to provide access to these two essential functionalities while minimizing the need for inefficient hardware operations. Specifically, we propose replacing the inefficient self-attention with lightweight ReLU-based global attention to achieve an international receptive field. The computational complexity of ReLU-based global attention can be reduced from quadratic to linear while keeping functionality by taking advantage of the associative property of matrix multiplication. And because it doesn’t use hardware-intensive algorithms like softmax, it’s better suited to on-device semantic segmentation.
Popular semantic segmentation benchmark datasets like Cityscapes and ADE20K have been used to conduct in-depth evaluations of EfficientViT. Compared to earlier SOTA semantic segmentation models, EfficientViT offers substantial performance improvements.
The following is a synopsis of the contributions:
- Researchers have developed a revolutionary lightweight multi-scale attention to do semantic segmentation locally on the device. It performs well on edge devices while implementing a global receptive field and multi-scale learning.
- Researchers developed a new family of models called EfficientViT based on the proposed lightweight multi-scale attention module.
- The model shows a significant speedup on mobile over previous SOTA semantic segmentation models on prominent semantic segmentation benchmark datasets like ImageNet.
In conclusion, MIT researchers introduced a lightweight multi-scale attention module that achieves a global receptive field and multi-scale learning with light and hardware-efficient operations, thus providing significant speedup on edge devices without performance loss compared to SOTA semantic segmentation models. The EfficientViT models will be further scaled up, and their potential for use in other vision tasks will be investigated in further research.
Check out the Paper and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.