MIT Researchers Introduce a Novel Machine Learning Approach in Developing Mini-GPTs via Contextual Pruning
In recent AI advancements, optimizing large language models (LLMs) has been the most pressing issue. These advanced AI models offer unprecedented capabilities in processing and understanding natural language, yet they come with significant drawbacks. The primary challenges include their immense size, high computational demands, and substantial energy requirements. These factors make LLMs costly to operate and limit their accessibility and practical application, particularly for organizations without extensive resources. There is a growing need for methods to streamline these models, making them more efficient without sacrificing performance.
The current landscape of LLM optimization involves various techniques, with model pruning standing out as a prominent method. Model pruning focuses on reducing the size of neural networks by removing weights that are deemed non-critical. The idea is to strip down the model to its essential components, reducing its complexity and operational demands. Model pruning addresses the challenges of high costs and latency associated with running large models.
Additionally, identifying trainable subnetworks within larger models, known as ‘lottery tickets,’ offers a path to achieving comparable accuracy with a significantly reduced model footprint.
The proposed solution by the MIT researchers is a novel technique called ‘contextual pruning,’ aimed at developing efficient Mini-GPTs. This approach tailors the pruning process to specific domains, such as law, healthcare, and finance. By analyzing and selectively removing weights less critical for certain domains, the method aims to maintain or enhance the model’s performance while drastically reducing its size and resource requirements. This targeted pruning strategy represents a significant leap forward in making LLMs more versatile and sustainable.
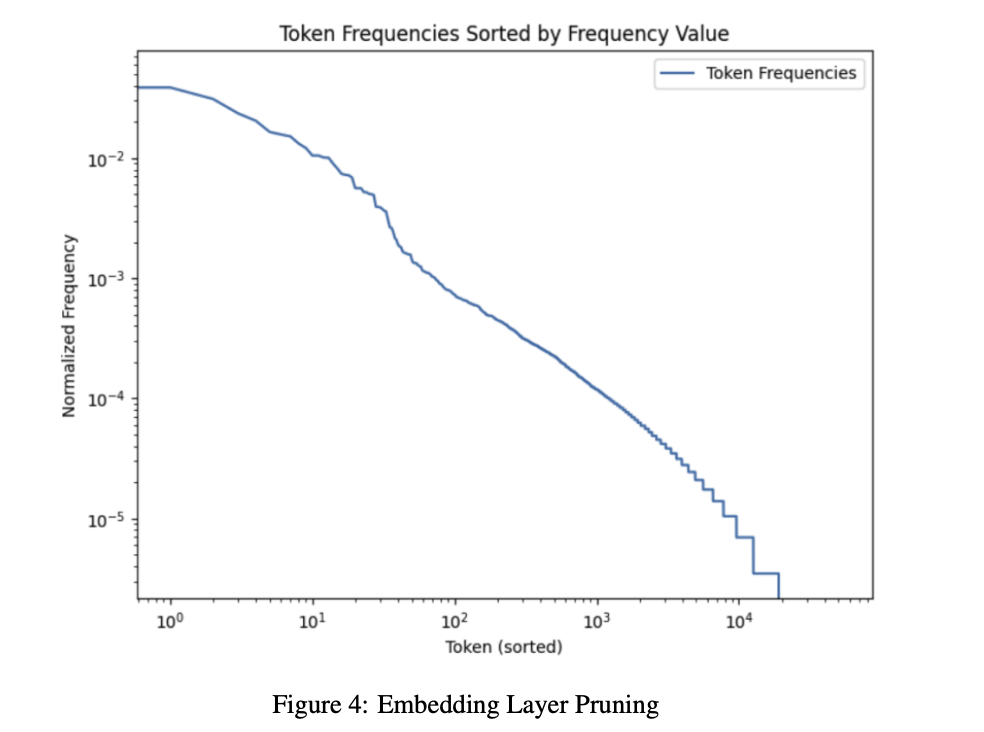
The methodology of contextual pruning involves meticulous analysis and pruning of linear layers, activation layers, and embedding layers in LLMs. The research team conducted comprehensive studies to identify less crucial weights for maintaining performance in different domains. This process included a multi-faceted pruning approach, targeting various model components to optimize efficiency.
The performance of Mini-GPTs post-contextual pruning was rigorously evaluated using metrics like perplexity and multiple-choice question testing. The promising results showed that the pruned models generally retained or improved their performance across various datasets after pruning and fine-tuning. These results indicate that the models preserved their core capabilities despite the reduction in size and complexity. In some instances, the pruned models even outperformed their unpruned counterparts in specific tasks, highlighting the effectiveness of contextual pruning.
In conclusion, this research marks a significant stride in optimizing LLMs for practical use. The development of Mini-GPTs through contextual pruning not only addresses the challenges of size and resource demands but also opens up new possibilities for applying LLMs in diverse domains. Future directions include refinement of pruning techniques, application to larger datasets, integration with other optimization methods, and exploration of newer model architectures. This research paves the way for more accessible, efficient, and versatile use of LLMs across various industries and applications.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.